对抗知识焦虑,从看懂这条开始
App 下载
极端噪音里听清话,靠的是骨头和空气的配合
极端噪音环境|军事科学院|语音清晰度|气导听觉|骨导听觉|神经生物学|生命科学
对抗知识焦虑,从看懂这条开始
App 下载极端噪音环境|军事科学院|语音清晰度|气导听觉|骨导听觉|神经生物学|生命科学
想象你站在工地中央,电钻声像锤子砸在耳膜上,同伴凑到你耳边喊的话,全成了模糊的嗡嗡声。这时候你捂住耳朵,把手指按在他喉咙上——奇怪的事发生了,那些被噪音淹没的字句,居然顺着骨头传到了你的脑子里。这不是魔术,是人类自带的两套听觉系统:靠空气传声的「气导」,和靠骨头传声的「骨导」。2026年3月,军事科学院的团队把这两套系统的潜力挖到了极致,让极端噪音里的语音清晰度,第一次实现了质的突破。为什么单独用其中一套都不行?他们到底做了什么?
先把这两套系统拆透:气导就是我们平时用耳朵听声音——声波穿过空气,撞进耳膜,再传到内耳。它的优点是「细腻」,能捕捉到说话人语气里的细微变化、辅音里的高频细节,听起来自然又清晰;但缺点也致命,环境噪音会和语音一起钻进耳朵,在信噪比低于-10dB的极端环境里,目标语音会直接被噪音「淹没」。
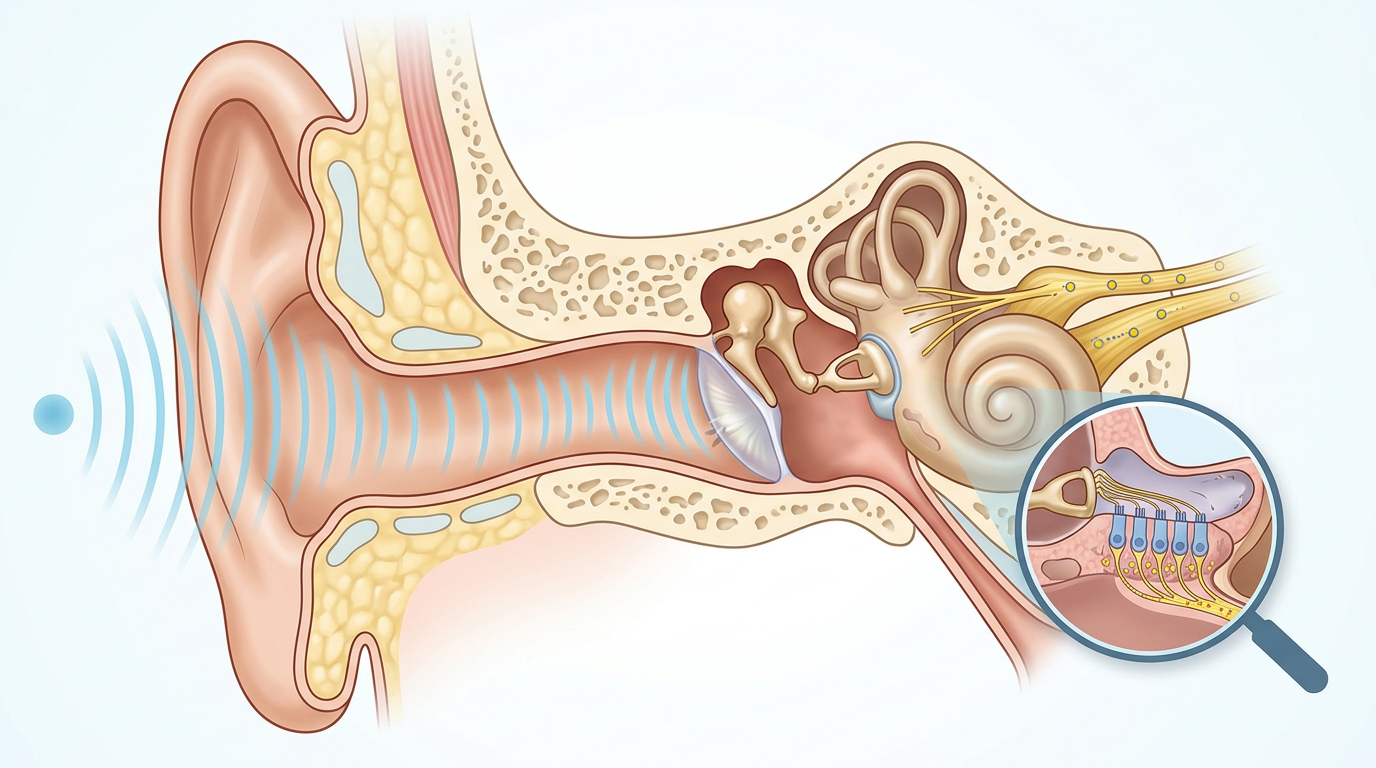
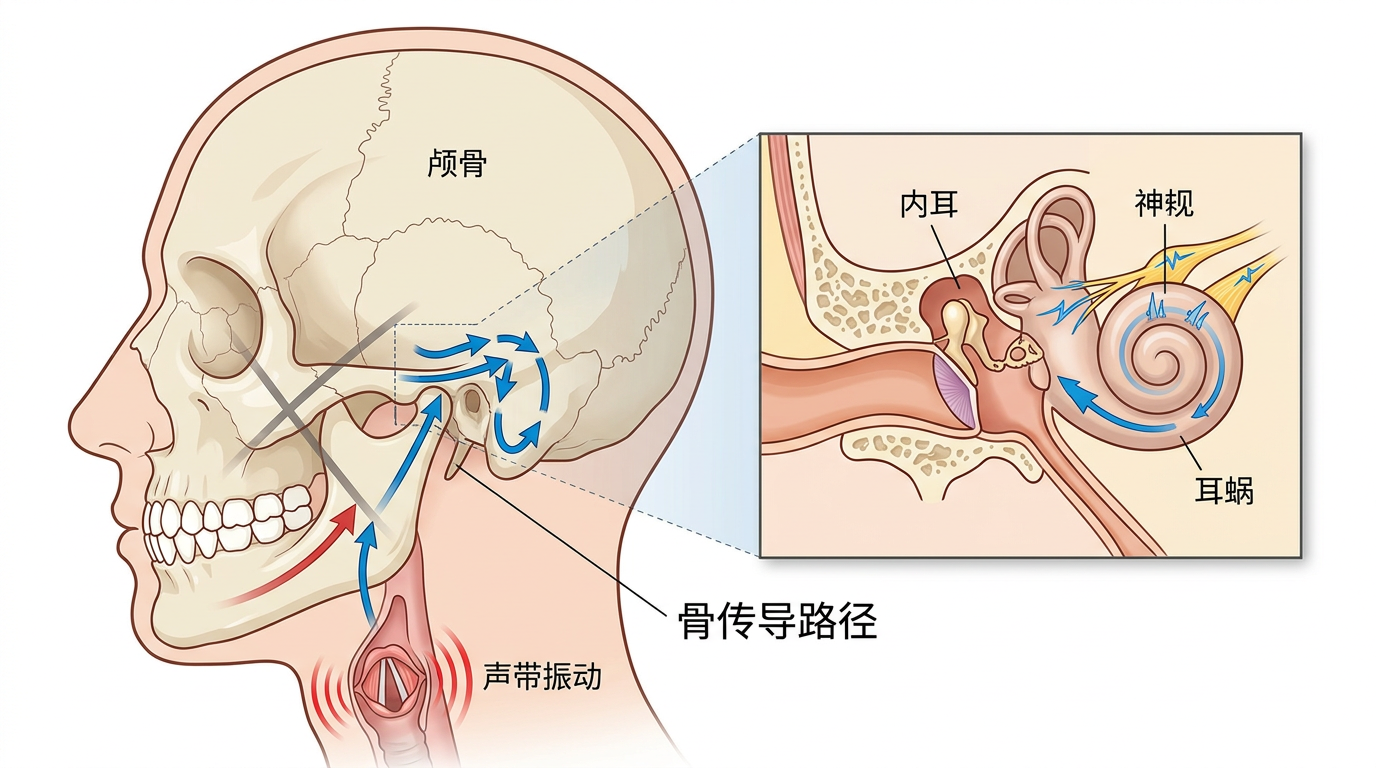
骨导则是另一条路:声带振动直接通过颅骨传到内耳,完全绕开空气。你捂住耳朵自己说话,听到的就是骨导声音——它天生「抗造」,工地的电钻声、马路上的喇叭声,根本干扰不到颅骨里的振动;但代价是「粗糙」,高频细节几乎损失殆尽,听起来像隔着厚棉被说话,连「s」「sh」都分不清楚。
既然一个细但弱,一个粗但刚,把它们凑一起不就完美了?过去的研究者也是这么想的,但结果总是差强人意——在极端噪音下,模型会本能地「偷懒」:既然骨导信号更稳定,就干脆放弃气导里那点微弱的细节,最后输出的语音还是闷得像瓮声瓮气的嘟囔。这就是「模态失衡」,也是过去多模态语音增强的死穴。
军事科学院团队提出的DBMIF框架,核心就解决了一个问题:怎么让气导和骨导「平等合作」,而不是一方躺平一方包办。
它的结构像一个三方议事的会议室:三个分支分别处理气导、骨导和融合信号,每一层都通过「跨分支门控交互模块」(CBGI)双向沟通——融合分支会根据当前噪音情况,给气导和骨导分支发「指令」:噪音大的时候,让气导分支专注保留仅存的高频细节,骨导分支负责稳住语音骨架;噪音小的时候,再让气导分支主导,骨导分支做补充。反过来,气导和骨导分支也会把自己的「难处」反馈给融合分支:比如气导分支发现某个频段全是噪音,就会主动降低这个频段的权重。
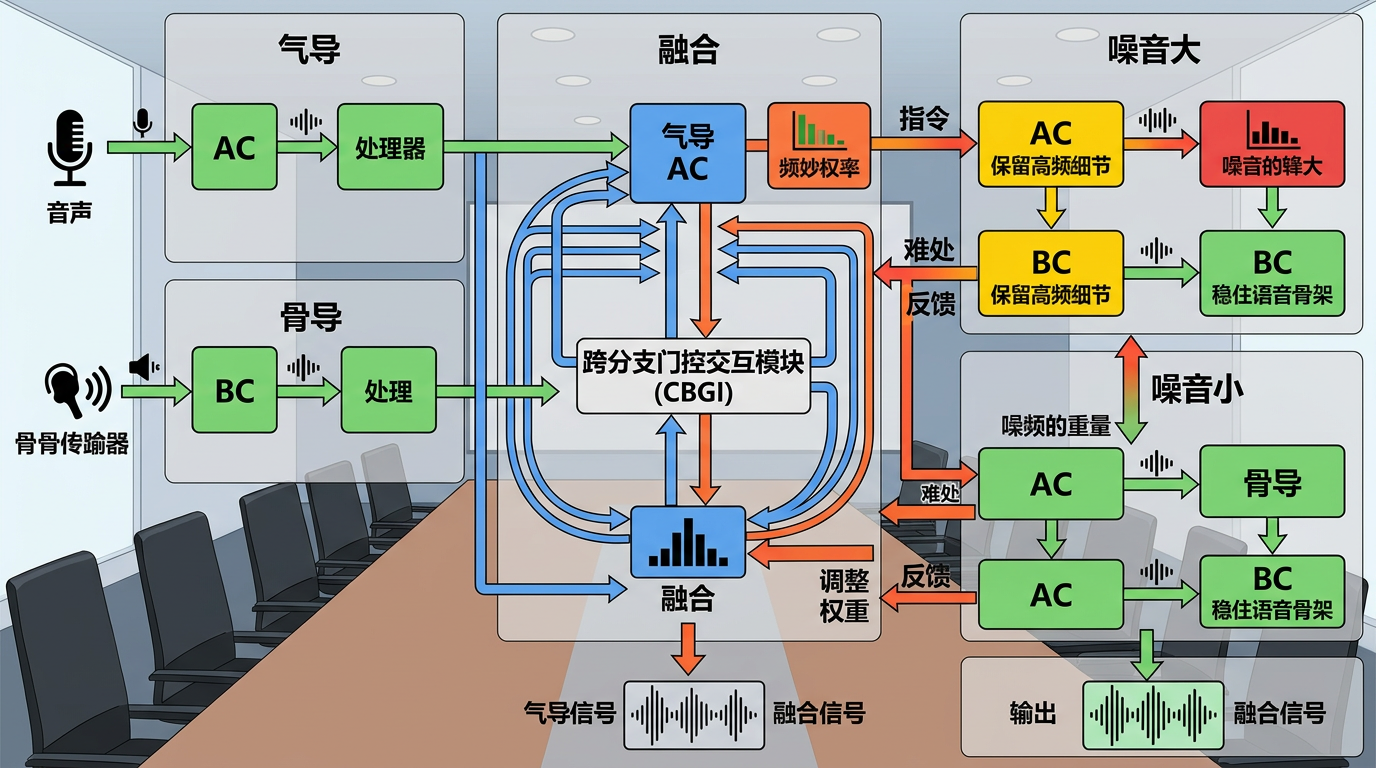
在进入正式处理前,还有一个「深度迭代注意力融合模块」(DIAF)当「调解员」:它会先把两种信号简单混合,再通过三轮迭代评估,给每个频段分配动态权重——比如在-10dB的噪音下,低频段几乎全靠骨导,权重会倾向0;而高频段哪怕气导信号很弱,也会保留一点权重,确保那些关键的细节不丢失。
最关键的是瓶颈层的「深度平衡交互模块」(DBI):它像一个反复磋商的会议,让三个分支的信号不断迭代优化,直到达到一个稳定的「不动点」——也就是两种信号的贡献刚好平衡,既不会让骨导的闷感盖过细节,也不会让气导的噪音干扰整体。这个过程最多要迭代50次,但最终输出的语音,终于既有骨导的抗噪性,又有气导的清晰度。
实验室里的指标最能说明问题:在-10dB的极端噪音环境下,DBMIF的语音质量指标(PESQ)比传统方法提升了0.8分,可懂度指标(STOI)提升超过20%——这个差距,相当于从「完全听不懂」到「能清楚分辨每一句话」。更重要的是下游的语音识别任务,它把字符错误率(CER)降低了至少2.5%,这意味着在嘈杂环境下,语音助手、对讲机的识别准确率能上一个大台阶。
但它离真正落地还有几道坎:首先得同时采集气导和骨导信号,这就要求设备必须同时装普通麦克风和骨传导传感器,还要保证两个传感器的时间完全同步;其次,迭代模块带来的计算量,目前还很难在手机、耳机这类边缘设备上实现实时处理;最后,对于骨导信号本身的失真——比如传感器没戴紧导致信号微弱,模型的鲁棒性还需要进一步验证。
不过这些问题,反而指向了更明确的方向:未来的研究重点会放在模型轻量化上,比如用知识蒸馏把大模型压缩成适合边缘设备的小模型;或者研究异步信号的对齐方法,降低对硬件同步的要求。
我们总说「科技让生活更美好」,但真正的突破,往往是先解决那些「极端场景」里的难题——比如战场上的士兵需要听清指令,比如嘈杂工厂里的工人需要和同伴沟通,比如听力障碍者需要在人群里听清对话。DBMIF的意义,不止是让极端噪音里的语音更清晰,更是让我们看到了多模态融合的核心:不是简单的「1+1」,而是让不同的系统学会「配合」,各自发挥最大的优势。
「好的融合,从来不是强者主导,而是各尽其职。」这句话放在语音增强里成立,放在任何需要协作的场景里,或许都成立。未来的智能设备,或许不会再追求「单一功能的极致」,而是会像人类的感官系统一样,靠不同模块的默契配合,应对复杂多变的真实世界。