对抗知识焦虑,从看懂这条开始
App 下载
AI视频终于懂人话,还能稳住不糊脸
细节还原|画质提升|VAE模型|AI视频生成|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载细节还原|画质提升|VAE模型|AI视频生成|AIGC|人工智能
你有没有过这种经历:花十分钟写了一段充满细节的提示词,要AI生成「穿米白色针织衫的女生在梧桐树下翻书,风撩起发梢」,结果出来的视频里,女生的脸从第三秒开始糊成马赛克,最后连书都变成了模糊的方块?过去这是AI视频生成的「日常翻车现场」——要么听不懂复杂指令,要么长视频里细节全崩。但现在,这两个最让人头疼的问题,正在被一套新的技术逻辑解决。
你可以把AI视频生成的画质问题,想象成用打印机打印照片——如果打印机的「喷头」精度不够,头发丝、针织衫的纹理这些细线条就会糊成一团。过去AI视频里的「糊脸」,核心问题就出在负责把抽象语义转换成像素画面的VAE模型(变分自编码器)上。它就像那个精度不够的喷头,处理复杂纹理时总是力不从心。
2025年西湖大学团队提出的LeanVAE框架,给这个「喷头」做了一次彻底升级。它用邻域感知前馈模块替代了传统的卷积层,就像给打印机加装了「局部细节放大镜」,能精准捕捉人脸轮廓、衣物褶皱这些高频细节;再结合Haar小波变换把视频信号分解成高低频子带,相当于把复杂画面拆成简单零件分别处理,最后再拼接成完整的清晰画面。
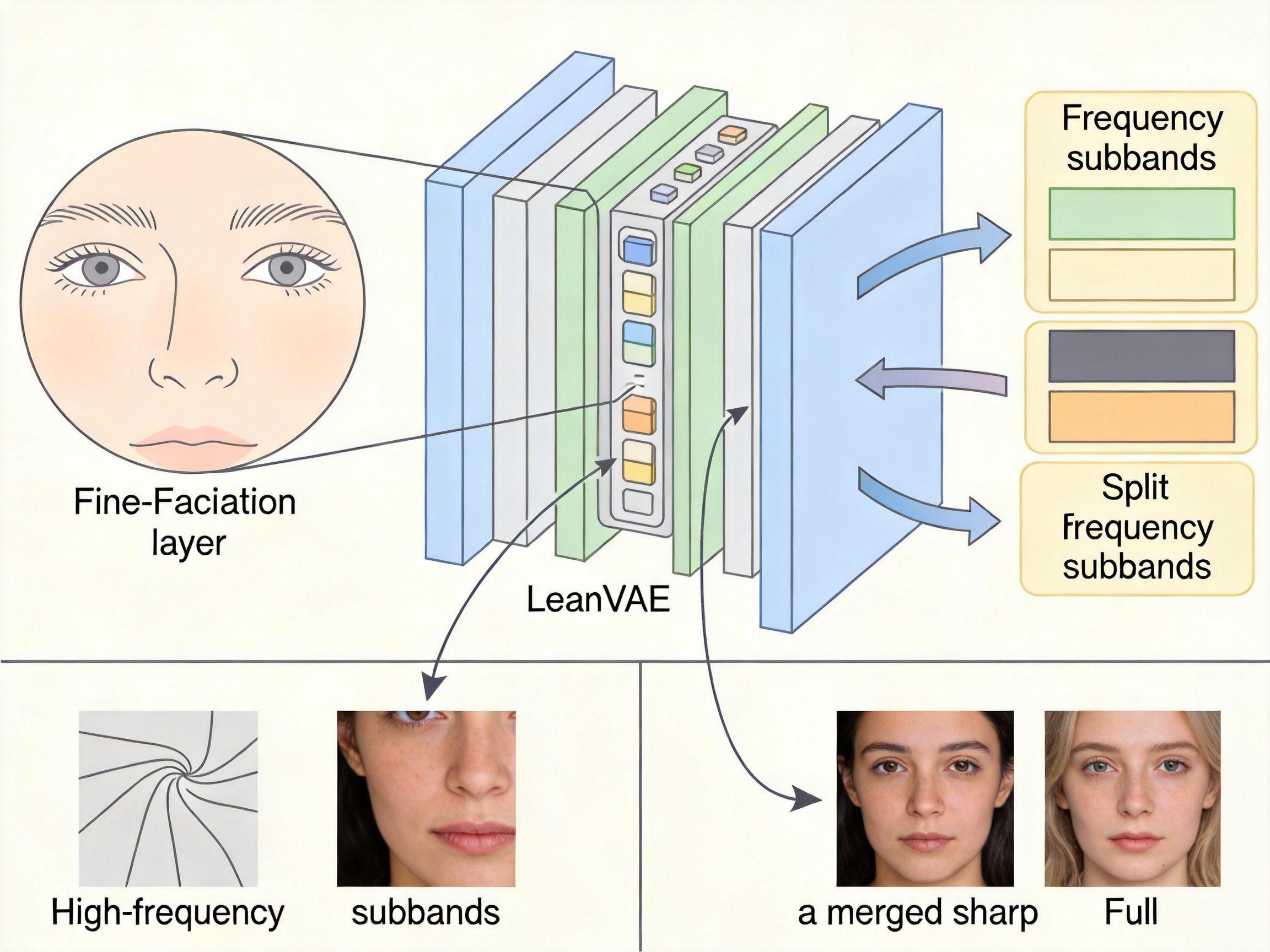
实际数据显示,LeanVAE把视频VAE的计算量降低了50倍,推理速度提升44倍,同时在人脸、毛发这些细节的重建质量上,比传统模型提升了15%以上。现在你再生成「风撩起发梢」的视频,每根发丝的飘动都能清晰连贯,不会再糊成一团色块。
如果说VAE解决的是「画得清」的问题,那门控注意力机制解决的就是「听得懂」的问题。过去AI处理长提示词时,就像听一场杂乱的演讲——各种信息混在一起,它根本抓不住重点,最后只能凭感觉瞎画。
门控注意力机制相当于给AI装了一个「智能过滤器」。当你输入「穿米白色针织衫的女生在梧桐树下翻书,风撩起发梢,阳光透过树叶在书页上投下光斑」,这个机制会把长提示词拆解成「主体(穿针织衫的女生)」「动作(翻书)」「环境(梧桐树下、阳光光斑)」几个语义模块,然后给每个模块分配不同的权重:女生的动作和外貌权重最高,阳光光斑次之,最后按照这个优先级生成画面。

具体来说,它会通过乘法门控单元,让AI在生成每帧画面时,动态聚焦到提示词的关键信息上——比如生成女生的脸时,重点关注「米白色针织衫」「发梢」这些细节;生成背景时,再把注意力转移到「梧桐树叶」「阳光光斑」上。实验数据显示,用了门控注意力的模型,在长提示词任务上的语义对齐准确率,比传统模型提升了30%以上,终于能做到「你说什么,它画什么」。
解决了「画得清」和「听得懂」,还有最后一个难题:长视频里的「细节漂移」——比如开头女生穿的是米白色针织衫,到结尾变成了灰色,或者人脸慢慢变形。这是因为传统的全局注意力机制,处理长视频时会像电脑内存不足一样,越往后越记不住前面的细节。
现在的解决方案是「混合注意力机制」:在语义空间用全局注意力,就像给AI装了一个「全局备忘录」,记住视频开头的所有细节;在像素生成阶段用局部窗口注意力(也就是Swin Attention),就像让AI每次只专注处理眼前的一小段画面,避免内存过载。
比如南京大学团队提出的StableWorld机制,还加了一层「动态帧剔除」——AI会实时检查每帧画面和前面的细节是否一致,如果发现人脸变形或者衣服颜色错了,就自动剔除这帧重新生成。现在用这种方法生成的10分钟长视频,细节一致性比传统模型提升了40%,终于能做到「开头是什么样,结尾还是什么样」。
从糊脸到清晰,从听不懂人话到精准执行,从长视频崩帧到细节连贯,AI视频生成的进步,本质上是一场「语义理解的革命」——它不再是简单的像素拼接,而是真正开始理解人类的意图和画面的逻辑。
未来的AI视频生成,会像一个专业的电影导演:你只需要告诉他故事的梗概和细节,他就能拍出画面清晰、逻辑连贯、符合你所有想象的视频。而这一切的核心,就是让AI从「画像素」变成「懂语义」。
懂语义,才是AI生成的未来。