对抗知识焦虑,从看懂这条开始
App 下载
AI注意力惊现偏见,简单修正竟提升剪枝可靠性?
曾丹团队|上海大学|剪枝方法|结构性偏置|注意力机制|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载曾丹团队|上海大学|剪枝方法|结构性偏置|注意力机制|大语言模型|人工智能
想象一位才华横溢的侦探,他能从纷繁复杂的线索中洞察真相。但他有一个奇怪的癖好:无论案情如何,他总是更关注最后进入现场的人,或是对房间角落里无意义的空白墙壁格外上心。这样的偏见,无疑会让他错失关键信息,甚至得出错误的结论。这听起来荒谬,但这正是当前许多顶尖人工智能(AI)模型正在上演的真实一幕。它们的核心机制——注意力(Attention),被发现存在着类似的结构性偏置,正在悄悄误导着它们的判断。
长期以来,我们理所当然地认为,AI的“注意力”就等同于“重要性”。模型关注哪里,就说明哪里是关键。然而,上海大学的曾丹团队联合南开大学的研究人员,通过一项系统性研究,揭示了这个普遍信念背后的“幻觉”。
在最新的研究中,他们发现,尤其是在处理图像和语言的多模态大模型(Vision-Language Models, VLMs)中,注意力机制并非一个纯粹的、客观的重要性指标。它像那位有偏见的侦探一样,受到两种与生俱来的结构性偏见影响:
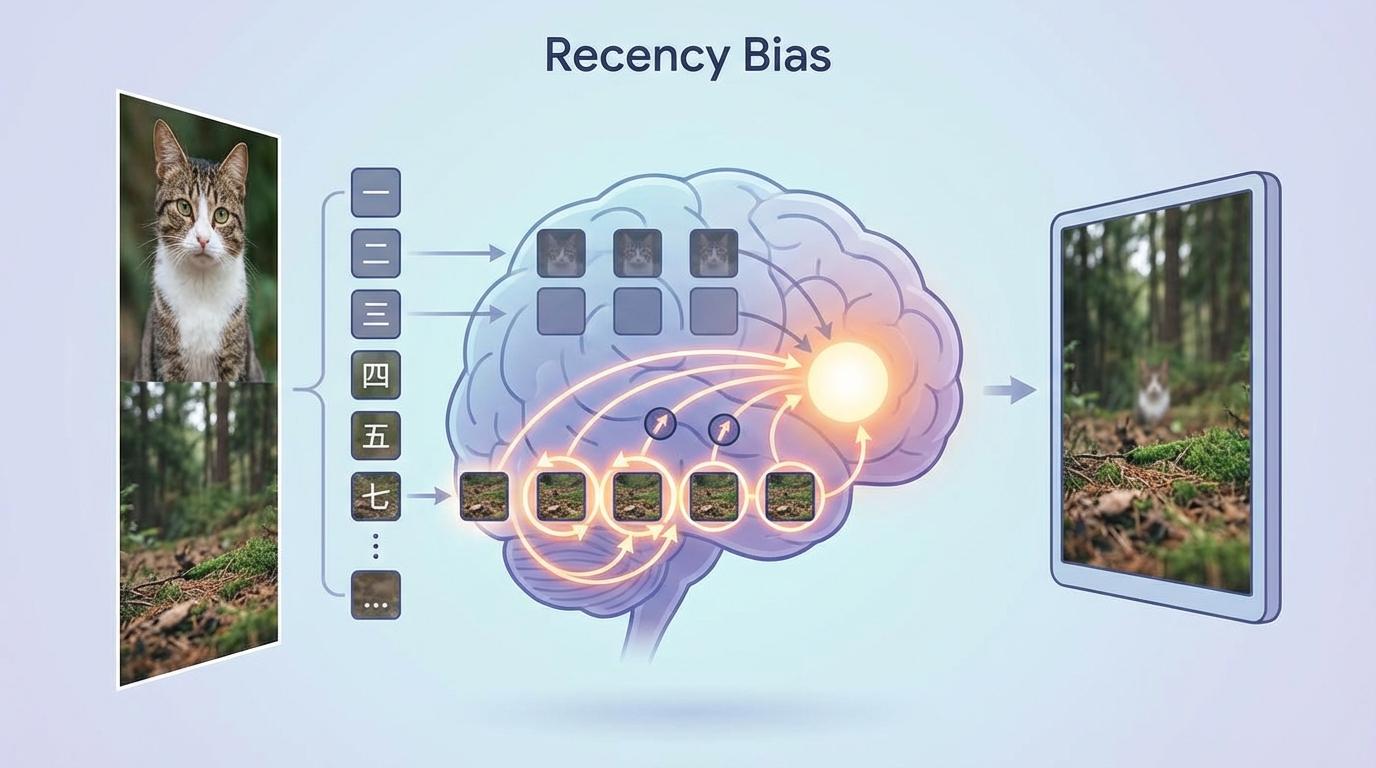
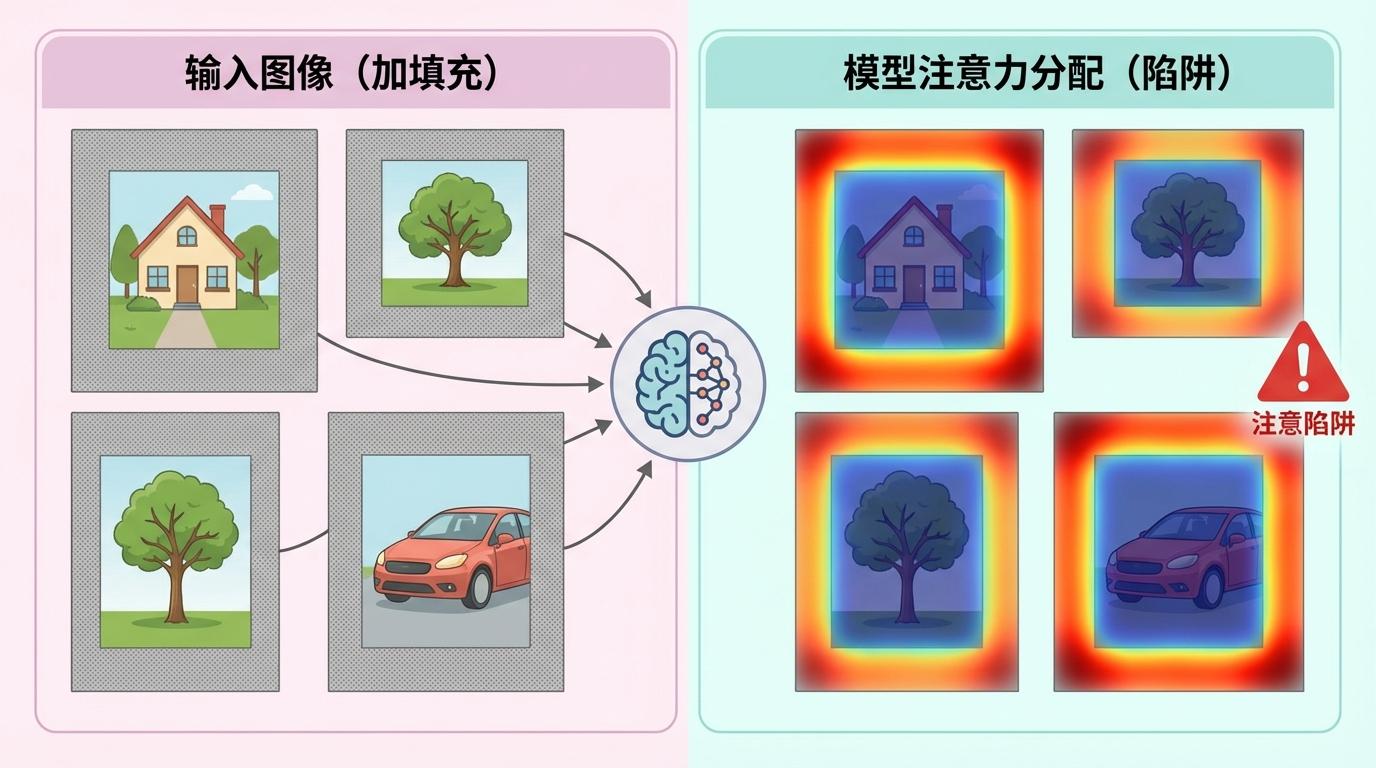
这些偏见在模型进行“剪枝”时会造成灾难性后果。为了让庞大的AI模型能在手机、汽车等设备上高效运行,研究者们会采用“视觉剪枝”技术,即丢弃不重要的视觉信息。但如果判断“重要性”的标尺(注意力)本身就是歪的,模型最终可能丢弃了关键的“猫”,却保留了无用的“草地”和“空白边框”。
面对这一困境,曾丹团队并未选择推倒重来,设计复杂的全新算法或对模型进行成本高昂的重新训练。他们另辟蹊径,提出了一种极为精巧、优雅的解决方案——注意力去偏(Attention Debiasing)。
他们的核心洞察是:这些偏见虽然存在,但并非随机噪声,而是呈现出稳定、可预测的整体趋势。基于此,他们的方法分为两步:
修正位置偏见:他们通过数学方法,拟合出一条能够反映“位置偏置”有多强的曲线。然后,在模型做出判断前,从原始的注意力分数中减去这条偏置曲线的影响。这就像给那位侦探戴上了一副特制的眼镜,可以自动校正他“只看最后”的习惯。
规避填充陷阱:在剪枝排序阶段,显式地抑制“填充”区域的注意力分数,确保这些无意义的空白区域不会进入“重要信息”的候选名单。
最关键的是,整个过程无需重新训练模型,可以作为一个“即插即用”的模块,无缝集成到现有的各种主流剪枝方法中,几乎没有增加任何计算成本。
这一看似简单的修正,却带来了惊人的效果。该团队将他们的“去偏”模块应用在6种主流的剪枝方法上,并在10个图像理解基准和3个视频理解基准上进行了全面测试,覆盖了LLaVA-7B/13B等多种行业领先模型。
实验结果显示,在几乎所有情况下,经过“去偏”处理的模型都获得了一致且稳定的性能提升。尤其是在剪枝更激进、信息更受限的“极限”条件下,提升效果尤为显著。这证明,校正了偏见后,模型在仅有少量信息的情况下,也能做出更可靠、更精准的判断。
通过可视化分析,对比更加直观。未经修正的剪枝模型,保留的视觉区域杂乱地分布在图像下方或边缘;而经过“去偏”修正后,模型保留的视觉区域则精准地聚焦在与问题相关的核心物体和关键细节上。这不仅提升了模型的性能,更重要的是,极大地增强了模型决策的可解释性——我们终于能更清晰地看到,AI是基于正确的信息在做判断。

这项研究的意义远不止于提升模型跑分。它为当前AI领域最核心的挑战之一——如何将庞大而强大的模型高效、可靠地部署到现实世界——提供了全新的思路。当AI需要进入我们的手机、智能家居和自动驾驶汽车时,它必须变得更轻、更快,同时不能牺牲可靠性。
曾丹团队的工作证明,我们不能盲目地信任AI的内部机制。深入理解并修正其固有的结构性缺陷,是通往真正可靠、可信AI的必经之路。它提醒我们,真正的智能,不仅在于拥有强大的能力,更在于能清醒地认识并校正自身的偏见。这或许是机器向人类智慧学习过程中,最重要的一课。