对抗知识焦虑,从看懂这条开始
App 下载
苹果用谷歌大模型,把AI塞进了iPhone
隐私保护|端侧AI|大模型蒸馏|谷歌Gemini|苹果公司|消费电子|大语言模型|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载隐私保护|端侧AI|大模型蒸馏|谷歌Gemini|苹果公司|消费电子|大语言模型|前沿科技|人工智能
想象一下,你对着iPhone说“帮我整理这篇会议纪要”,手机没亮“正在连接云端”的加载圈,半秒后就弹出了分点清晰的文本——全程没联网,你的会议录音也没离开过设备。这不是科幻场景,而是苹果正在悄悄推进的现实:它花每年10亿美元的价格,从谷歌手里拿到了Gemini大模型的“内部钥匙”,要用一种叫“大模型蒸馏”的技术,把云端AI的能力压缩成能装进口袋的小模型。为什么苹果放着现成的API不用,非要花大价钱拿这把钥匙?这背后藏着AI时代最核心的矛盾:算力、隐私和体验的三角博弈。
你可以把大模型蒸馏理解成一场特殊的教学:谷歌的Gemini是那位知识渊博但体型庞大的教授,苹果自研的小模型是坐在课桌前的学生。
教授不会直接把自己的脑子分给学生,而是通过一套精心设计的“习题集”——苹果会给Gemini投喂数千种贴合Siri需求的任务,从“帮我规划周末亲子游”到“解释这张医学报告的术语”,不仅要答案,还要完整的思考过程。学生模型就在这些习题里反复模仿:不仅要学会给出和教授一样的答案,更要学会教授是怎么一步步想到这个答案的。
这个过程的关键,是“软标签”的传递——不是简单的“对”或“错”,而是Gemini给出的概率分布:比如它判断“用户要订机票”的概率是90%,“要查航班动态”是8%,“要吐槽航空公司”是2%。这些模糊的、带灰度的信息,能让小模型学到大模型的推理逻辑,而不只是表面的答案。
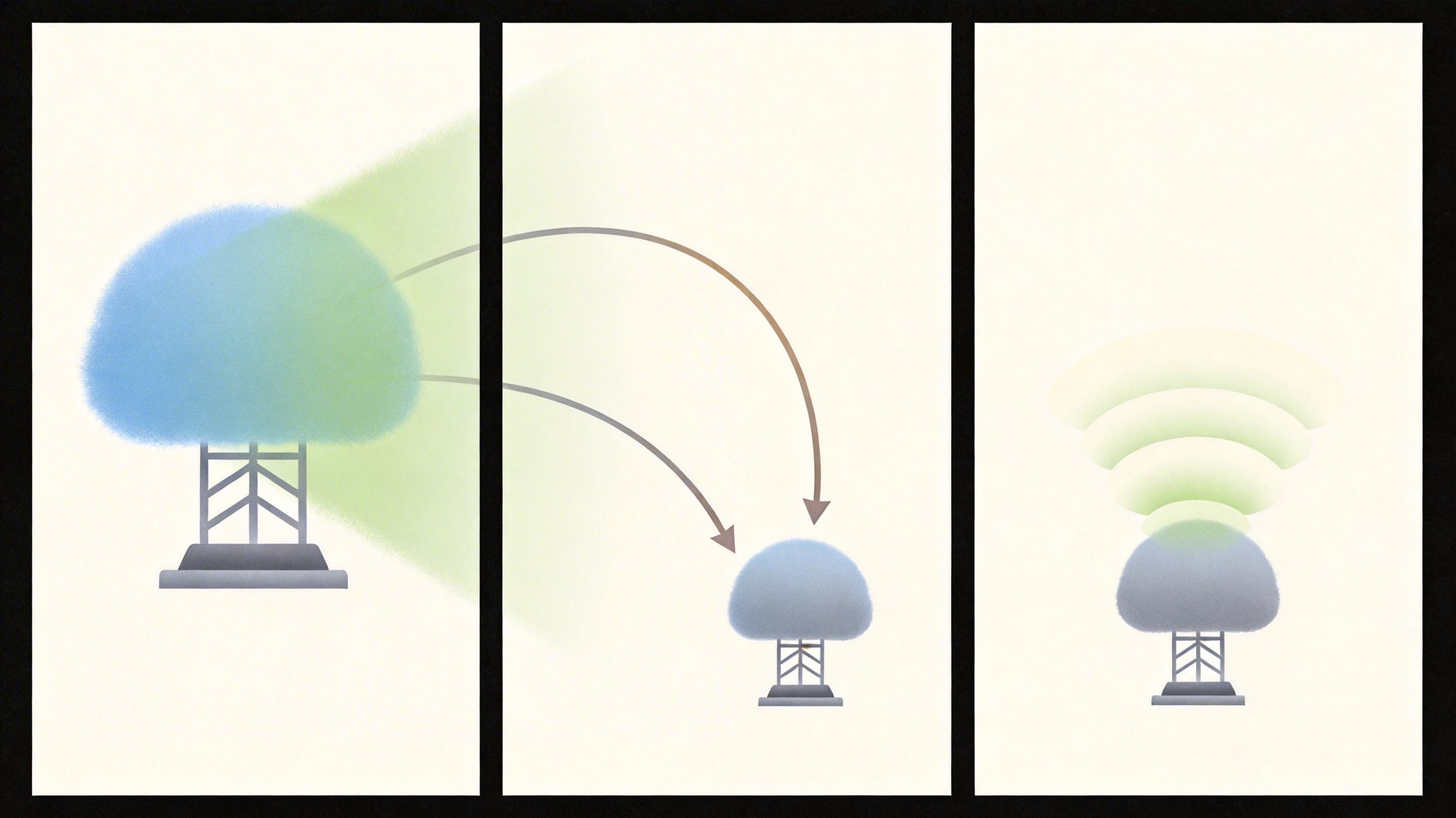
训练完成后,学生模型的体积只有老师的几十分之一,却能达到老师90%以上的性能。更重要的是,它能在iPhone的芯片上直接运行,不需要再把数据传到云端处理。
把AI从云端搬到设备端,苹果拿到的第一个好处就是隐私——你的语音指令、照片内容、文档数据,全部在本地处理,不会上传到任何服务器,从技术上杜绝了数据泄露的可能。这恰好踩中了苹果多年来的“隐私叙事”:它卖的从来不是硬件,而是“你的数据只属于你”的安全感。
第二个好处是速度。云端AI的响应速度取决于网络带宽,而本地AI的延迟可以低到毫秒级。想象一下,在没有信号的地铁里,你依然能用Siri写邮件、翻译外文,甚至生成PPT大纲——这种离线可用性,是云端AI永远给不了的体验。

但硬币总有另一面。Gemini原本是为聊天和代码生成调优的模型,而苹果需要的是能理解复杂语音指令、适配生态内所有应用的助手。双方的需求错位,让这场“教学”充满磨合:苹果要把Gemini的通用能力,掰成适合Siri的“专用技能”,这个过程需要反复调整习题集,甚至要给Gemini做“定制手术”。
更现实的挑战是性能妥协。小模型再聪明,也不可能完全复刻大模型的能力——比如处理复杂的数学推理、生成超长文本,本地模型的表现还是会逊色于云端。苹果要做的,是在“够用”和“好用”之间找到平衡点:让用户在90%的日常场景里,感受不到本地AI和云端AI的区别。
苹果的野心不止于把Siri变聪明。在即将到来的WWDC 2026上,它计划推出一套“Extensions”系统——允许用户把ChatGPT、Claude等第三方AI接入Siri。这意味着Siri不再是一个单一的助手,而是变成了一个AI的“路由器”:用户可以根据不同的任务,选择不同的AI来完成。
这种开放姿态,背后是苹果对AI生态的布局:它不想做AI的生产者,而想做AI的“管理者”。通过蒸馏技术,它把谷歌的能力变成自己的“打底技能”,再通过开放平台引入更多第三方AI,最终形成一个“以我为主”的AI生态。
但这也带来了新的问题:当多个AI在同一台设备上运行,如何保证它们的兼容性?如何避免用户陷入“选择困难”?更重要的是,苹果如何在开放和隐私之间保持平衡——第三方AI会不会获取用户的本地数据?这些问题,都是苹果在接下来的一年里需要解决的。
从PC时代的“Wintel联盟”,到移动时代的iOS生态,苹果一直擅长用别人的技术,做自己的体验。这次和谷歌的合作,不过是这种策略的延续:用10亿美元的“学费”,快速补上自己的AI短板,再用蒸馏技术把能力本地化,最终把体验牢牢握在自己手里。
AI的未来,从来不是“越大越好”,而是“越合适越好”。当大模型的算力瓶颈越来越明显,把AI能力从云端搬到掌心,或许才是真正贴近用户需求的方向。毕竟,用户想要的从来不是一个能回答所有问题的云端大脑,而是一个懂自己、守秘密、随时能用的贴身助手。
AI的终极形态,是装进口袋的安全感。