对抗知识焦虑,从看懂这条开始
App 下载
慢如蜗牛的扩散模型,终于能实时融合红外可见光
实时扩散模型|双信号蒸馏|自动驾驶视觉系统|红外可见光融合|FusionProxy|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载实时扩散模型|双信号蒸馏|自动驾驶视觉系统|红外可见光融合|FusionProxy|多模态视觉|人工智能
深夜大雾里的自动驾驶汽车,可见光摄像头只剩一片白茫茫,红外热成像却能把行人、车辆照成清晰的「发光体」——把这两种图像无缝融合,是全天候视觉系统的核心需求。但此前的技术始终卡在两难:要么用扩散模型生成高质量融合图,却要等几秒甚至十几秒,完全赶不上实时决策;要么用GAN类方法实现16帧/秒的速度,却把细节糊成一团,还得和下游模型绑定训练。2026年5月,西北大学等四校团队推出的FusionProxy,第一次把这对矛盾掰回了平衡:它让扩散模型的高质量能力,在民用显卡上以30帧/秒的速度跑了起来。
你可以把这个过程想象成「高考状元教速成班」——扩散模型是能考满分的状元,解题思路缜密但步骤繁琐;轻量学生网络是要应付考试的速成班学生,需要把状元的解题精髓浓缩成快速答题技巧。
FusionProxy的核心是「双信号知识蒸馏」:它同时找来两位状元当老师——擅长热辐射建模的DDFM和精通纹理还原的Mask-DiFuser,让它们对同一张红外+可见光输入各出4份答案。这8份答案的像素级均值是「标准参考答案」,像素级方差则是「状元们也拿不准的题」。
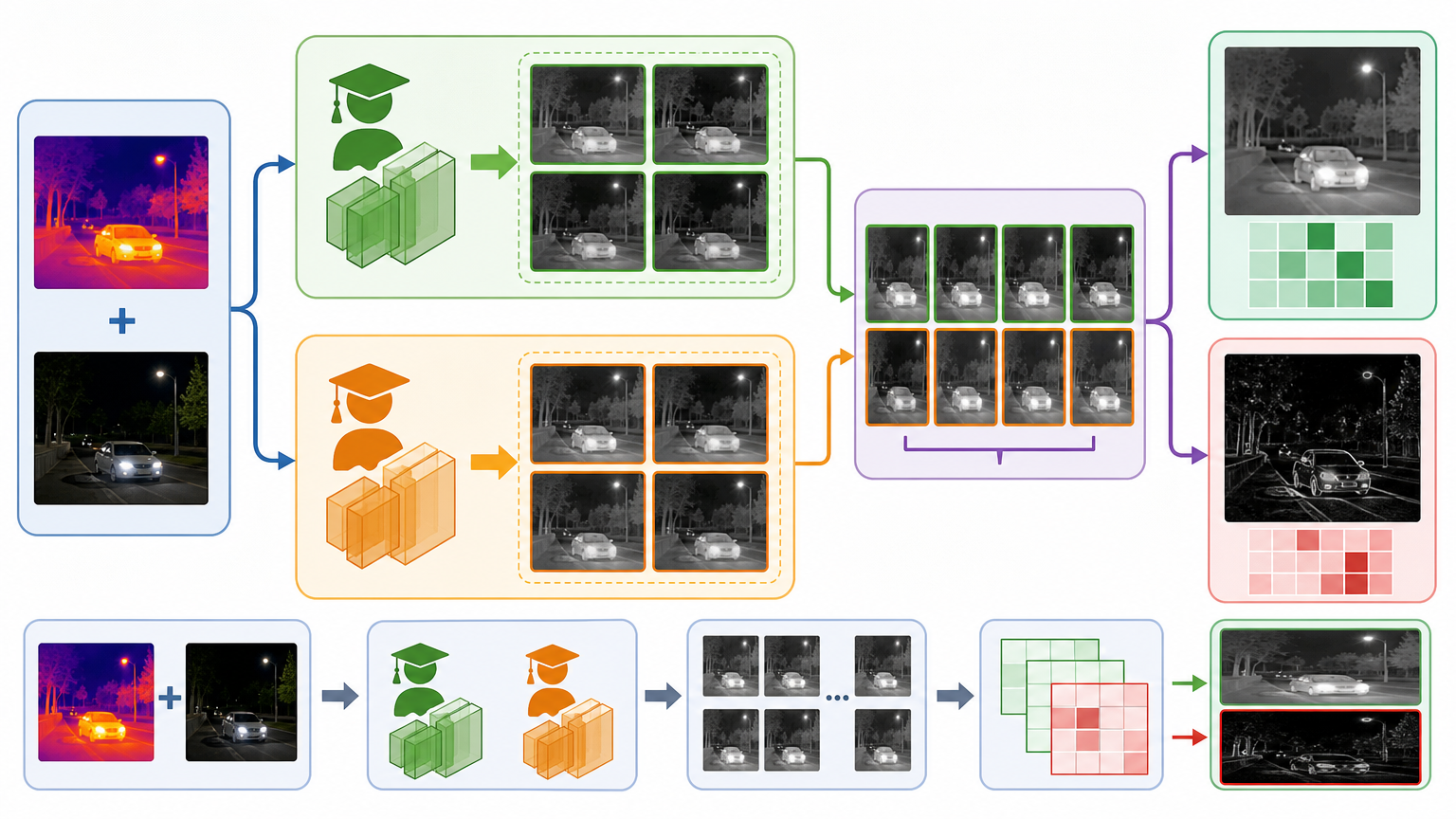
学生网络学习时,对方差小的像素(状元们一致的地方)重点学,对方差大的像素(状元们有分歧的地方)少花精力,避免被不确定的信息带偏。这是第一个信号:像素空间的不确定性加权监督。
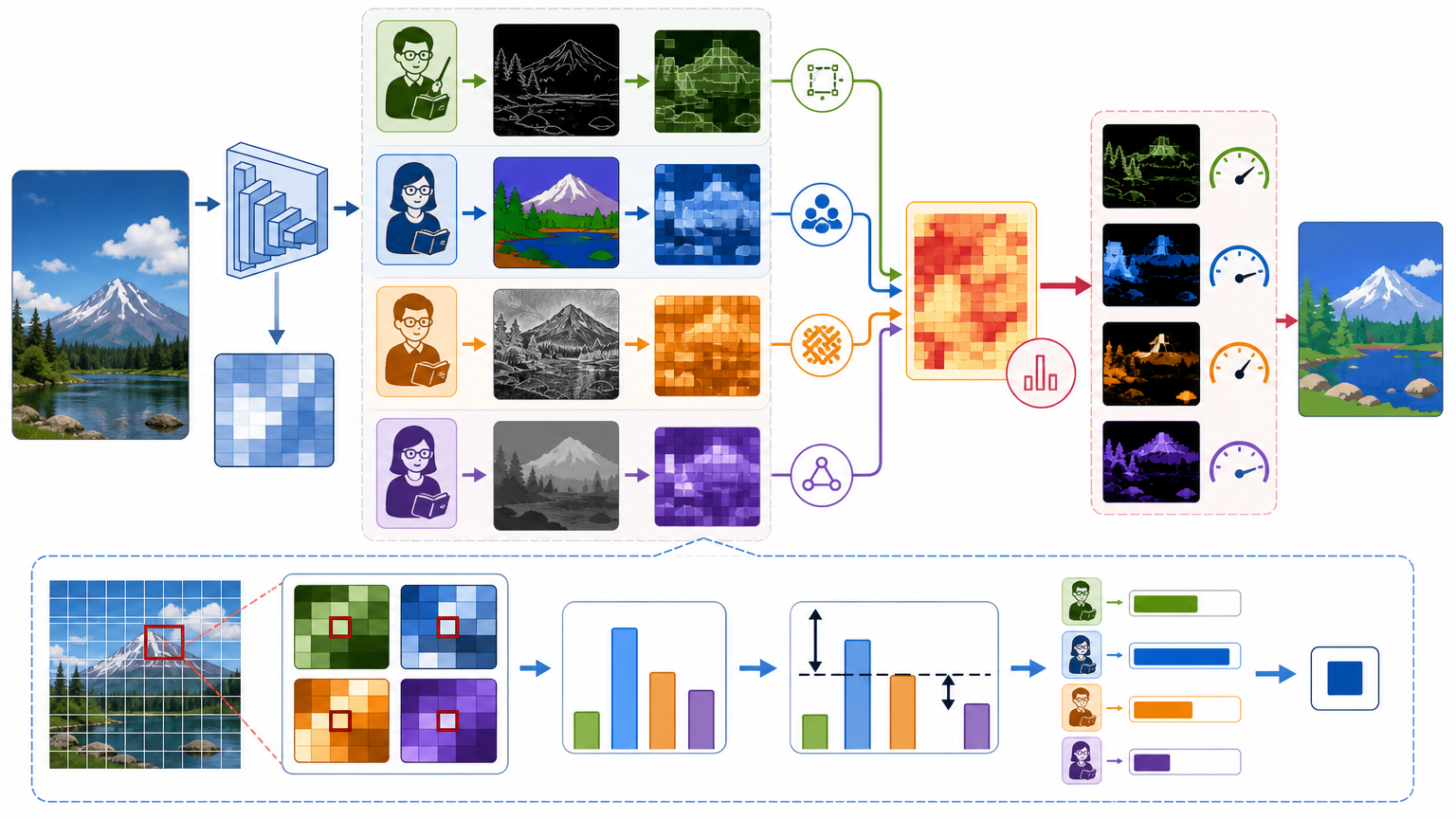
第二个信号藏在特征空间:它同时调用VGG、DINOv2、CLIP、SAM四个不同的「阅卷老师」,每个老师对图像的不同区域敏感度不同——SAM看边缘,CLIP看语义,VGG看纹理,DINOv2看结构。学生网络通过计算老师们对每个像素的判断方差,自动给最懂该区域的老师加权,确保每个细节都被最专业的标准监督。
此前的融合模型大多是「学术玩具」:要么速度慢到无法落地,要么得和下游的目标检测、分割模型绑定训练,换个场景就得重新调参。FusionProxy的终极突破,是把自己做成了一个「即插即用的USB接口」。
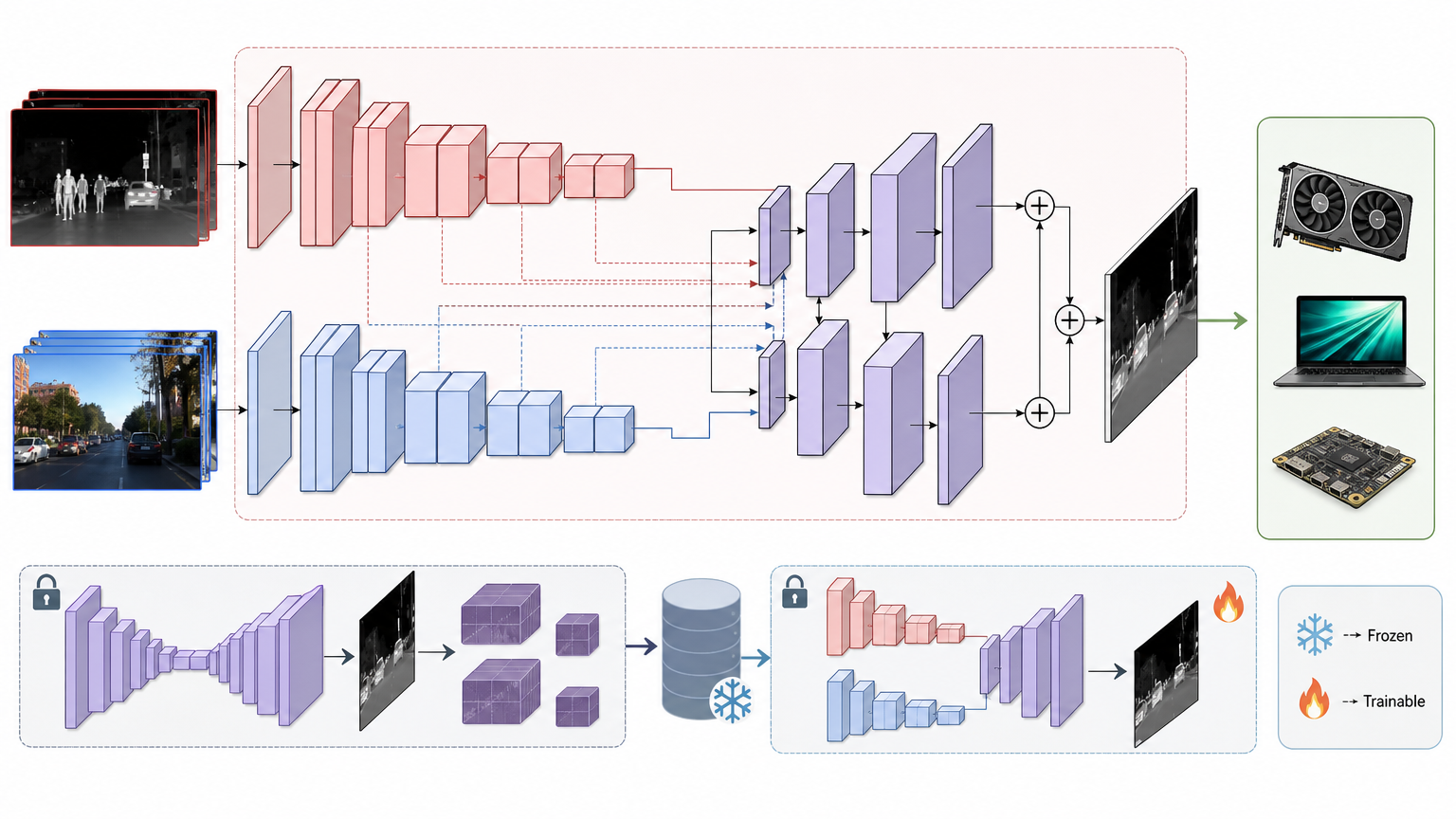
它的学生网络基于ConvNeXt V2双编码器U-Net,两个编码器分别处理红外和可见光图像,最后通过残差融合头合并输出——整个结构轻量到能在RTX 3060、苹果M3笔记本上实时运行,甚至可以换成MobileNet这类超轻量骨干网络。训练时,教师模型和所有骨干网络都被冻结,只训练学生网络,教师的答案和特征都提前离线缓存好,不用每次训练都重新计算。
更关键的是,它不需要和下游模型联合训练。实验显示,直接把YOLOv8的输入从RGB换成FusionProxy的融合图,目标检测mAP从58.2跳到75.2;SegFormer分割模型的mIoU从49.1涨到65.4;CARLA自动驾驶模拟器里,闭环驾驶成功率从52.4%飙升到86.5%——所有下游模型都完全没动过,直接替换输入就实现了性能暴涨。
FusionProxy的突破是显著的,但它还不是万能钥匙。
首先是训练成本:虽然推理阶段只需要民用硬件,但训练时得用H100这类高端显卡,还要让两位扩散教师生成大量样本缓存,前期投入并不低。其次是极端场景的泛化性:它在MSRS、M3FD这类道路场景数据集上表现优异,但在暴雨、暴雪这类极端天气,或者传感器严重不对准的情况下,性能会出现优雅下降——但还没到能应对所有边缘情况的程度。最后是硬件配套:要用上它,得同时装红外摄像头,虽然成本比雷达低,但比单装可见光摄像头还是多了一笔开销。
不过这些都是落地中的细节问题,而非原理性瓶颈。它真正的价值,是第一次把「扩散级质量」和「实时性」这两个看似矛盾的需求捏合到了一起,为全天候视觉系统打开了从实验室到量产的大门。
从传统多尺度变换到深度学习,再到如今的知识蒸馏,红外与可见光图像融合的技术演进,本质上是在不断平衡「性能」和「效率」这对永恒矛盾。FusionProxy没有创造新的模型,而是找到了一种更聪明的方法,把已有的强大能力压缩到了可落地的尺度里。
好的技术不是做加法,而是做翻译——把复杂模型的能力,翻译成边缘设备能听懂的语言。当慢如蜗牛的扩散模型学会了百米冲刺,那些曾被「速度不够」卡在实验室的视觉技术,终于有机会真正走进自动驾驶的大雾、安防监控的深夜,变成能守护普通人的实用工具。