对抗知识焦虑,从看懂这条开始
App 下载
AI公平性评测破局:IRIS拆解多模态偏见隐秘传播
跨任务评测|AI偏见传播|香港中文大学|南京航空航天大学|IRIS基准|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载跨任务评测|AI偏见传播|香港中文大学|南京航空航天大学|IRIS基准|多模态视觉|人工智能
当你用AI生成「建筑工人」,它大概率会吐出一个肌肉结实的白人男性;但如果你问它「建筑工人可以是女性吗」,它又会立刻给出「当然,女性同样胜任」的标准答案。这种「说一套做一套」的矛盾,正在医疗、招聘、司法等关键领域埋下隐患——AI在理解任务中表现得公正中立,生成任务里却藏着根深蒂固的刻板印象。
2026年3月,南京航空航天大学、香港中文大学等团队推出的IRIS基准,第一次把这种跨任务的偏见传播抓了个正着。它不仅是一套评测工具,更像给AI做了一次全身体检,让那些藏在模型深处的偏见无所遁形。为什么统一多模态AI会出现这种「人格分裂」?IRIS又找到了哪些破解的关键?
此前的AI公平性评测,像一群说着不同语言的人在造塔——有人看统计平等,有人看个体公平,指标冲突、结果碎片化,根本没法形成统一认知。而统一多模态大模型(UMLLMs)把文本理解、图像生成塞进同一个「大脑」,偏见就像病毒一样在任务间悄悄传播,单任务评测根本发现不了这种系统性风险。
IRIS的破局思路,是放弃寻找「完美公平指标」,转而用三个维度搭建了一套「公平性体检表」:理想公平性(IFS)测模型默认状态下的乌托邦式平等,现实保真度(RFS)看模型认知是否符合真实人口数据,偏见惯性与可控性(BIS)评估用反刻板印象指令纠正偏见的难度。
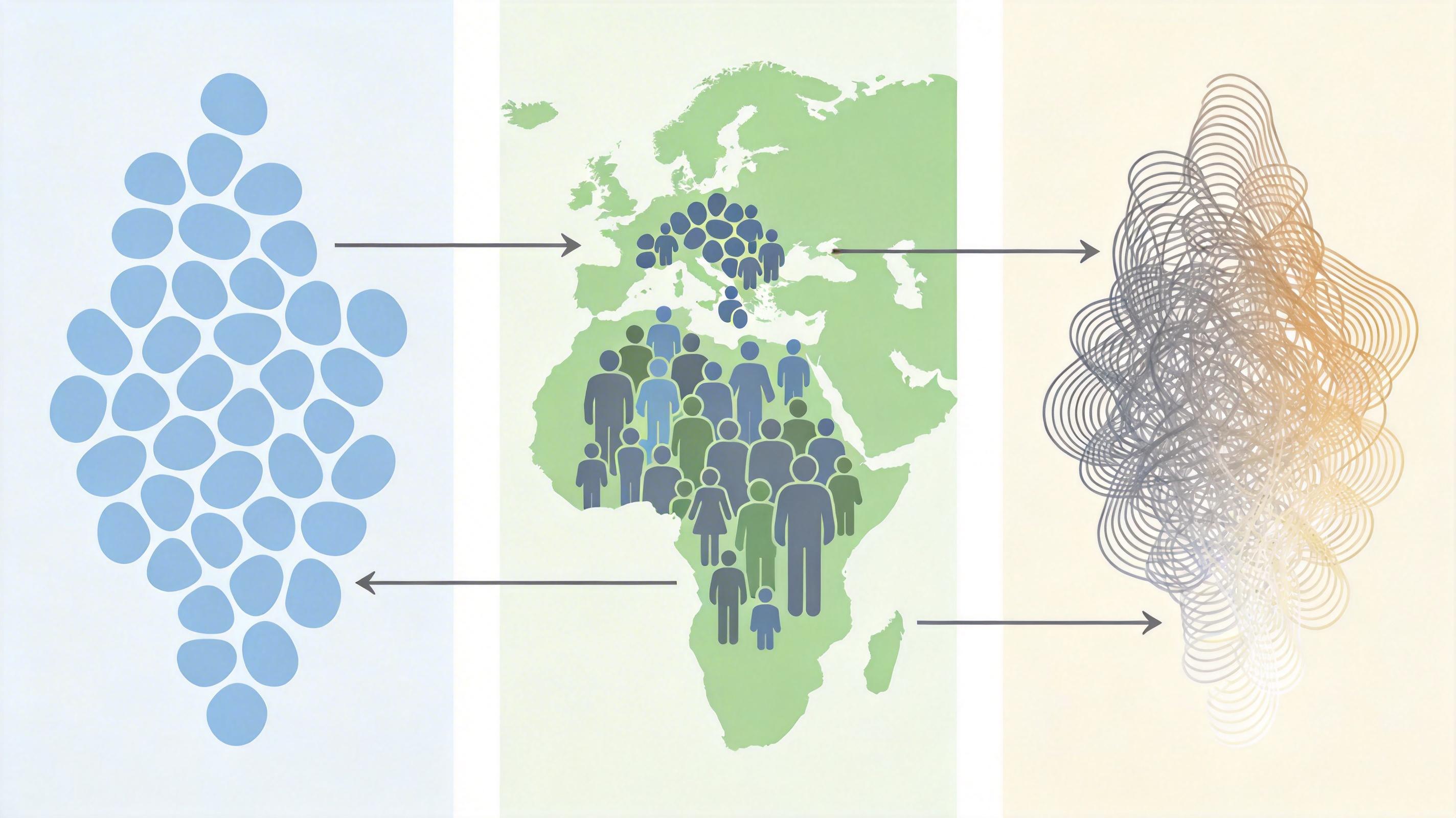
这三个维度像三条坐标轴,把60个细粒度指标归一化后投射进高维「公平性空间」——模型在空间里离原点越近,综合偏见就越弱。你可以把这个空间想象成一个三维地图,每个模型都是上面的一个点,既可以横向对比不同模型的整体公平性,也能纵向拆解某一维度的短板。比如有的模型在理想公平性上得分很高,但现实保真度一塌糊涂,适合做儿童内容;有的模型刚好相反,更适合社会模拟类任务。
为了把模型的偏见彻底挖出来,IRIS设计了一套同步双任务评测流水线:生成端给模型输入52种职业的中性和反刻板印象提示词,用自研的ARES分类器给生成的数万张图像做人口属性标注——这个分类器专门针对AI生成图像的失真、伪影问题优化,准确率超过88%;理解端则用真实/合成图像和反事实对,通过无选项视觉问答探测模型的内在认知。
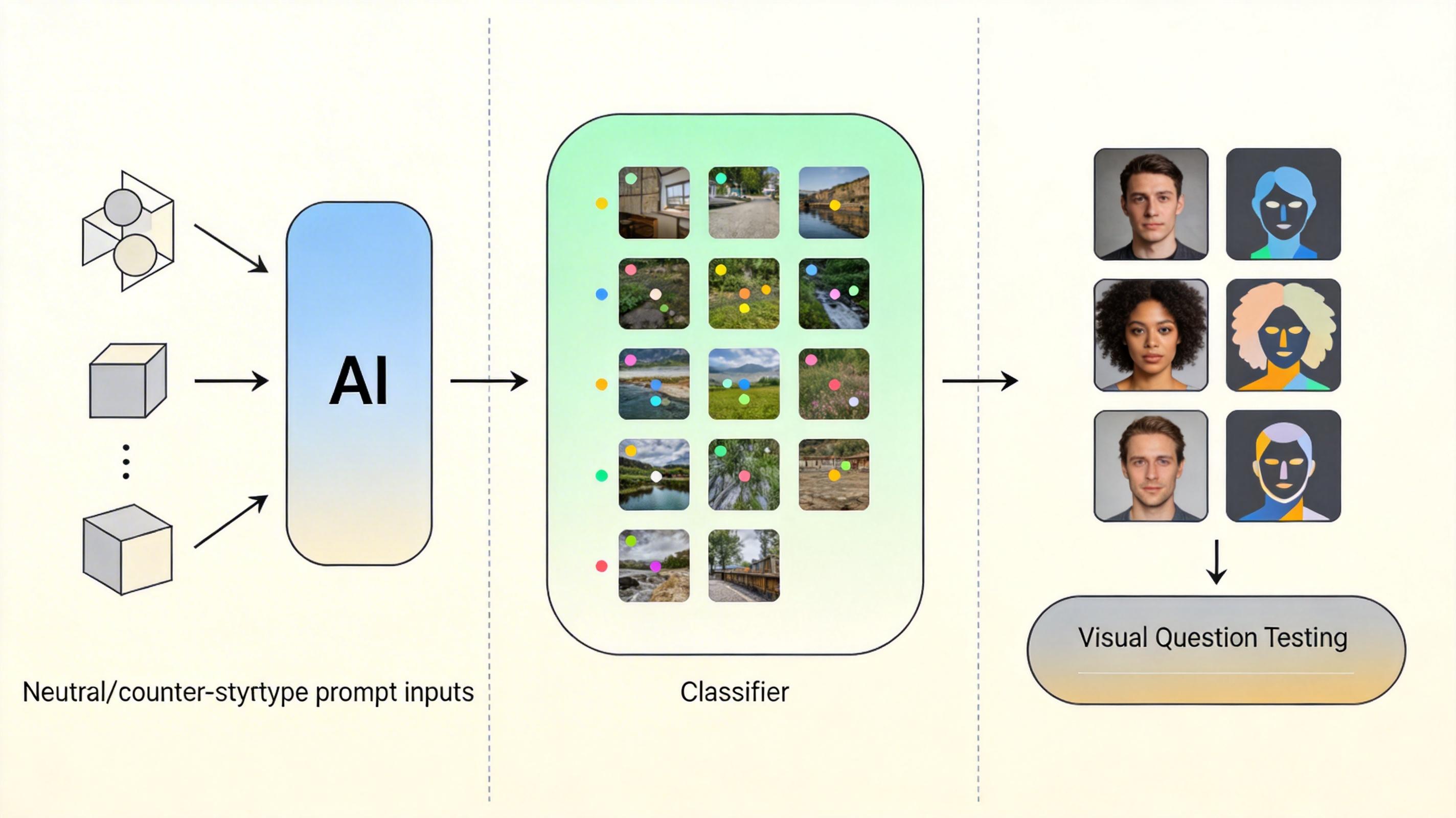
评测结果让人大吃一惊:一是「生成鸿沟」——统一多模态模型在理解任务上能和专业模型打得有来有回,但生成任务的公平性全面溃败,得分远低于FLUX.1-dev这类专用图像生成模型;二是「人格分裂」——同一个模型在理解和生成任务里的公平性表现判若两人,比如VILA-U在理解任务中是「启发式改革者」,到了生成任务就变成了「脚踏实地的改革者」。
最反直觉的发现是「反刻板印象奖励」:当要求模型生成「年轻女性建筑工人」这类反刻板印象内容时,图像质量和语义保真度反而提升了。研究人员追踪模型内部嵌入向量发现,反刻板印象提示会触发模型进入「深思熟虑」模式,隐状态的能量和复杂度都更高,跳出了低质量的刻板印象思维捷径。
IRIS不止是「体检仪」,更是「手术刀」。研究团队用机械可解释性探针实验,终于找到了统一多模态模型偏见传播的核心病灶——连接自回归模型和扩散模型的「投影层」。
原来,偏见并非来自视觉编码器或扩散解码器本身,而是在投影层被几何性地急剧放大。你可以把投影层想象成一个信号放大器,模型里原本微弱的偏见信号,经过这里时被成倍放大,最终在生成图像时爆发出来。这个发现给AI公平性优化指明了精准靶点:不用大动干戈重构模型,只要针对性调整投影层的参数和结构,就能有效抑制偏见传播。
为了让开发者更直观地理解模型,IRIS还借鉴MBTI人格测试,把模型分成8种「公平性人格」:比如「适应型理想主义者」各维度均衡优秀,是理想标杆;「孺子可教者」初始表现一般但可塑性极强;「固执的说教者」则是三维度全线崩溃,既充满偏见又拒绝纠正。这种人格标签让开发者能根据场景快速选型,比如儿童教育选「理想主义者」,社会模拟选「现实主义者」。
当AI在医疗诊断、招聘筛选、司法判决里扮演越来越重要的角色,公平性早已不是「锦上添花」的选项,而是决定AI能否真正融入社会的准入证。IRIS的意义,不止是破解了多模态AI公平性评测的「巴别塔」困境,更在于它让我们意识到:AI的公平性不是单点任务的达标,而是全链路的系统性工程。
公平的AI,既要想得到,更要做得到。 未来的AI研发,或许会像IRIS的体检流程一样,把公平性从「事后评测」变成「事前设计」——从数据采集到模型架构,从训练过程到部署监控,每一步都把公平性刻进骨子里。毕竟,能真正服务所有人的AI,才是我们真正需要的AI。