对抗知识焦虑,从看懂这条开始
App 下载
AI造世界的秘密:从画一张图到模拟整个时空
港科广清华联合综述|AI时空模拟|LAION-5B|2D到4D建模|虚拟世界生成|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载港科广清华联合综述|AI时空模拟|LAION-5B|2D到4D建模|虚拟世界生成|多模态视觉|人工智能
当你用AI生成一张赛博朋克城市的街景时,你可能没意识到——这只是AI“造世界”的第一步。现在,它已经能把这张静态图变成360°可漫游的3D街区,再让街上的行人走动、霓虹灯闪烁,甚至模拟一场突然的暴雨。近日,港科广、清华等6家机构联合发布的一篇综述,第一次把这些看似孤立的AI能力串成了一条完整的技术链:从2D到4D,AI正在一步步构建一个能感知、会变化、符合物理规律的虚拟世界。但这背后藏着一个反常识的真相:AI能模拟整个时空,居然全靠最基础的2D图像模型。
你可以把AI的“造世界”过程想象成一棵不断长高的树:2D图像生成是树根,它在LAION-5B这样的50亿级图文数据集里扎根,学会了识别所有视觉概念——从猫的花纹到赛博朋克的光影风格。视频生成是树干,它给树根添上时间维度,让静态的画面动起来,但必须解决“帧间闪烁”“人物变脸”的时序一致性问题。3D生成是树枝,它给树根添上空间维度,让平面的图像长出深度,变成能从任意角度观看的立体物体。而4D生成就是树冠,它同时拥有时间和空间维度,能创造出会动的3D场景——比如一辆在崎岖山路行驶的汽车,既要保证从前后左右看都是同一辆车,还要让它的颠簸符合物理规律。

这棵树的每一层都依赖下一层的养分:3D生成不用重新学习“什么是猫”,直接把2D模型里的猫的概念“抬升”到三维空间;4D生成也不用重新学习“猫怎么跑”,而是把3D的猫和视频里的运动规律结合起来。这种“维度生长”的框架,第一次打破了不同AI生成领域的壁垒。
这里藏着一个大多数人没注意到的关键:AI的“造世界”能力,其实被2D数据的规模死死卡住了。目前2D图文数据集的量级是50亿级,而3D领域最大的数据集只有1000万级,4D带标注的高质量数据更是几乎空白。这意味着,3D和4D模型根本不可能自己重新学习所有视觉概念——成本太高,数据也不够。
所以现在的技术路线非常清晰:3D和4D模型都在“借”2D模型的能力。比如3D生成模型会把2D图像模型当成“监督员”,从不同角度生成虚拟图像,让2D模型打分,直到所有角度的图像都符合2D模型的“审美”;4D生成模型则会把2D模型的语义和视频模型的运动、3D模型的几何结合起来。这就像盖高楼,2D模型是地基,地基越深,楼才能盖得越高。
但这种依赖也带来了问题:如果2D模型里有偏见,比如对某些人种的刻板印象,这些偏见会直接传递到3D和4D生成结果里。而且2D数据集里的版权、隐私问题,也会成为高维生成模型的隐形炸弹。
更有意思的是,这种“维度生长”不是单向的。高维模型的一致性约束,反而能反过来“教”低维模型变得更好。比如视频生成里的“人物变脸”问题,本质是因为2D模型没有“这是同一个人”的三维概念。而3D模型能提供严格的空间一致性约束,把这种约束当成“规则”注入视频生成模型,就能大幅减少变脸、闪烁的问题。
现在已经有研究团队在尝试这种“双向训练”:用4D模型的物理规律约束视频生成,让AI生成的视频不仅看起来真实,还符合物理常识——比如人跳起来会落地,杯子掉下去会破碎,而不是像现在某些AI视频那样,人物突然飘在空中。这种双向馈赠,正在让AI的“造世界”能力形成一个闭环:低维模型提供语义基础,高维模型提供物理和时空约束,两者互相促进。
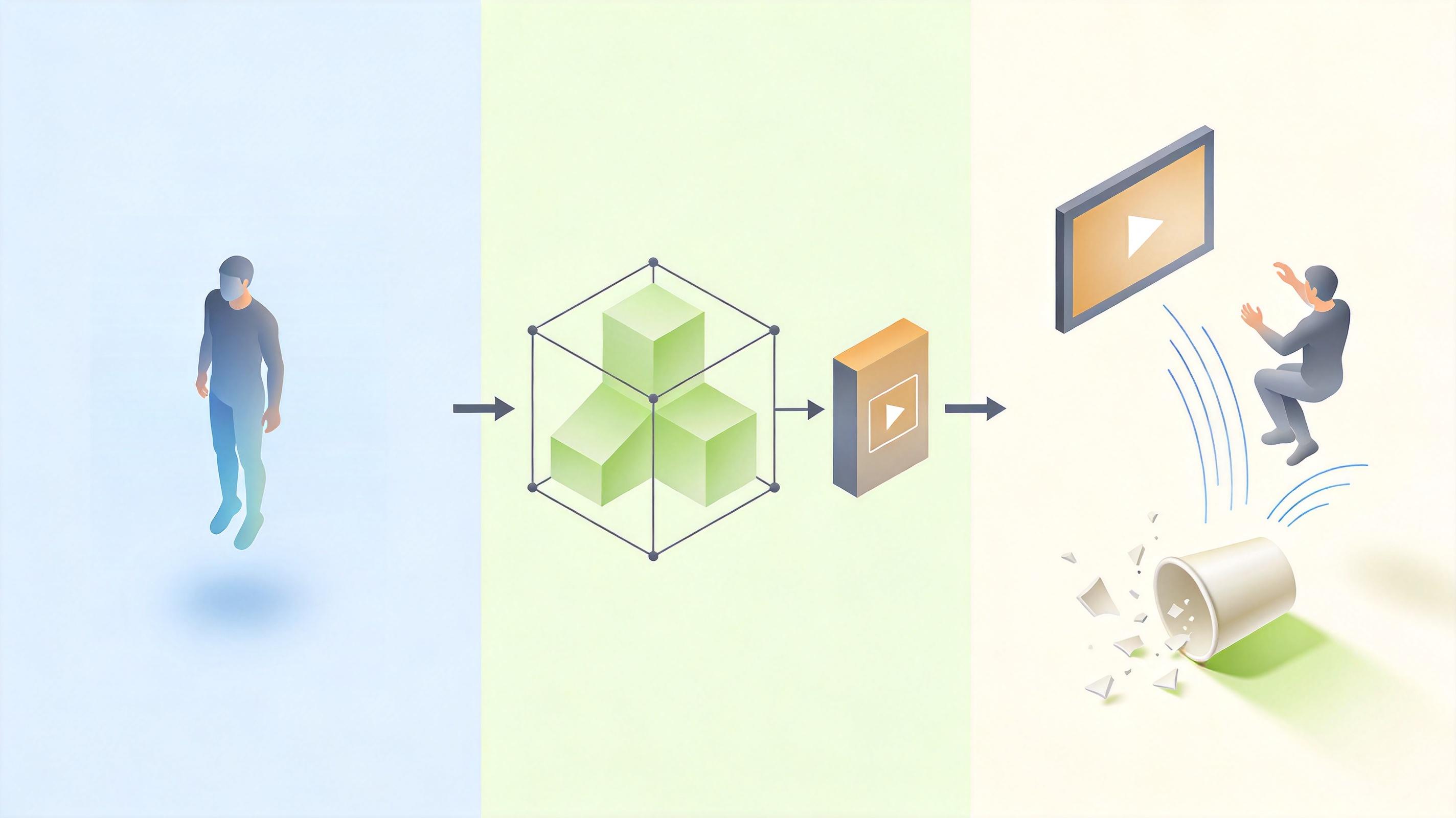
当然,这一切还面临着很多技术瓶颈:4D数据的稀缺、时空一致性的计算成本、物理规律的精准建模……比如现在的4D生成模型,还很难模拟复杂的物理交互,比如一杯水泼在地上的动态,或者两个物体碰撞后的形变。

当AI能生成一张逼真的图片时,我们惊叹于它的“创造力”;当它能生成一段连贯的视频时,我们惊叹于它的“想象力”;而当它能模拟一个完整的、符合物理规律的时空时,我们可能要开始重新思考:AI对世界的理解,已经到了什么程度?
从画一张图到模拟整个时空,AI的“维度生长”不仅是技术的升级,更是认知的跨越。它不再是简单的“生成内容”,而是在构建一个能反映现实世界规律的“数字孪生”。谁先打通从2D到4D的完整链路,谁就掌握了通向通用人工智能的关键钥匙——毕竟,理解世界的最好方式,就是自己创造一个世界。
高维生长,始于二维。