对抗知识焦虑,从看懂这条开始
App 下载
只用数百条数据,编程智能体性能暴涨63%
STITCH方法|数据筛选机制|代码修复任务|编程智能体|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载STITCH方法|数据筛选机制|代码修复任务|编程智能体|AI智能体|人工智能
过去训练一个能写代码、修bug的AI智能体,得像攒考研资料一样,堆几十万条标注数据、几百万行代码案例——成本高不说,里面还混着大量无效的重复尝试、无意义的日志输出,就像在一堆碎纸里找有用的笔记。但2026年春天,有团队把这个逻辑彻底拧过来了:他们只用了不到1000条精选数据,就让AI在代码修复任务上的性能暴涨了63%。这不是靠堆更大的模型,而是靠一套能从海量垃圾里精准淘出黄金的筛选机制。
你可以把AI训练数据想象成刚从河里捞上来的金沙——大部分是泥沙,只有零星的金粒。过去的做法是把整筐泥沙都倒进熔炉,费力还炼不出多少纯金;而这套名为STITCH的框架,先做了两道精准筛选。
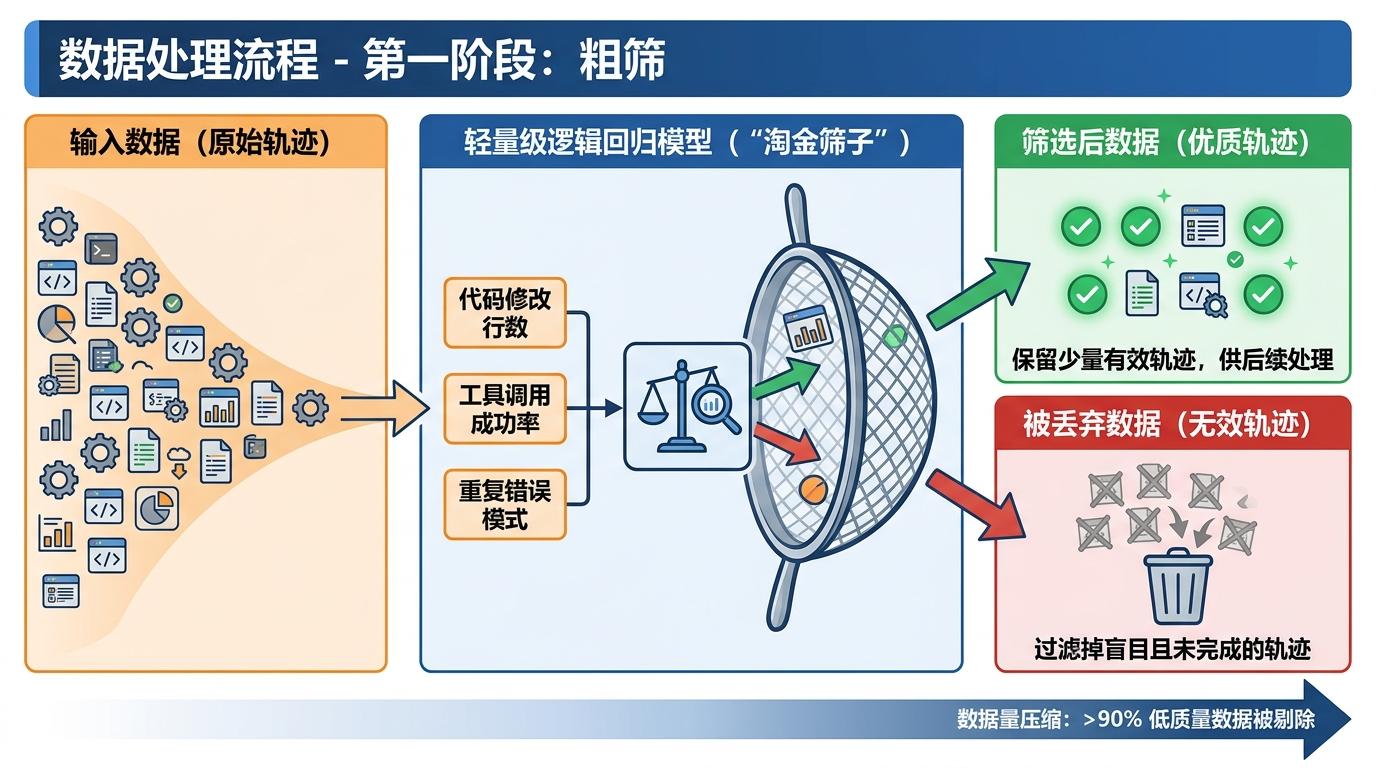
第一道是「粗筛」:用一个轻量的逻辑回归模型当「淘金筛子」,先看轨迹的统计特征——比如代码修改行数够不够多、工具调用成功率高不高、有没有反复犯同样的错误——几秒钟就能把那些全程瞎忙活、最后啥也没做成的无效轨迹扔出去。这一步能快速砍掉90%以上的低质量数据,把后续要处理的量压缩到原来的十分之一。
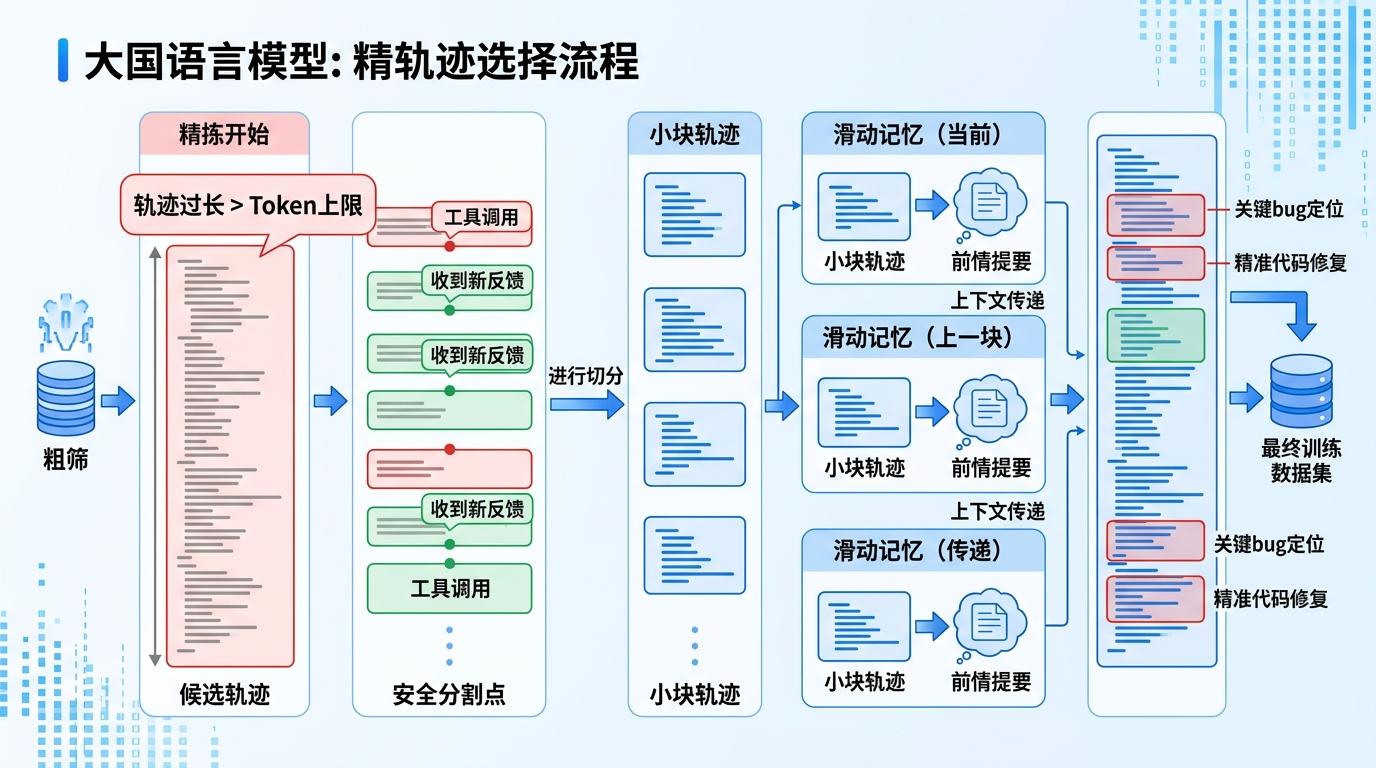
第二道是「精拣」:过了粗筛的候选轨迹,还要接受大语言模型的「显微镜检查」。但智能体的工作轨迹动辄几千个Token,大模型的上下文窗口装不下怎么办?研究者设计了「安全分割点」——比如每次工具调用结束、收到新反馈的节点,把长轨迹切成一个个语义完整的小块,再用「滑动记忆」传递上下文:每看完一块,就生成一段「前情提要」给下一块,保证不会断了逻辑链。最后把所有小块里最有价值的片段——比如关键的bug定位、精准的代码修复步骤——挑出来,组成最终的训练数据集。
这套方法的核心逻辑,是颠覆了AI训练的「规模迷信」。过去行业默认「数据越多模型越强」,但实际上,当数据里的噪声超过有效信号时,模型反而会被带偏——就像你背单词时混进一半错词,越背越乱。
STITCH的思路来自数学推理领域的LIMO研究:给模型看几百条逻辑严谨的解题步骤,比塞给它一万条凑数的题目效果更好。研究者把这个逻辑搬到了编程智能体上,发现只要基座模型已经具备基础的代码理解能力,少量高信号密度的数据就能「唤醒」它的潜力——那些关键的决策片段,就像给模型点透了「解题思路」,剩下的它自己就能举一反三。
实验数据最有说服力:在Python代码修复基准测试中,用不到1000条STITCH筛选的数据微调后,大模型的修复成功率从28.66%跳到了46.77%;在鸿蒙系统的ArkTS语言场景下,编译通过率直接从原来的水平提升了43%,连生成的界面都从粗糙的原型变成了符合规范的布局。而这一切,只需要传统训练数据量的几十分之一。
当然,STITCH也不是能解决所有问题的银弹。它的生效有三个前提:首先,基座模型本身得有足够的基础能力——如果一个模型连基本的代码语法都搞不懂,再优质的数据也救不了;其次,它目前只在编程智能体场景验证了效果,能不能推广到机器人控制、通用工具使用等其他智能体任务,还需要更多实验;最后,虽然筛选后的数据量少了,但精拣阶段需要调用大语言模型做语义分析,计算成本并没有完全消失,只是把成本从「数据采集」转移到了「数据筛选」上。
还有一个隐藏的局限:论文里用到的高质量原始轨迹,还是来自真实的GitHub问题和修复记录——如果某个领域没有这么多现成的高质量数据,这套方法的效果也会打折扣。未来要解决的,可能是如何自动生成高信号密度的训练数据,而不仅仅是筛选。
当大模型的参数规模逐渐摸到天花板,行业终于开始把目光从「堆规模」转向「提效率」。STITCH的意义,不在于它让某个模型的性能提升了多少,而在于它证明了:AI训练的未来,可能不是比谁的数据更多、模型更大,而是比谁更懂怎么用好数据。
「数据的价值不在数量,而在密度。」这句话正在从实验室的假说,变成能落地的工程方法。也许再过几年,当我们训练AI时,首先想到的不是「去哪找更多数据」,而是「怎么把手里的数据用到极致」。