
7 天前
7 天前
想象你要做一段视频:让古装侠客在中世纪城堡里舞剑,镜头还得绕着他旋转。以前你改个动作,侠客脸可能变了,城堡墙也歪了——就像给演员换动作,结果拆了影棚还换了人。现在,新加坡国立大学和百度的团队把这个难题给拆明白了:他们让AI把人、景、动作、镜头彻底分开,像拼乐高一样随便组合,还能生成分钟级的长视频。这到底是怎么做到的?
你可以把传统视频生成模型想象成一个混乱的片场:演员、布景、摄像机挤在一起,动一个就得全挪。以前的解法是硬拉着所有人在3D坐标系里对齐,不仅要提前搭好复杂的3D场景,还容易把动作卡死,生成的视频僵硬得像木偶戏。
ONE-SHOT换了个思路:先给动作单独建一个“标准摄影棚”——也就是规范空间。不管你要的是舞剑还是跑步,所有动作都先在这个棚里“摆正”:人物占满画面90%,正面朝向镜头,和任何具体场景都不绑定。就像演员先在绿幕棚里把动作练熟,再后期合成到任何场景里。
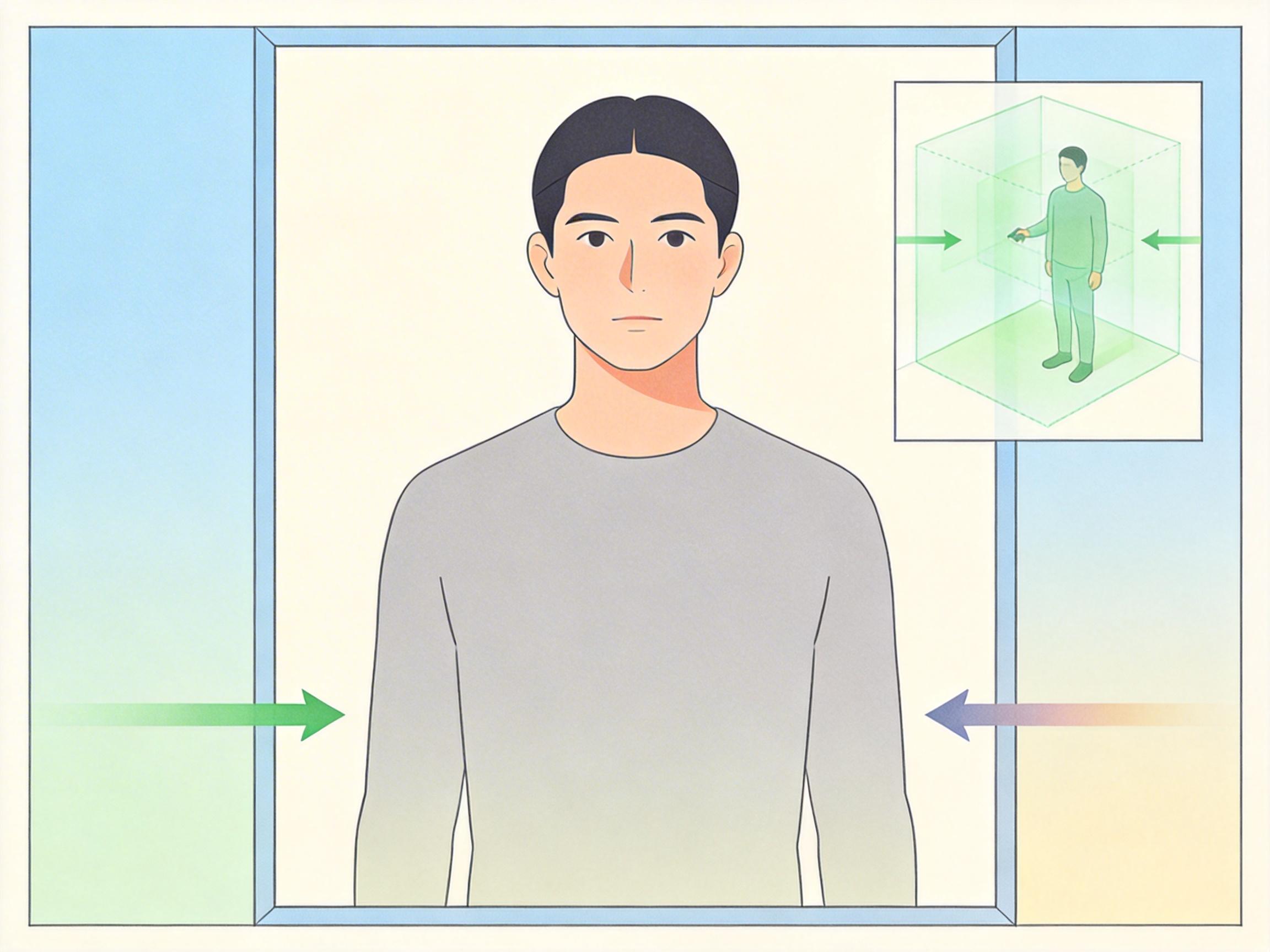
但真实的机制比这更精确:模型把动作信号编码在这个独立空间里,再通过专用的交叉注意力层,像翻译一样把动作信息“注入”到视频生成的特征中。这一步,彻底把动作和环境从物理上拆成了两个独立模块,改动作再也不会碰歪布景了。
动作在标准棚里,视频画面在真实场景里,怎么让它们对上位置?ONE-SHOT拿出的工具是动态锚定RoPE——一种给特征打“位置烙印”的技术。
你可以把它想象成手机地图的缩放:当你把地图放大到自己所在的小区,原本的街道坐标会自动适配成小区楼号。动态锚定RoPE做的就是这件事:它先找到视频里人物所在的粗略区域,再根据这个区域的大小,动态缩放动作的位置编码,让棚里的动作和画面里的人物位置严丝合缝。背景区域则被统一标记成“无关区”,彻底避免动作信号干扰布景。
直给补刀:它完全跳过了复杂的3D坐标计算,只在2D图像层面做动态匹配,计算量骤降的同时,对齐精度反而更高。实验显示,去掉这个模块后,视频的FID(画质指标)会直接恶化30%以上,动作跟随完全混乱。
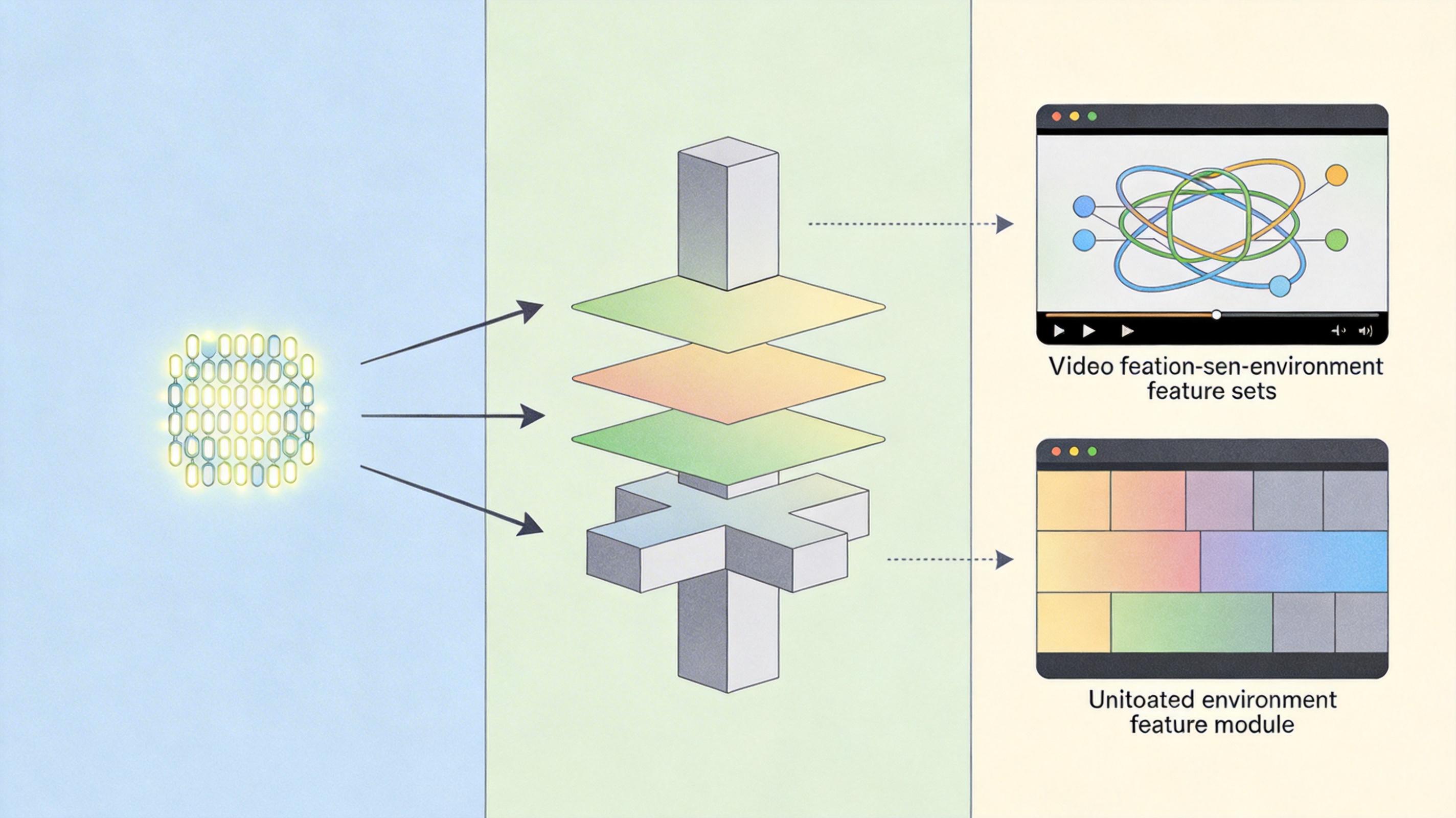
要生成分钟级的长视频,还有个麻烦:AI容易“失忆”——生成到第100帧,侠客的脸可能慢慢变成路人,城堡的墙也换了颜色。ONE-SHOT给AI装了两个记忆模块:
长期记忆靠几张静态的人物参考图,就像给AI贴了张演员的定妆照,不管镜头怎么转,核心长相和服饰纹理都不会变;短期记忆则是动态更新的历史帧片段,AI每生成几帧就回头看看,确保动作连贯、场景一致。比如镜头绕侠客转了一圈回到原位,AI会参考之前的帧,保证侠客的脸和城堡的光影和之前完全匹配。
在Traj100数据集的测试中,ONE-SHOT的FVD(视频连贯性指标)比主流方法低了20%以上,长视频的身份漂移率降到了几乎可以忽略的程度。
当我们还在惊叹AI能生成逼真画面时,ONE-SHOT已经把注意力转向了“可控”——这才是AI从“生成工具”变成“创作伙伴”的关键。它没有在3D建模的复杂道路上死磕,而是用模块化的思路,把视频生成拆成了人人都能看懂的“搭乐高”。
解耦,才是AI创作的自由开关。未来的视频创作,可能不再是导演对着分镜稿苦思冥想,而是像玩沙盒游戏一样,把人物、场景、动作随手组合,剩下的交给AI完成。技术的终极目标,从来都是把复杂的权力,交回给创作者。
点击充电,成为大圆镜下一个视频选题!