对抗知识焦虑,从看懂这条开始
App 下载
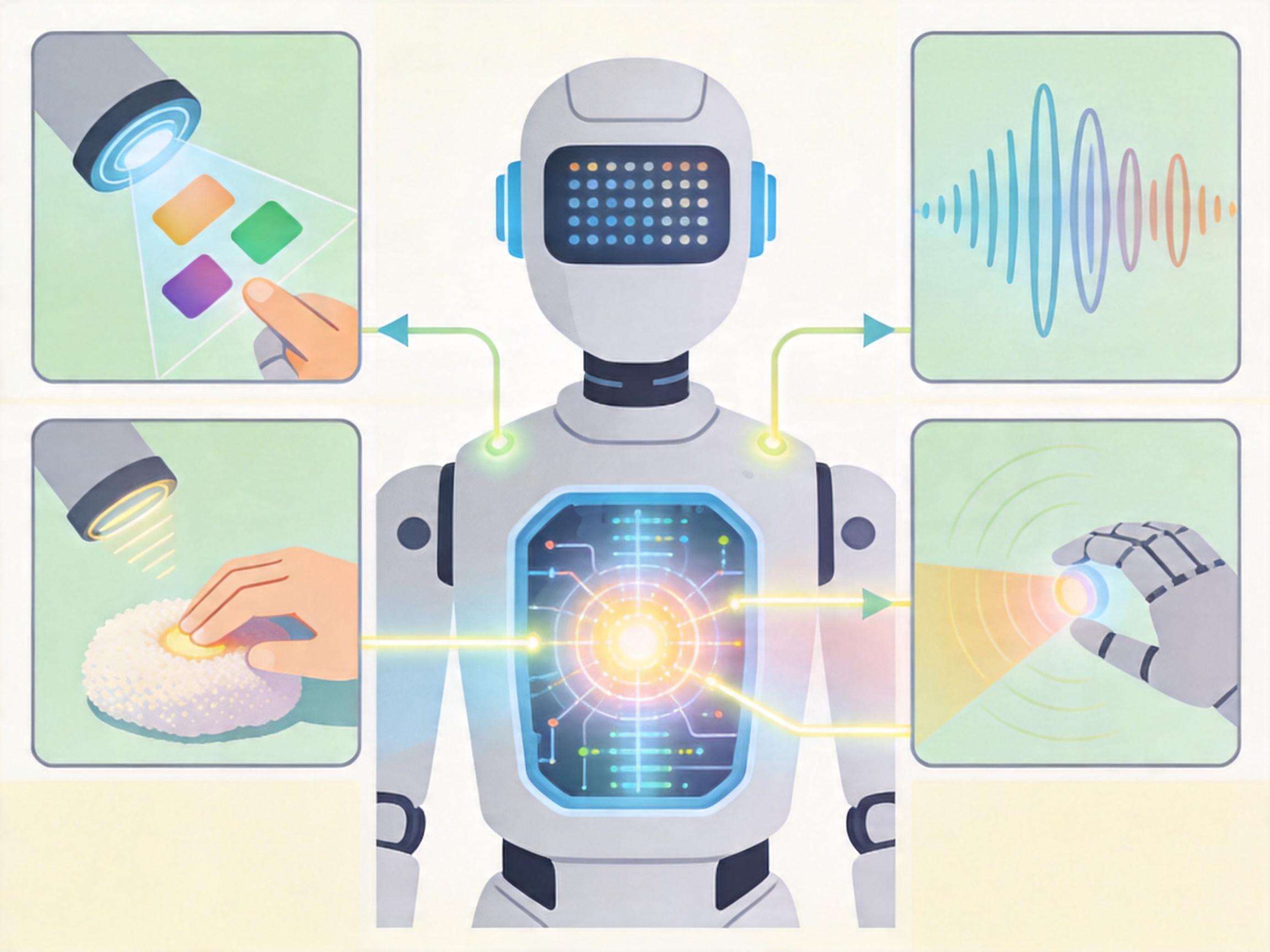
机器人不靠单眼单耳,靠全感官做决策
自主决策系统|传感器融合|多模态感知|人形机器人|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自主决策系统|传感器融合|多模态感知|人形机器人|多模态视觉|人工智能
当货架上最后一盒牛奶被取走,当流水线上的零件精准卡入卡槽,当厨房里的锅铲自动翻转食材——你以为是人类在操控?不,是一台人形机器人在调动它的眼睛、耳朵、指尖甚至关节的“感官”,自主完成这一切。上海一场行业大会上,有团队展示了这项技术的落地:多模态感知与AI决策系统的融合,正在让机器人跳出“预设指令执行者”的框架,成为能应对真实商业难题的协作伙伴。为什么这会是比“机器人会走路”更重要的突破?我们得从技术的底层逻辑说起。
多模态感知,说白了就是给机器人装上一套“全感官系统”——不是单一的摄像头,而是融合视觉、触觉、听觉、惯性测量等多种传感器数据。比如视觉能识别物体的颜色和形状,触觉能感知它的软硬和重量,听觉能捕捉环境里的异常声响。这些数据不再是各自为政的信息流,而是会被统一校准、同步,像人类的大脑整合五感信息那样,拼凑出完整的环境图景。这就解决了单一传感器的致命缺陷:摄像头在昏暗环境里会“失明”,但触觉传感器能靠压力感知继续工作;激光雷达能精准测距,却没法分辨物体的材质,视觉数据刚好能补上这个缺口。
而AI决策系统,就是机器人的“大脑”,它要做的不是简单匹配预设指令,而是基于多模态感知到的实时信息,动态调整行动策略。这里的关键是“闭环协同”:机器人每做出一个动作,多模态传感器就会把执行结果反馈回决策系统,比如“抓取时压力过大,物体可能变形”,决策系统就会立刻调整抓取力度,形成“感知-决策-执行-再感知”的循环。这有点像人类学用筷子:一开始会夹不稳,手指的触觉会把“滑”“松”的信号传给大脑,大脑再调整手指的力度,直到能稳稳夹起食物。机器人的学习过程,本质上就是这个闭环不断优化的过程。
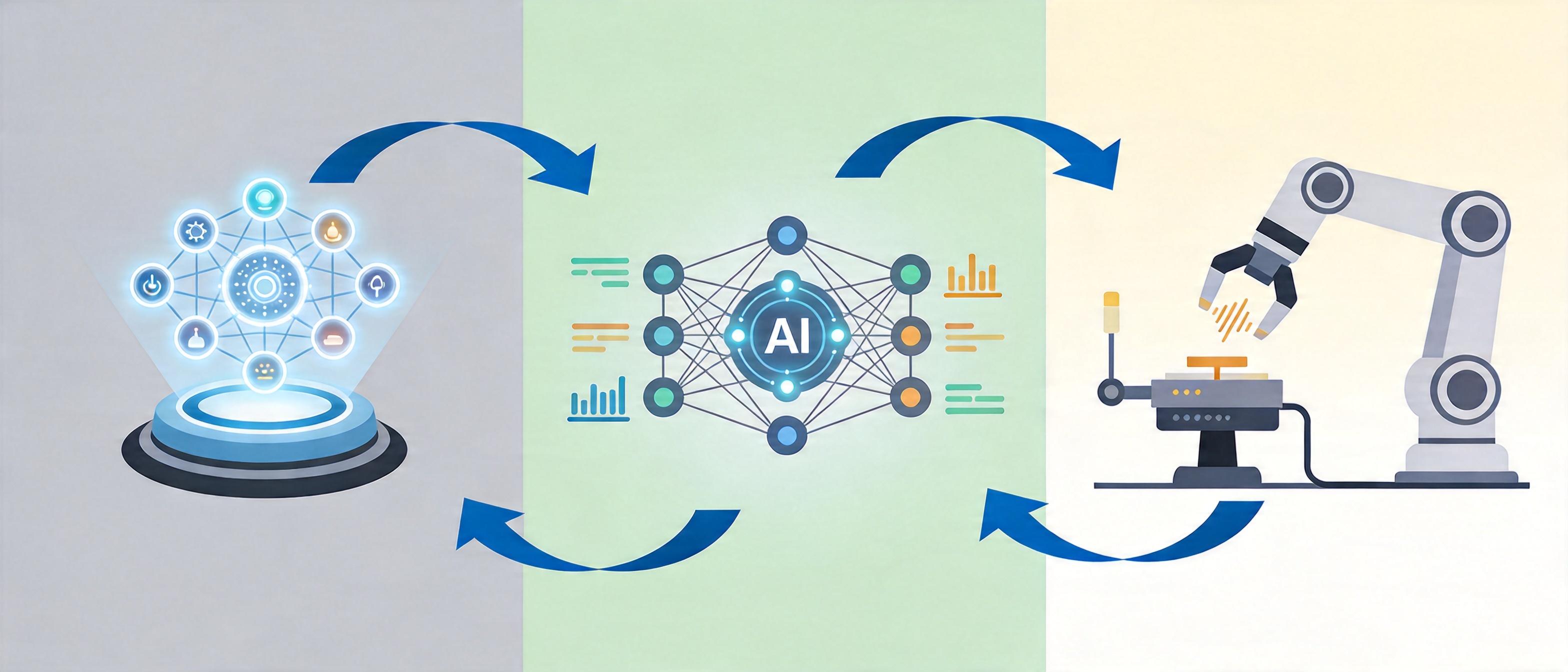
但这项技术的落地,还面临着不少现实挑战。首先是数据同步的难题:不同传感器的采样频率、数据格式各不相同,要把它们精准对齐,就像让不同节奏的乐器合奏出和谐的曲子,难度不小。其次是标注成本,多模态数据的标注需要跨领域的专业知识,比如要同时给视觉图像、触觉压力数据做统一的动作标注,耗时又耗力。更重要的是,当前的AI决策系统还缺乏真正的“推理能力”,它能根据已有数据做出最优选择,但面对完全陌生的场景,可能还是会陷入混乱。
不过,这些挑战并没有阻挡技术落地的脚步。在无人化工厂里,融合了多模态感知的机器人能在嘈杂、昏暗的环境里精准完成装配任务;在智慧零售场景中,它能通过视觉识别货架空缺,通过触觉抓取不同重量的商品,还能通过听觉响应顾客的询问。这些真实场景的应用,正在反过来推动技术的迭代——每一次成功的抓取、每一次精准的导航,都会变成训练数据,让机器人的“大脑”越来越聪明。
从依赖单一感官到整合全感官,从执行预设指令到自主闭环决策,机器人正在从“工具”向“伙伴”靠近。未来的智能社会里,它们或许不会像科幻电影里那样拥有自我意识,但一定会成为人类最可靠的协作伙伴,在那些重复、危险、高精度的任务中,释放人类的创造力。这不是对人类的替代,而是技术对人类能力的延伸与补充。