对抗知识焦虑,从看懂这条开始
App 下载
AI不用重训也能升级,两篇论文捅破天花板
免重训练|物理机器人|南大微软联合团队|清华大学团队|技能自进化|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载免重训练|物理机器人|南大微软联合团队|清华大学团队|技能自进化|AI智能体|人工智能
想象一下:你手机里的AI助手不用每次等系统更新,今天帮你订机票时学会了规避高峰票价,明天处理报表时自动掌握了新函数——它像你一样,在做事中悄悄变强,不用推倒重来。2026年5月11日,arXiv上两篇同天发布的论文,把这个想象砸成了现实。清华、北交大的团队和南大、微软、清华AIR的团队,各自在数字工具和物理机器人两个赛道,把AI技能自进化的可能性拉到了新高度。最狠的是,它们都不用给大模型重训——这个曾经让科技公司烧钱到肉疼的步骤,被彻底绕开了。
过去的AI智能体,就像拿着一本固定说明书的实习生:说明书是人类写死的,一旦环境变了、任务复杂了,要么对着新问题手足无措,要么把执行时的手抖当成说明书写错,乱改一通把原本正确的内容也删了。更糟的是,要让它升级,就得把整本说明书推翻重写,再让AI重新学一遍——也就是大模型重训,成本动辄百万美元,还可能把之前会的技能忘光。
这两篇论文的核心,就是把AI的"技能"和"大脑"拆分开:大脑(大模型参数)不动,只让技能手册自己进化。就像给实习生换一本自动更新的操作指南,而不是把他送去回炉重造。
清华团队的SkillEvolver瞄准数字工具场景,比如让AI帮你写代码、处理数据。它搞了个"作者-执行者-审计官"的三角分工:一个AI专门写技能手册,另一个去执行,执行完再让第三个独立AI当审计,检查手册里有没有废话、错误或者偷懒的地方。每一轮迭代,它都会生成4种不同策略去试,对比成功和失败的差异,只改出问题的部分,绝不瞎改整本手册。
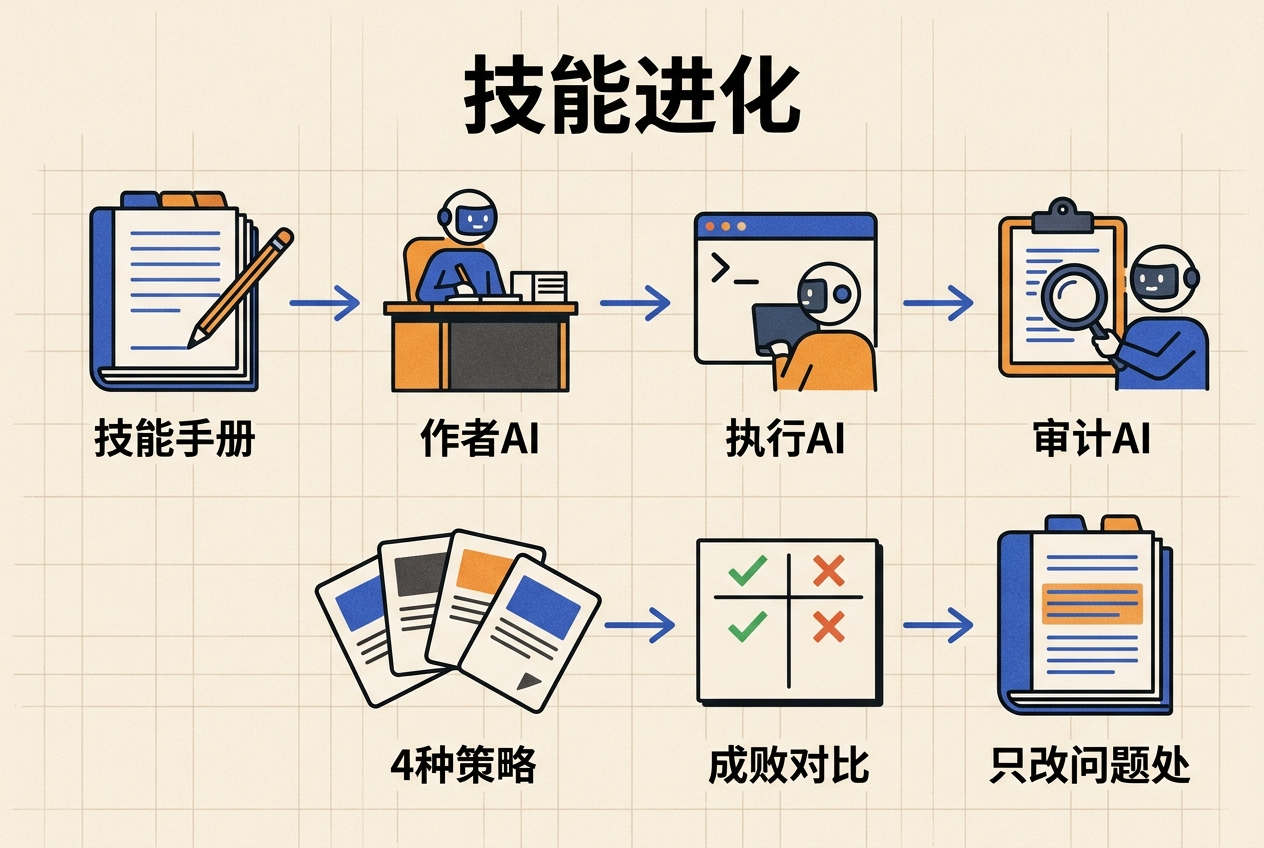
如果说SkillEvolver是给办公室AI升级,那南大团队的EmbodiSkill就是给物理世界的机器人看病。机器人干活时失败了,到底是动作没做到位(执行失误),还是一开始的动作逻辑就错了(技能缺陷)?以前的算法分不清楚,只会把整个操作流程全改了,结果越改越乱。
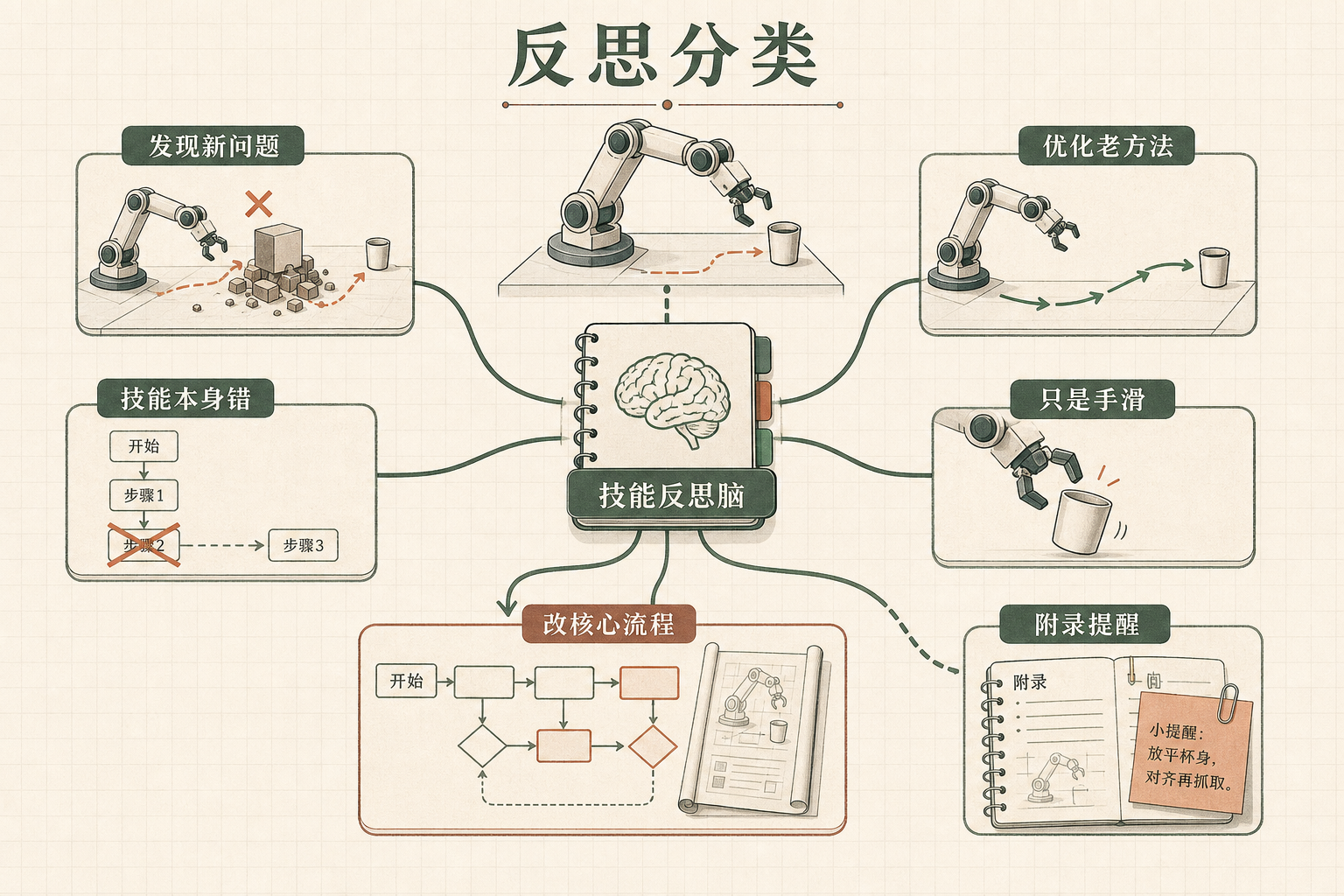
EmbodiSkill给机器人装了个"技能反思脑":每次干完活,它会把失败原因分成四类——发现新问题、优化老方法、技能本身错了、只是手滑没做好。前三种情况才会修改核心操作逻辑,要是只是手滑,就只在附录里加个提醒:"下次抓杯子别太轻",绝不碰正确的核心流程。
这种精准到骨子里的修改,效果立竿见影:在家庭任务模拟测试ALFWorld里,搭配EmbodiSkill的Qwen3.5-27B模型,任务成功率冲到了93.28%,直接把GPT-5.2裸跑的70.89%甩在身后;就连需要同时放两个物体的复杂任务,它都做到了100%成功。
这两篇论文的实验数据,把"技能自进化"的价值钉得死死的:SkillEvolver在15个领域的83项任务里,平均成功率56.8%,超过了人类写的技能的43.6%;而且单任务成本才3.92美元,比传统重训便宜了不止一个量级。
但这不是什么颠覆式的革命,更像是给AI补上了人类从小就会的学习习惯:做错题、找原因、记下来下次改。以前的AI是"一次性学会所有事",现在它终于能"边做边学,越做越好"。
当然,问题也不少:比如SkillEvolver在简单任务上的表现和人类技能差不多,资源都花在了难啃的硬骨头;EmbodiSkill也只在模拟环境里验证过,真到真实世界里,机器人要面对的突发状况可比模拟复杂多了。而且谁来监督AI的"错题本"?要是它把错的经验当成对的记下来,越进化越跑偏怎么办?这些都是绕不开的坎。
我们总说AI要像人一样学习,但以前的思路都是"让AI拥有人的大脑",现在终于有人转了个弯:"让AI拥有人的学习习惯"。不用重训,不用烧钱,只是让AI在做事中反思、在错误里修正——这种看似朴素的思路,反而捅破了AI能力提升的天花板。
未来的AI,可能不会再以"模型版本号"划分强弱,而是以"技能进化速度"论高下。就像人类一样,真正拉开差距的不是天生的智商,而是后天的学习能力。
大脑不用换,技能天天练。