对抗知识焦虑,从看懂这条开始
App 下载
用RGB打包双视图,AI造出配对乳腺钼靶图
医学影像合成|虚拟患者|双视图配对|乳腺钼靶图|临床诊疗技术|AI产业应用|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载医学影像合成|虚拟患者|双视图配对|乳腺钼靶图|临床诊疗技术|AI产业应用|医学健康|人工智能
当AI想学着放射科医生的样子,通过乳腺钼靶图诊断乳腺癌时,它遇到了和人类医生完全不同的困境:医生缺的是经验,它缺的是「成对的眼睛」。
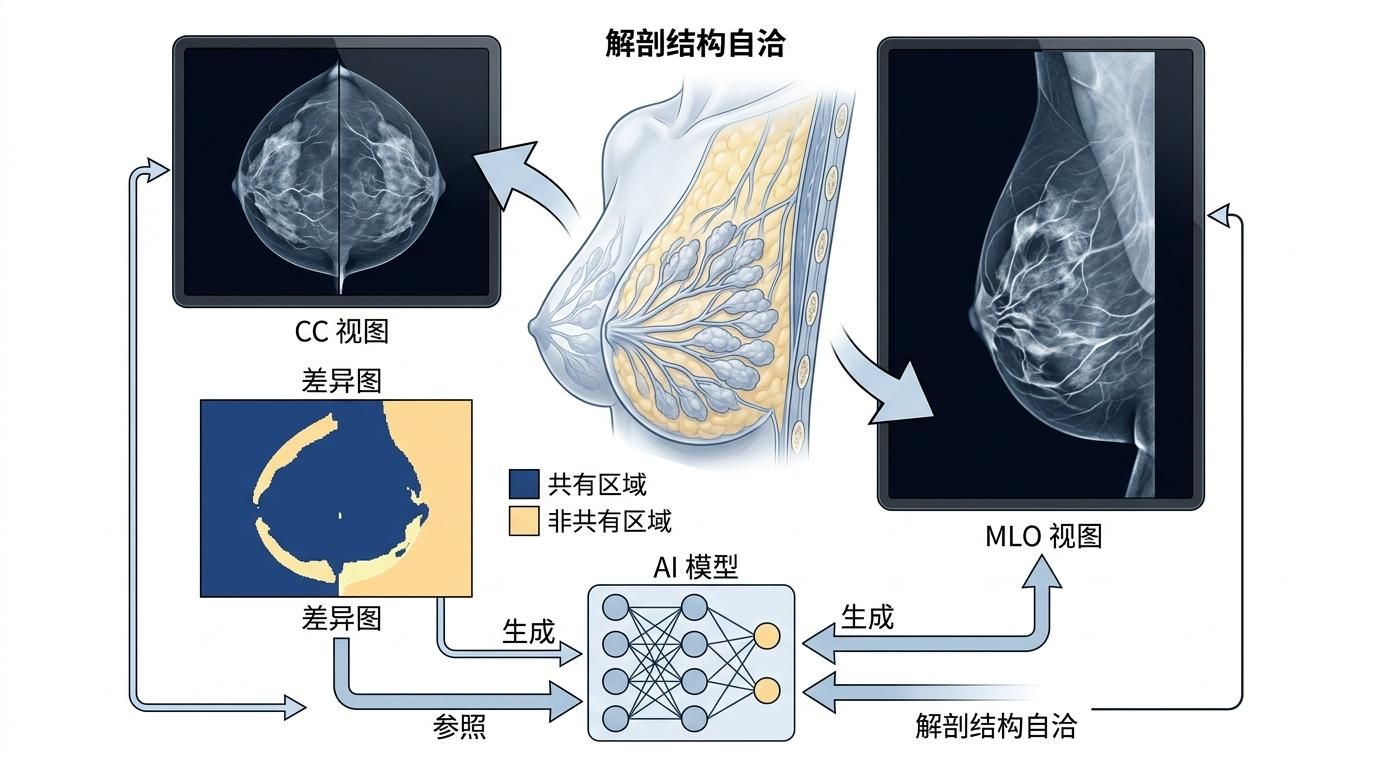
乳腺钼靶筛查必须同时看两个角度的片子——从上往下拍的头尾位(CC)和从侧面斜拍的内外斜位(MLO),两个视图互补才能揪出藏在软组织里的病变。但公开数据集中,近半数病例的双视图是残缺的,要么只有CC,要么只有MLO。没有成对的数据,AI根本学不会「用两个视角看同一个乳房」。
直到墨西哥和智利的研究者们想出了一个偷懒又聪明的办法:既然凑不齐成对数据,那就让AI自己「造」一对——而且得保证这对片子绝对属于同一个「虚拟患者」。
你可以把这个思路理解成给AI准备「配对训练套餐」:把原本分开的两张灰度钼靶图,塞进一张RGB彩色图的三个通道里——红色通道放CC视图,绿色通道放MLO视图,最关键的蓝色通道,放的是两张图的像素级绝对差值。
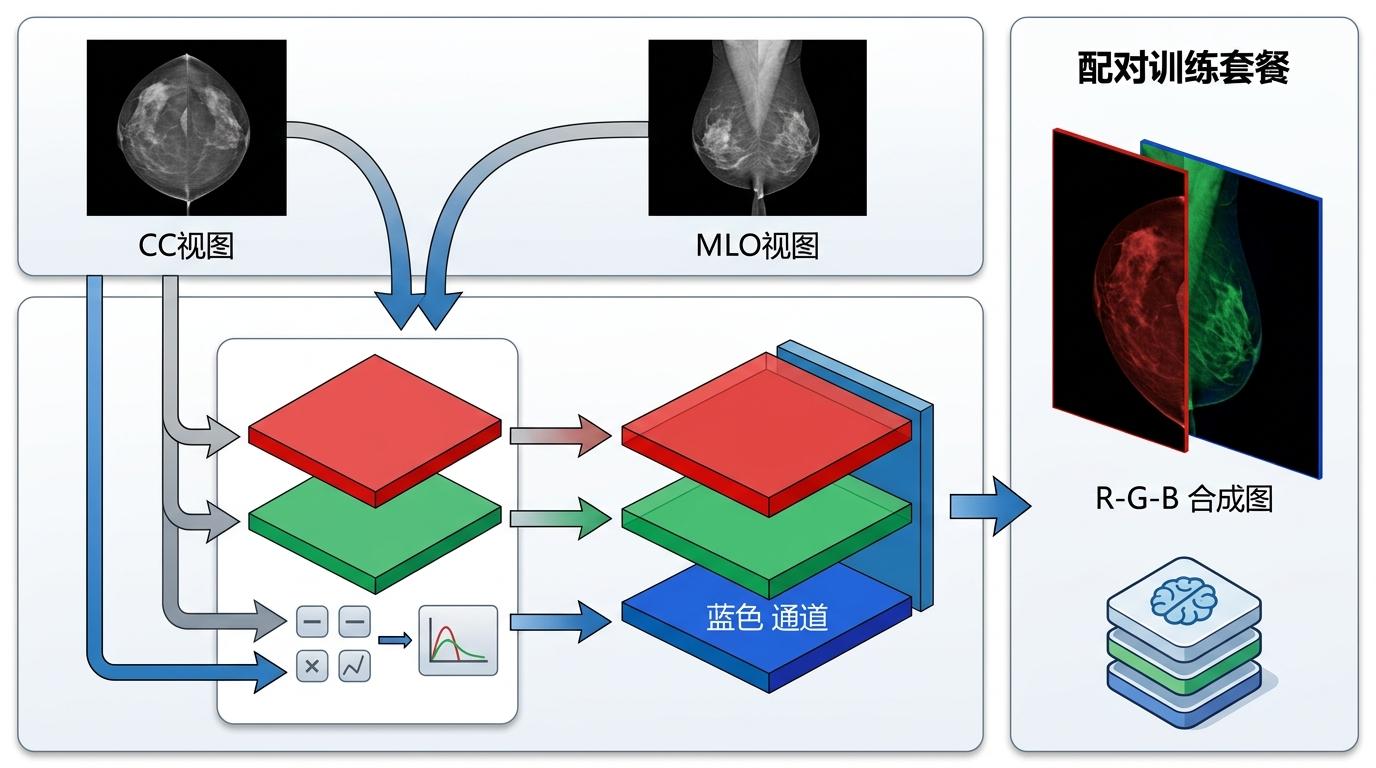
这个蓝色通道是整个方案的点睛之笔。它就像给AI附上了一份「标准答案」:哪些区域是两个视角都会拍到的乳腺组织(差值小,颜色深),哪些区域是因为角度不同才出现的差异(差值大,颜色亮)。AI在学习生成时,会自动参照这份差值图,确保生成的CC和MLO视图,在解剖结构上是「自洽」的——就像同一个人换了个姿势拍照,而不是两张毫不相干的片子。
这个操作把一个复杂的「双视图一致性生成」问题,直接转化成了AI最擅长的「RGB图像生成」任务,不需要重新搭建复杂模型,只需要用现成的工具改改输入就行。
研究者们选了当下最火的去噪扩散概率模型(DDPM)——简单说就是一种能从噪声里一步步还原出清晰图像的AI,而且它的优势是生成的图像稳定、细节丰富,不像早期的GAN容易出现「模式崩溃」。
但他们没有从零开始训练这个模型——那样不仅要花上百张GPU卡,还需要海量数据。他们直接用了Hugging Face上一个预训练好的DDPM模型,这个模型原本是用来生成人脸的。
接下来的操作就像让一个擅长画人像的画家转行画乳房:只需要把之前打包好的RGB乳腺钼靶图喂给它,让它在原有绘画功底的基础上,专门学习乳腺组织的形态、纹理,以及双视图之间的差值规律。这个过程就是「微调」——只用了少量配对的真实钼靶数据,就把一个通用图像生成AI,变成了专门的「双视图乳腺钼靶画师」。
当需要生成图像时,给AI输入随机噪声,它会吐出一张完整的RGB图,把红、绿通道分开,就是一对解剖结构一致的CC和MLO视图。
研究者做了两轮严格的测试,来验证AI生成的双视图到底靠不靠谱。
第一轮是视觉盲测:让非专业评审员看500对合成图像,判断它们是不是来自同一个患者。结果94%的图像对都通过了测试,只有6%出现了明显伪影——大多是因为原始训练数据的预处理误差,被蓝色差值通道放大了。
第二轮是量化评估:用图像分割技术勾画出乳房的轮廓,计算同一对视图的轮廓重叠度,也就是交并比(IoU)和戴斯相似系数(DSC)。结果显示,合成图像的这两个指标和真实数据几乎没差——合成数据的IoU是0.674,真实数据是0.654;DSC是0.800,真实数据是0.784。虽然统计检验显示有微小差异,但数值上的差距小到可以忽略。
不过研究者也坦诚,目前的评估只停留在宏观结构的一致性上,对于乳腺癌诊断最关键的微观钙化点、肿块纹理,AI能不能生成跨视图一致的细节,还需要更精细的验证。而且这些合成图像现在还只能用来当「训练素材」,绝对不能直接用于临床诊断。
这项研究最有意思的地方,不是它用了多么复杂的模型,而是它用一个巧妙的「包装思路」,把专业领域的难题,转化成了通用AI能解决的常规任务。它给医学AI领域提了个醒:有时候解决数据稀缺的问题,不一定非要去抢着收集真实数据,换个方式「打包」现有数据,就能让AI发挥出意想不到的能力。
更值得关注的是,这个思路完全可以复制到其他医学影像场景——比如CT的不同相位、MRI的不同序列,只要是需要成对视图的任务,都可以用类似的RGB编码方法,让通用生成AI快速变身专业领域的数据生产者。
巧思比算力更能突破数据瓶颈。当我们还在为医学数据的稀缺发愁时,这个研究已经给我们指了一条新的路:与其等数据,不如教AI自己造数据。