对抗知识焦虑,从看懂这条开始
App 下载
不用文本大模型,超分辨率反而更准更快
图像细节还原|超分辨率技术|OPPO团队|香港理工大学|VOSR模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像细节还原|超分辨率技术|OPPO团队|香港理工大学|VOSR模型|多模态视觉|人工智能
你有没有过这种经历:把手机里模糊的老照片放大,结果要么糊成马赛克,要么凭空多出不存在的细节——比如爷爷的眼镜框变了形状,墙上的海报长出奇怪的图案?这就是超分辨率技术的老毛病:为了让图像清晰,总忍不住“脑补”假细节。
过去两年,行业都在靠大号文本-图像模型救场,用亿级图文数据喂出的模型来做超分,效果是好了,但训练一次要烧掉上百万元电费,推理一张图要等好几秒。直到香港理工大学和OPPO的团队掏出了VOSR——一个完全不用文本数据的纯视觉模型,训练成本不到主流方法的十分之一,却能把细节还原得更准,脑补的假细节更少。
问题来了:它是怎么绕开文本大模型,还能做得更好的?
你可以把传统纯视觉超分模型想象成一个只会看轮廓的画家:给它一张模糊的简笔画,它能画出大致形状,但细节全靠瞎蒙——比如把简笔画里的“圆形”脑补成苹果,也可能脑补成皮球。这就是“语义歧义”:低分辨率图像里的模糊轮廓,本来就对应多种可能的清晰细节。
VOSR的解法是给AI装两双眼睛:一双看结构,一双看语义。
结构分支用和高分辨率图像同款的编码器处理低分辨率图,就像拿着原图的轮廓稿作画,保证画出来的东西位置、形状都和输入严丝合缝;语义分支则用预训练的视觉模型提取图像里的高层信息——比如这是“人脸”不是“苹果”,这是“金属栏杆”不是“木头栅栏”,从根源上减少脑补错误。
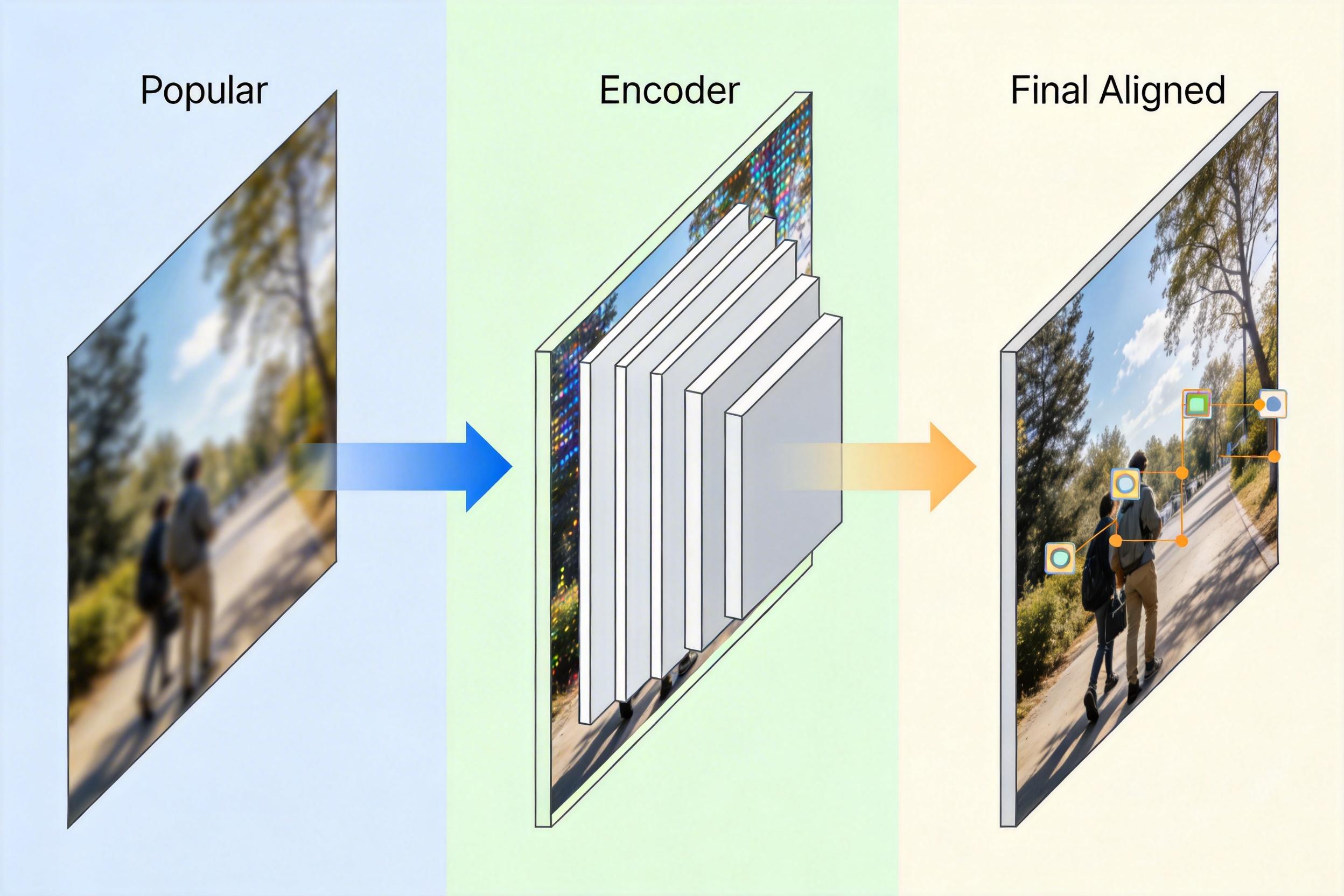
直给来说:
解决了“画什么”的问题,还要解决“怎么画”的问题。过去用文本模型做超分,常犯的错是为了追求“好看”,把原图的细节改得面目全非——比如把老照片里的平房修成别墅。这是因为传统的引导方法会让AI在“自由创作”和“忠实还原”之间走极端。
VOSR换了个思路:不给AI完全自由的空间,也不把它捆死在原图上。它把引导分支分成“强锚定”和“弱锚定”两个:强锚定分支严格跟着原图的结构和语义走,弱锚定分支只保留最基础的结构线索,允许AI在细节上做合理补充。
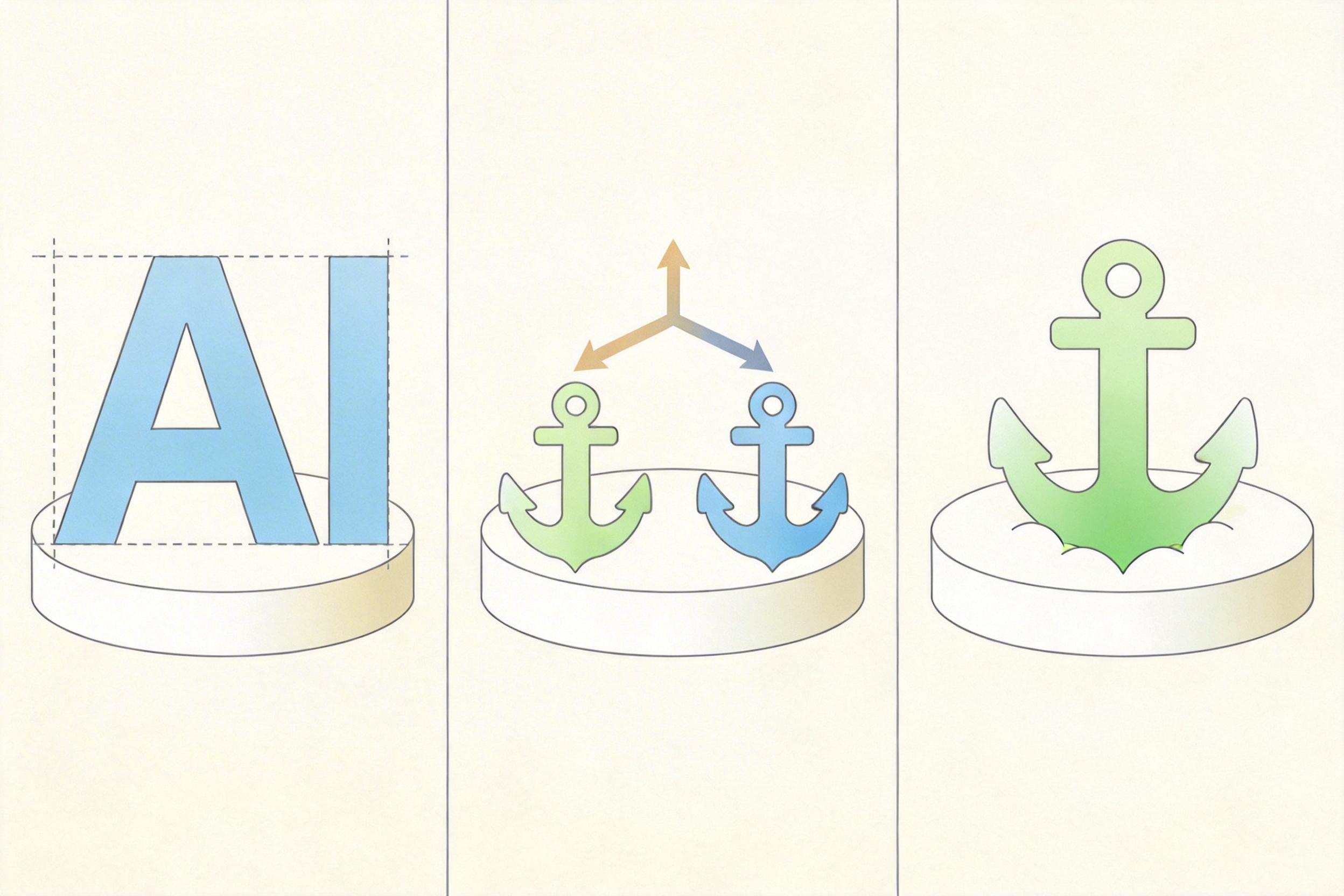
训练时,模型会随机切换两种模式,学会在“忠实”和“创作”之间找平衡;推理时,用户还能自己调参数:想更忠于原图就把锚定调强,想让细节更丰富就给AI多一点创作空间。
更关键的是效率。多步扩散模型虽然效果好,但推理一张图要迭代几十上百步,像慢动作作画。VOSR用递归一致性蒸馏技术,把多步模型的能力“压缩”进单步模型里——就像让画家把几十笔才能画好的细节,一笔到位地画出来。单步模型推理一张512×512的图只需要0.095秒,速度和传统CNN模型相当,效果却接近多步扩散模型。
在真实场景的测试里,VOSR的优势一目了然。比如处理一张模糊的桥梁照片,传统文本超分模型可能把钢缆画成扭曲的线条,甚至凭空多出几根;VOSR却能精准还原每一根钢缆的走向和纹理,连钢缆上的铆钉都清晰可见。

定量数据更有说服力:在合成数据集LSDIR上,VOSR的多步模型在感知质量指标LPIPS上拿到了0.012的成绩,比主流文本超分模型低了0.003——数值越低,说明生成图像和真实图像越接近;在真实场景数据集RealSR上,VOSR的单步模型在无参考质量指标NIQE上得分2.3,比其他纯视觉模型低了0.5,意味着普通人用肉眼几乎看不出它和真实高分辨率图的区别。
当然它也不是完美的。在处理极端模糊的图像时,比如分辨率只有16×16的超低清图,VOSR的语义分支偶尔还是会判断失误,把“猫脸”认成“狗脸”。但相比文本模型动辄把“猫”生成“老虎”的严重脑补,这种小失误已经可控得多。
当整个行业都在往“更大的模型、更多的数据”里钻的时候,VOSR的出现像一记提醒:有时候,不是问题太复杂,而是我们找错了解题的方向。
超分辨率的本质,从来都不是“生成一张新图像”,而是“还原原本存在的细节”。依赖文本大模型,就像为了修一双鞋,先造了一整套制鞋流水线——虽然能修好,但成本太高,还容易把鞋的款式改得面目全非。VOSR则直接拿起了修鞋的工具,专注于把磨损的纹路补好,把松动的缝线缝牢。
好的技术,是用对的方法解决问题,而不是用复杂的方法证明能力。 未来的超分辨率技术,或许会有更多这样的“减法创新”:不用追求最大的模型,只用最适合的方法,把该做的事做好。