对抗知识焦虑,从看懂这条开始
App 下载
AI agent省10倍token的秘密:给信息做减法
决策效率|GitHub开源项目|上下文窗口|token消耗优化|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载决策效率|GitHub开源项目|上下文窗口|token消耗优化|AI智能体|人工智能
当你给AI发一句“Hello”,后台可能已经悄悄烧掉了上万token——这是如今多数自主Agent的通病:装的技能越多越卡,上下文越长越容易“失忆”,每一次对话都像重新启动。但最近有个框架只用3000行代码、9个工具,就把同样任务的token消耗砍到了原来的1/10,半个月狂揽5000星登顶GitHub趋势榜。它没有堆参数加功能,只靠一条反常识的原则:不追求上下文够长,只追求每个token都在为当下决策干活。这到底是怎么做到的?
你可以把Agent的上下文窗口想象成一个背包——传统Agent总喜欢往里面塞尽可能多的工具、历史对话和技能说明,结果背包越来越重,找东西的时间比干活还长,最后连最基础的任务都卡壳。而这个叫Generic Agent(GA)的框架,做的第一件事就是给背包减负:把原来20个重叠的技能砍到9个“原子工具”,每个工具只负责最核心的功能,比如文件操作、代码执行、网页交互,没有一点冗余。
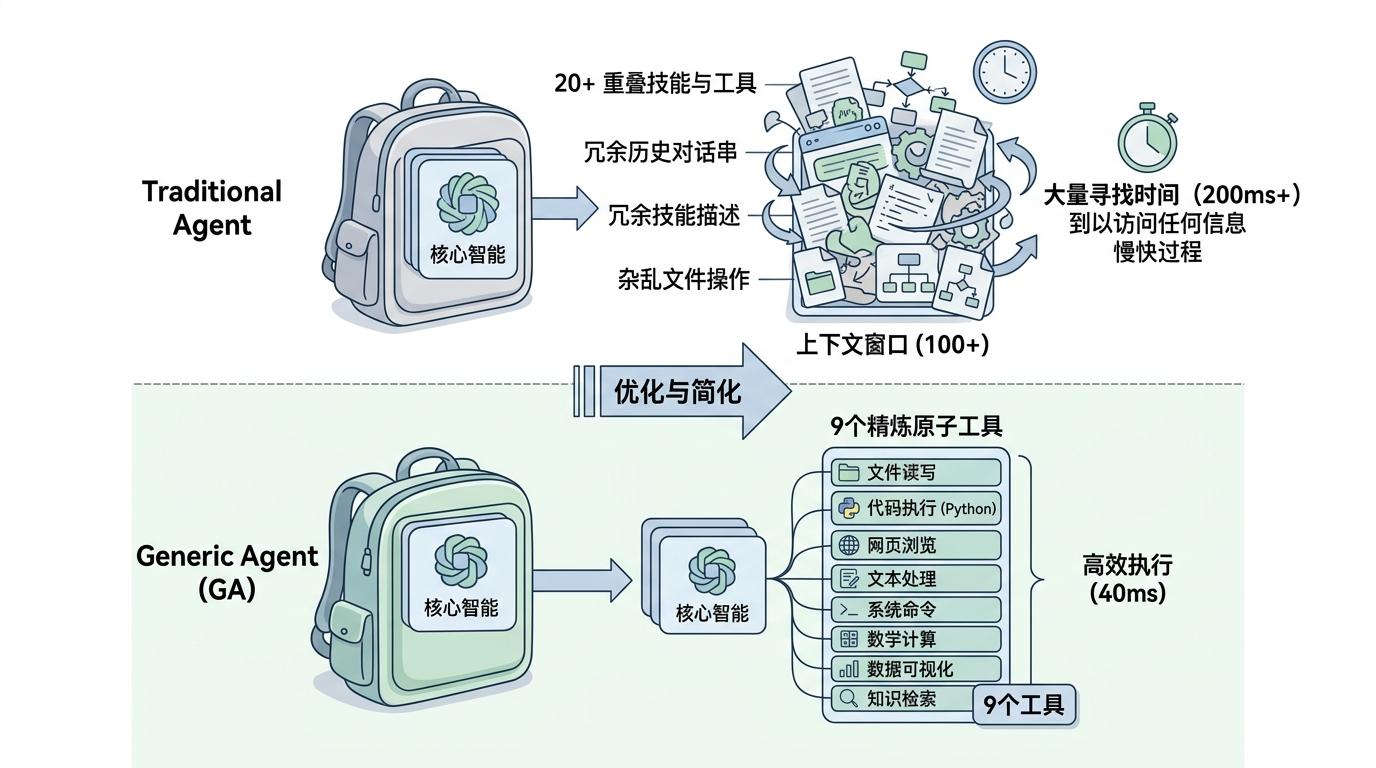
它的核心逻辑是“上下文信息密度最大化”——每一个token都必须直接服务于当前决策,没用的信息坚决不进上下文。比如传统Agent会把所有技能的完整说明都塞进上下文,而GA只在需要调用某个工具时,才把对应的极简描述传进去;别人的对话历史会完整保留,GA则会自动压缩成结构化的关键信息,比如“用户昨天要求统计Q3销售额”,而非整段对话。
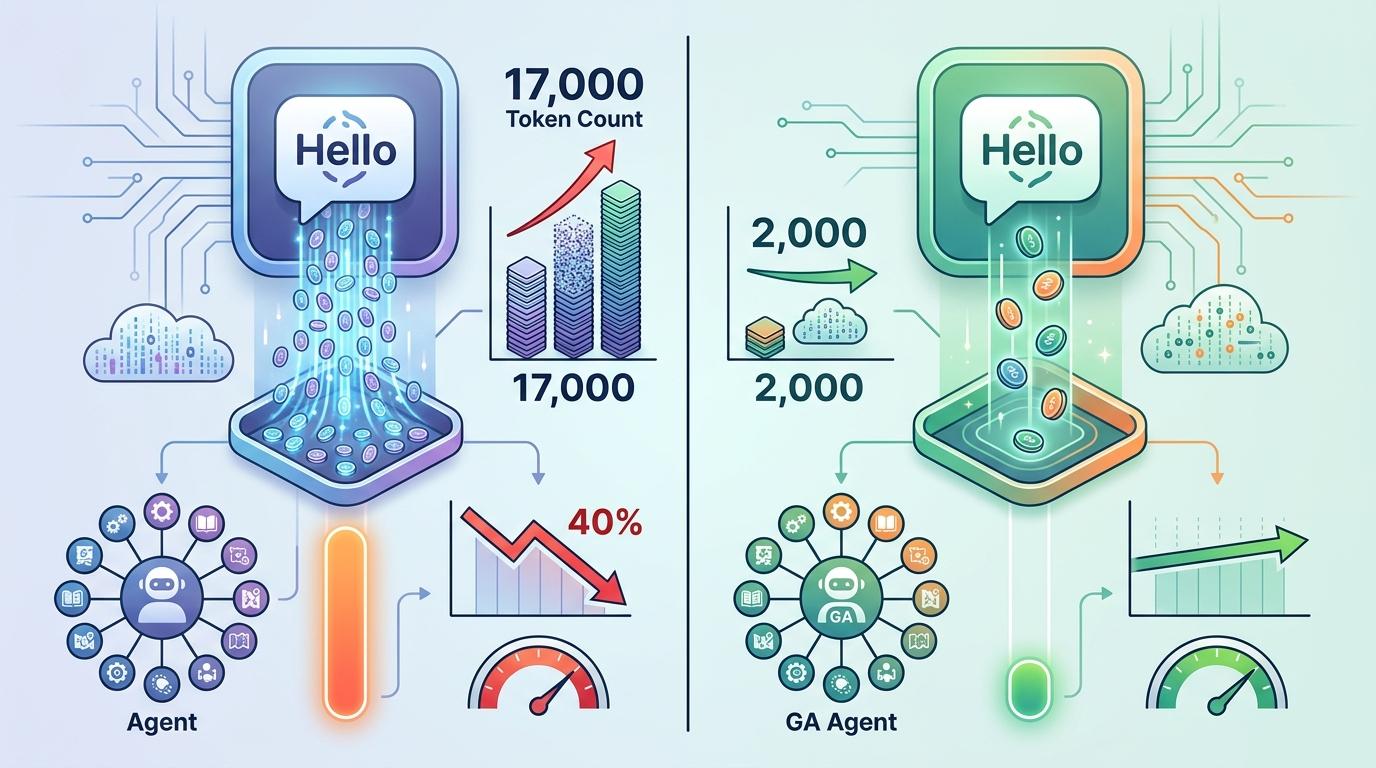
这种设计带来的效率提升是数量级的:同样应对“Hello”请求,传统Agent要消耗17000个token,GA只用2000个;装了20个技能后,前者的响应速度会下降40%,后者却能保持初始流畅度。
支撑GA高效运行的,是一套叫“Harness工程”的方法论——简单说,就是给大语言模型搭一副“刚刚好”的骨架,让它既能干活,又不被冗余信息拖累。
你可以把大模型比作一个聪明但没条理的员工,Harness工程就是给它制定清晰的工作流程:明确什么时候该调用什么工具,哪些信息必须记住,哪些可以随时丢弃。GA的Agent Loop只有100行代码,却实现了完整的“感知-推理-执行-记忆”闭环:它会先判断当前任务需要什么信息,然后只把这些信息塞进上下文,完成决策后再把关键结果存入分层记忆系统,而非全部对话历史。
这套骨架的精妙之处在于“动态适配”。比如处理长周期任务时,GA会把阶段性成果存入“长期记忆”,只把当前任务的关键信息留在上下文窗口;当需要调用工具时,它会自动生成极简的工具描述,而非完整的使用手册。Terminal Bench 2.0测试显示,仅仅优化Harness部分,固定模型的性能就能从Top 30跃升至Top 5,这足以说明骨架的重要性。
当然,这种极致精简也有局限:GA的9个原子工具虽然覆盖了核心场景,但面对某些小众任务时,用户需要自己扩展工具,这对新手有一定门槛;而且它的上下文压缩依赖结构化总结,遇到高度依赖语境的对话时,可能会丢失微妙信息。
GA的意义不止于技术优化,更在于它戳中了企业AI部署的痛点:Token正在成为看不见的成本黑洞。
根据FinOps实践数据,62%的企业无法准确预测月度AI费用,缺乏管控的AI部署可能导致预算超支500%-1000%。而Token消耗是AI成本的核心:输入输出的Token数量直接决定计算资源用量,高级模型的Token成本是基础模型的20-60倍。传统Agent的上下文膨胀,本质上是在无意义地消耗Token资源——比如每次对话都重复发送所有技能说明,相当于每次开会都把所有员工手册再念一遍。
GA的思路给企业提了个醒:AI的效率革命,本质是信息利用效率的革命。通过优化上下文密度,企业不仅能降低Token成本,还能提升Agent的响应速度和准确率。比如医疗领域的Deep Agents,通过三次上下文压缩,把14000多Token的医学会话浓缩成精准摘要,不仅节省了成本,还提升了临床决策的准确性。
但要实现这种优化,企业需要的不只是技术框架,更需要一套“Token成本管控体系”:比如实时监控Token消耗,给不同任务设定上下文预算,用结构化记忆替代完整对话历史。毕竟,AI本身不贵,未管理的AI才贵。
当我们为大模型的参数竞赛欢呼时,GA的出现像一记冷静的提醒:AI的进化从来不是单纯的“堆料”,而是对信息本质的理解。从“追求更长上下文”到“追求更高信息密度”,这背后是AI设计理念的转变——从“拥有更多信息”转向“用好每一点信息”。
未来的AI Agent,或许不会是一个塞满工具的“瑞士军刀”,而是一个能精准取舍的“高效助手”。每一个Token都有它的价值,每一点信息都该为决策服务。这正是GA给我们的启示:用最少的信息,做最优的决策。当我们学会给信息做减法时,AI才能真正成为高效的生产力工具。