对抗知识焦虑,从看懂这条开始
App 下载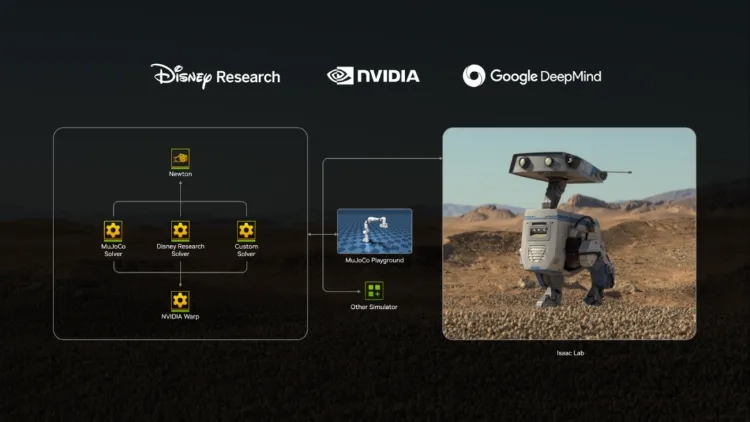
物理AI卡数据了,仿真成了新的CUDA
数字土壤|力学数据|数据瓶颈|机器人仿真|物理AI|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数字土壤|力学数据|数据瓶颈|机器人仿真|物理AI|AI智能体|人工智能
你可能没注意,AI的瓶颈已经换了。过去大模型拼算力,谁家GPU多、数据集大,谁就能领先——CUDA把GPU变成了AI的通用计算底座,攥着算力入口就攥着时代红利。但现在,当AI要走出屏幕,变成能搬东西、会走路的机器人时,卡脖子的不再是算力,而是数据。机器人要学的不是文字逻辑,是力怎么传递、东西怎么抓稳、动作错了世界会怎么反馈。这些数据没法从互联网爬,真实世界采集又贵又慢,连失败场景都难复刻。这时候,曾经的“测试工具”仿真,成了破局的关键。
你可以把机器人学走路比作小孩学骑车:摔过的跤、攥车把的力度、车身歪了怎么调整,每一次反馈都是学习的关键。但机器人没法像小孩一样随便摔——真实世界里摔一次可能就坏了,更别说要摔成千上万次找规律。 仿真就是给机器人造了个“无限重置的练习场”:它用数字模型复刻真实物理规则,小到物体表面的摩擦力,大到关节受力的极限,都能精准模拟。在这里,机器人可以无成本地重复动作,甚至能刻意制造失败场景——比如把地面换成湿滑瓷砖,把要抓的物体换成滑溜溜的鱼,把光照调到最暗,反复试错直到找到最优解。

更重要的是,仿真能规模化生产数据。传统机器人训练,可能要花几个月采集几万条真实数据;而在GPU加速的仿真环境里,一天就能生成上千万条带精准标注的物理交互数据,相当于给机器人喂了成吨的“练习册”。
当仿真的价值从“测试”转向“生产”,国际巨头们的动作比谁都快。 早在2008年,NVIDIA就收购了物理引擎PhysX,后来把它升级成Omniverse里的高精度仿真内核,支撑起Isaac Sim机器人平台;Google DeepMind在2021年拿下机器人圈的标配工具MuJoCo,直接把学术圈的默认工具攥在了手里;迪士尼研究院则盯着复杂场景,搞出了能解决闭链机构、极端工况的Kamino,专攻克隆人、复杂机器人的稳定运动难题。 但这些工具各有各的标准,数据格式不兼容,训练接口不通用,就像不同国家的人各说各的语言,没法一起干活。于是2025年,NVIDIA、Google DeepMind和迪士尼联合推出了Newton——这个开源引擎第一次把GPU并行计算、高精度动力学、复杂机构求解塞进了同一个框架,就像给不同语言的人配了统一的翻译器。 更值得注意的是,中国公司第一次站到了这个全球标准的制定桌前。光轮智能作为核心共建者加入Newton技术委员会,带着自研的“求解—测量—生成”技术,牵头优化仿真与真实世界的一致性,推动仿真资产的标准化。这是第一次,中国力量从“用工具”变成了“定规则”。
但仿真不是万能的。它和真实世界之间总有一道“模拟鸿沟”:仿真里调得完美的抓握动作,到真实世界里换个有磨损的桌面,可能就抓不住了。 为了填平这道沟,现在的玩法是“真实-仿真-真实”的闭环:先用少量真实数据校准仿真模型,让虚拟世界的物理规则更贴近现实;再在仿真里生成海量数据训练机器人;最后用真实环境的反馈再优化仿真参数。比如光轮智能的技术,就是通过自研的物理测量体系,把仿真结果和真实数据反复比对校准,让机器人在仿真里学会的技能,能直接用到工厂的流水线上。
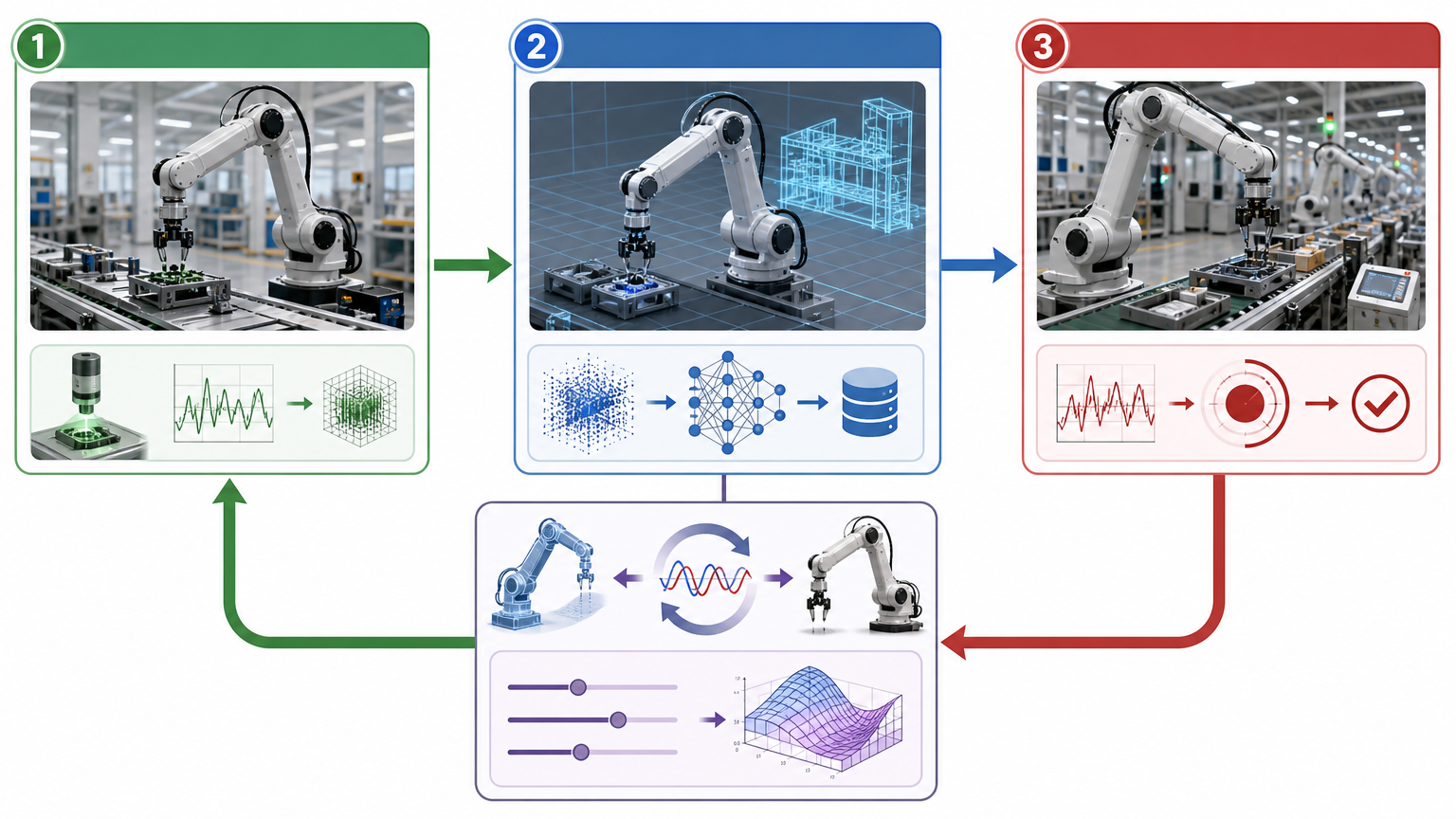
还有个更关键的问题:怎么判断机器人真的“学会”了?大模型有MMLU、HumanEval这些评测标准,但机器人要测的是“能不能在真实环境里把活干成”。这时候仿真又成了评测的基础设施——它能提供标准化、可重复的测试场景,比如让机器人在1000种不同光照、不同地面、不同物体的组合里反复执行任务,用数据量化它的能力边界,而不是只看实验室里的一次成功演示。
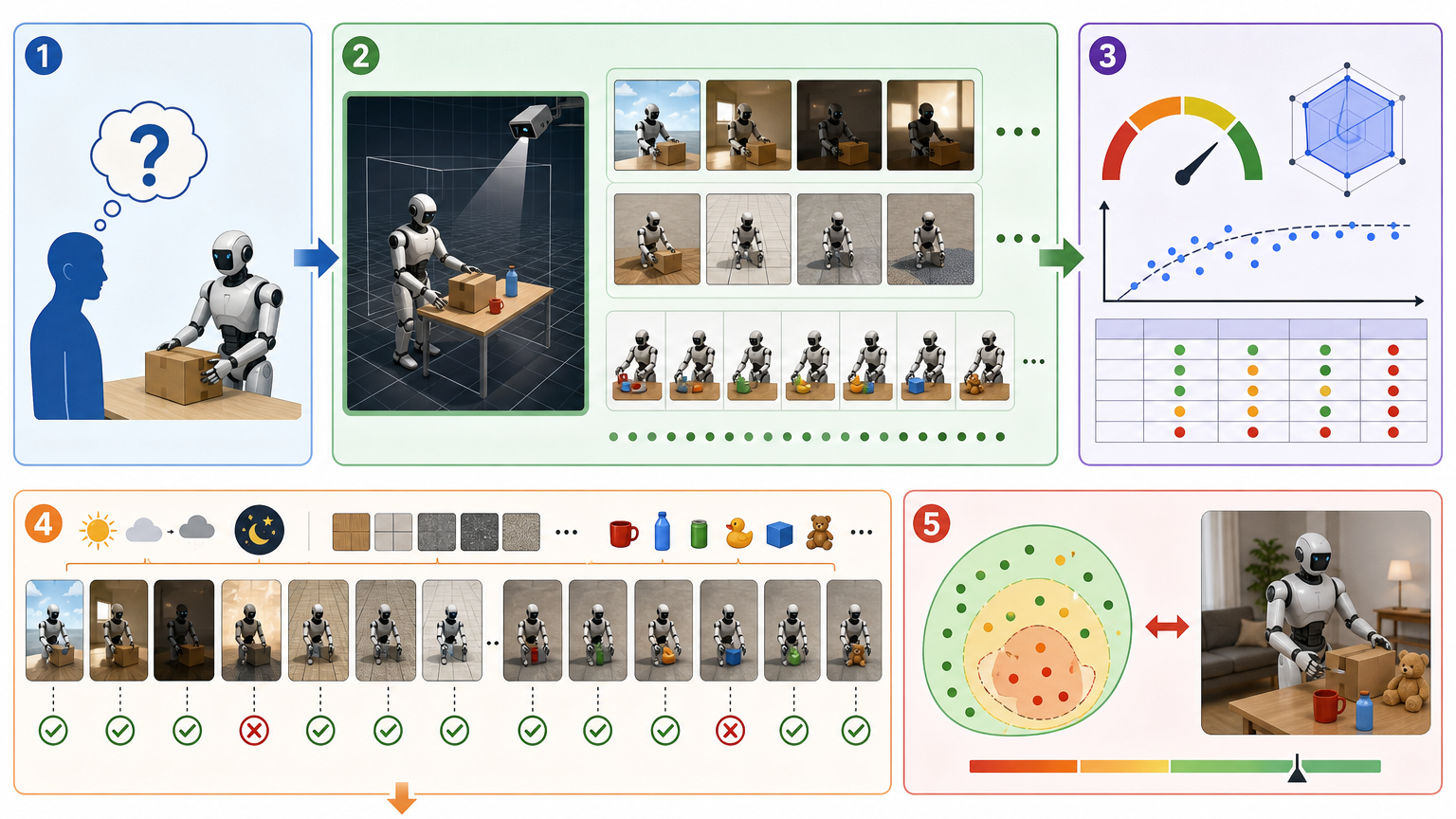
过去十年,CUDA定义了“怎么调用算力”,谁掌握了它,谁就掌握了大模型的入场券;未来十年,仿真会定义“怎么生成物理世界”,谁能造出最贴近真实、最能规模化生产数据的仿真底座,谁就掌握了物理AI的话语权。 这一次,中国公司不再是跟跑者。当光轮智能和NVIDIA、Google DeepMind坐在同一张桌子上制定标准时,意味着我们不再只是用别人的工具造机器人,而是开始参与定义机器人该怎么“理解”这个世界。 算力决定了AI能跑多快,而仿真决定了AI能走多远。