
5 天前
5 天前
当你还在纠结要不要花上万元换一台AI PC,或是担心云端AI泄露你的工作文档时,一款像移动硬盘一样的小盒子,在海外众筹平台5小时就筹到了100万美元。它不处理办公文档,不跑游戏,只专注一件事:让百亿参数级的大模型在你本地设备上跑起来——不用联网,不用按月付算力费,你的数据全程留在自己手里。这个小盒子爆火的背后,藏着一套让大模型「轻装上阵」端侧的核心逻辑:端侧异构算力架构。
你可以把大模型想象成一个大型办公室:有些员工(参数)每天都要处理核心工作,比如理解日常对话、分析通用文本;另一些员工只在碰到专业问题时才会被喊来,比如解读医学报告、生成复杂代码。前者就是「热激活参数」,后者是「冷激活参数」——它们的调用频率相差几个数量级。
过去要让大模型本地跑,只能堆高性能GPU,就像给整个办公室都配顶配电脑,不仅贵,还费电。而端侧异构架构的思路是:让合适的人干合适的活。把热激活参数放在专门为大模型优化的dNPU(专用神经网络处理单元)里,这部分芯片去掉了图形渲染等无关功能,只专注高速处理AI任务;冷激活参数则交给功耗更低的通用SoC(系统级芯片),平时处于低功耗待机,只有需要时才启动。
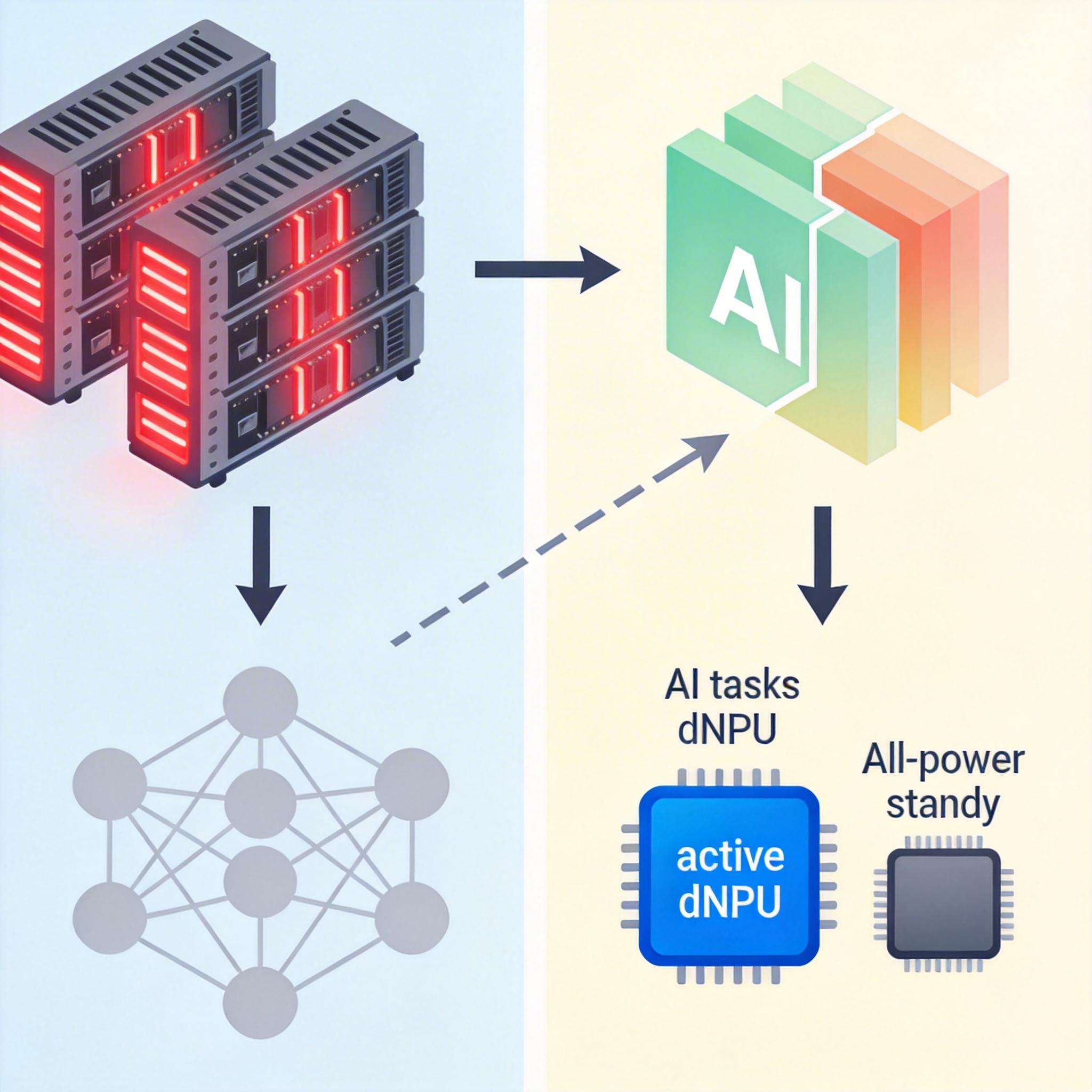
这套分工的效果很直观:在实测中,百亿参数模型的预填充速度能达到300 tokens/秒,解码输出速度也能稳定在20 tokens/秒——已经快过普通人的阅读速度。
光有硬件分工还不够,得有个聪明的「调度员」把任务分配清楚。这里的核心是推理引擎——它能实时识别哪些参数是当前任务的「热区」,提前把它们加载到高速内存里;对于冷参数,则只在需要时才从低速存储中调取,避免占用宝贵的高性能算力。

打个比方,这就像你在家做饭:常用的盐、油放在灶台边的调料架(dNPU内存),随手就能拿到;偶尔用的香料、干货则放在橱柜深处(SoC存储),需要时再去取。而推理引擎就是那个提前帮你预判菜单、把要用的调料摆好的助手。
更关键的是,这套系统还用到了MoE(混合专家)模型——它看似有百亿参数,但每个任务只会激活其中一小部分,就像办公室里只让相关部门加班,其他人正常休息。这种「稀疏激活」的设计,让小盒子能用远低于AI PC的功耗,跑出接近专业显卡的性能。当然,也有人质疑这种参数计算方式的严谨性,但不可否认,它确实在算力和功耗之间找到了一个巧妙的平衡点。
这款小盒子的爆火,其实戳中了当下AI硬件市场的一个空白:专业用户想要本地大模型的隐私和速度,却不想为了这一个需求换掉整个电脑。它更像是一个过渡方案——就像当年在SSD普及前,大家用移动硬盘扩容一样。
但它的意义不止于此。端侧异构算力架构证明,大模型不用非得靠云端或顶配PC才能跑起来,通过软硬件的协同优化,普通设备也能承载智能需求。当然,它也面临着不少挑战:比如不同芯片架构的算力调度标准不统一,散热设计要在静音和性能之间妥协,还有模型适配的复杂程度。
更值得思考的是,当越来越多的智能需求从云端回到本地,我们对AI硬件的定义会不会被改写?未来的个人设备,会不会像现在的手机一样,把通用计算和AI计算彻底分开?
从云端到端侧,AI正在从「共享服务」变成「私人助理」。这款小盒子或许只是一个临时的解决方案,但它背后的异构算力思路,正在打开一扇新的门:让智能真正属于每个设备,每个用户。
算力的未来,从来不是堆出来的,而是「省」出来的——用对地方的算力,才是真正有用的算力。
点击催更,成为大圆镜下一个视频选题!