
3 个月前
3 个月前
在偏远地区的乡镇卫生院,眼科医生李明(化名)正面临一个棘手的难题。一位中年男子因视力模糊、眼前有黑影飘动前来就诊,眼科B超图像显示其眼球后部有一个模糊的隆起。是良性的脉络膜血管瘤,还是致命的黑色素瘤?或是形态相似的视网膜脱离?每一个判断都可能决定患者的视力甚至生命。
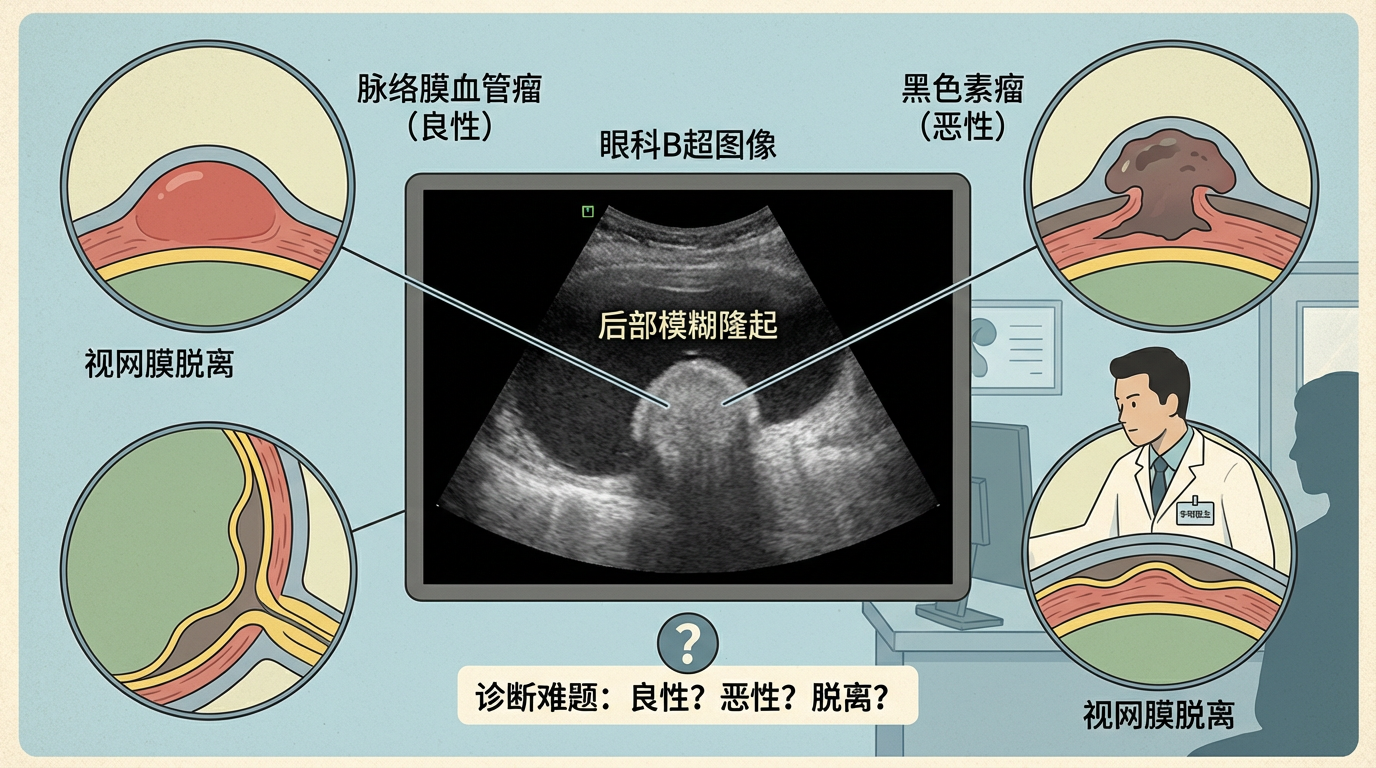
这台老旧的B超设备生成的图像分辨率不高,而将图像上传至上级医院会诊,往往需要数天的等待。在这漫长的等待中,每一分每一秒都是对患者和医生的煎熬。李医生的困境,是中国乃至全球数万名基层医疗工作者的缩影。根据《中国眼健康白皮书》,全国眼科医生不足5万名,每百万人仅拥有约21名眼科医生,远低于发达国家水平。优质医疗资源的高度集中,使得无数像李医生这样的基层“守门人”,成为了守护光明的最后一道、也是最孤独的一道防线。
然而,一场技术革命正悄然改变这一局面。2026年1月,浙江大学金凯团队在国际顶尖期刊《npj Digital Medicine》上发表的一项研究,如同一道光刺破了笼罩在眼科诊断领域的阴云。他们提出了一种名为VLS(Vision-Language Segmentation)的AI多模态视觉定位模型,它承诺将彻底改写眼科B超报告的生成规则。
研究数据令人震撼:
这项突破意味着,AI不仅做得更快、更准,还做得更便宜。它不再是遥不可及的未来科技,而是有望迅速普及到每一个角落的普惠工具。
传统的医学AI,在很多时候像一个只会“看图说话”的学生,它能描述图像中有什么,但未必理解其临床意义。而VLS模型的革命性在于,它学会了像一位资深眼科专家那样进行“思考”。
这得益于其创新的**“视觉定位”**(Visual Grounding)机制。VLS模型融合了强大的视觉语言模型和分割模型SAM(Segment Anything Model),它在分析B超图像时,不仅仅是“看到”一个模糊的团块,而是能精准地“框出”病灶区域,并理解其具体特征——例如,一个“蘑菇状”的实性隆起,内部回声不均,基底较宽。
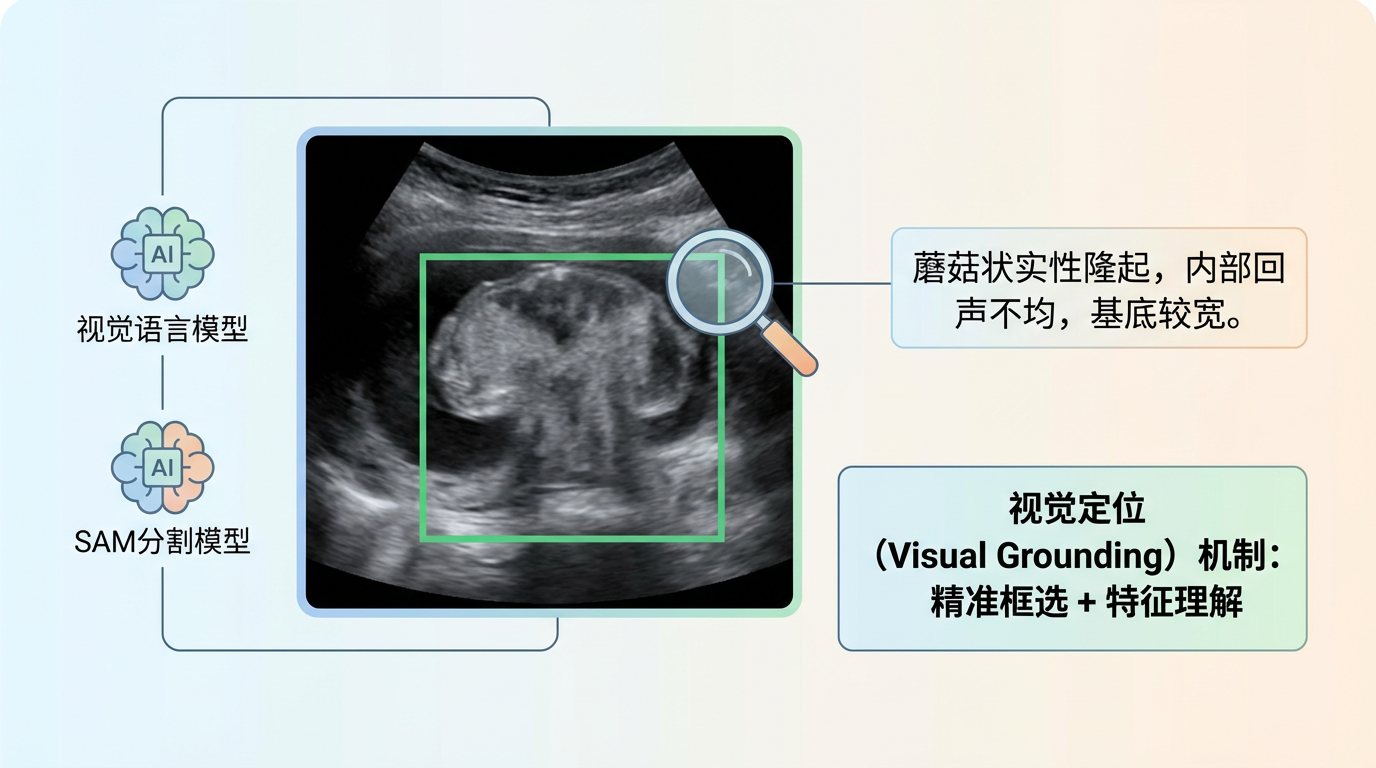
随后,模型会将这些被精准定位和量化的视觉特征,与海量的医学知识库进行关联,并自动生成一份结构清晰、术语规范、符合临床标准的文本报告。这个过程,好比一位超级助手,不仅用高光笔在复杂的图像中标出了所有关键线索,还同步撰写了一份详尽的分析报告,医生需要做的,只是审核与确认。
这种从“看”到“理解”再到“表达”的闭环,让AI生成的报告不再是空洞的描述,而是具备了高度的可解释性和临床决策价值。
VLS模型的真正价值,远不止于为三甲医院的医生减负。它最大的意义在于,将顶尖专家的诊断能力“封装”成一个可随时随地调用的工具,从而打破医疗资源分布不均的壁垒。
对于身处偏远地区的李医生而言,这意味着他不再需要孤军奋战。借助VLS模型,他可以在几秒钟内获得一份由AI生成的、媲美大城市专家的初步诊断报告。这不仅能帮助他快速鉴别眼内肿瘤、视网膜脱离等急重症,为患者抢得宝贵的治疗时间,更能极大地增强基层医生的诊疗信心。
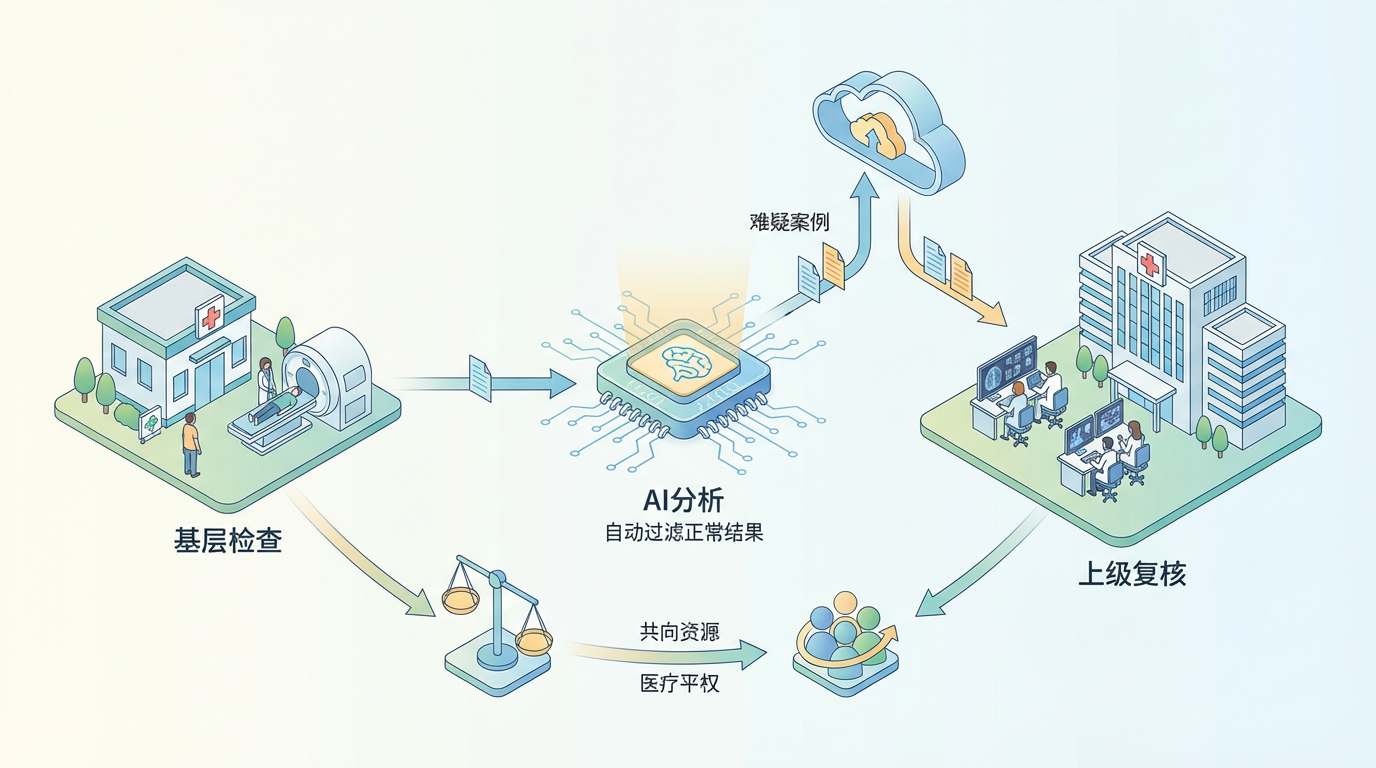
这种模式正在构建一种全新的医疗协作体系:“基层检查、AI分析、上级复核”。患者可以在家门口完成高质量的影像检查,由AI进行高效初筛,疑难病例则通过云平台传送给专家进行最终确认。这不仅极大地提升了诊疗效率,更让优质医疗资源得以“下沉”,使医疗公平从一句口号,变为触手可及的现实。
VLS模型的成功,仅仅是冰山一角。这项技术展示了多模态AI在医学影像领域的巨大潜力。未来的发展路径清晰可见:
当然,前路依然充满挑战。数据隐私和安全是悬在所有医疗AI头上的达摩克利斯之剑。算法的公平性也至关重要,必须确保模型在不同人群、不同设备来源的数据上都能表现稳健,避免加剧而非消弭健康不平等。此外,严格的监管审批和伦理规范是AI技术从实验室走向临床应用的必经之路。
从98秒到6.2秒,改变的不仅是时间,更是诊断的范式、医生的角色和患者的命运。浙江大学金凯团队的VLS模型,让我们看到了一个AI与人类医生智慧协作的未来。在这个未来里,技术不再是冰冷的0和1,而是充满了人文关怀的温度。
它让顶尖的医疗智慧得以复制和传播,跨越山海,抵达每一个需要它的角落。这不仅是一场效率革命,更是一场深刻的公平革命。AI正在为我们描绘一幅全新的医疗图景:在那里,每一个人的光明,都值得被最先进的科技温柔守护。
点击充电,成为大圆镜下一个视频选题!