对抗知识焦虑,从看懂这条开始
App 下载
给AI做动态“节流”,推理速度翻3倍还不丢精度
推理加速|数学推理任务|LLaDA-8B模型|动态节流系统|大语言模型|人工智能
当你对着AI提问“解这道几何题”,它要在后台完成几十轮全序列计算——从第一个词到最后一个词,每一轮都要重新过一遍所有模型层,哪怕大部分内容根本没变化。哈尔滨工业大学(深圳)、华为和深圳河套学院的团队,把这个“笨办法”给改了。他们给AI加上了一套动态“节流”系统,在LLaDA-8B模型的数学推理任务上,让AI每秒生成的Token数从8.32个跳到37.29个,提速4.48倍的同时,答案准确率几乎没降。更关键的是,这套方法不用重新训练模型,拿来就能用。问题是,他们到底怎么让AI学会“偷懒”的?
先搞懂:AI为什么越算越慢?
要理解这套方法的妙处,得先明白扩散大语言模型(dLLMs)——就是那种能并行生成文本的AI——为什么实际推理起来比理论慢很多。
你可以把AI的每一层模型想象成一个加工厂:浅层负责处理基础语义,比如“这是一道数学题”;深层负责抠细节,比如“三角形的高怎么算”。传统的加速方法会给所有加工厂配一样的“原材料更新额度”,不管它处理的内容变没变,每一轮都要把所有原材料换一遍。
但实际情况是,浅层加工厂的内容几轮下来都不会有大变化,深层加工厂的内容却每轮都要大改。统一更新就像给每天只需要换一次货的小卖部,硬塞了和大型超市一样的补货量——不仅浪费运力,还耽误了真正需要补货的地方。
更糟的是固定阈值的并行解码:就像给AI定了个及格线,只要某个词的置信度超过60%就直接定下来。但有些词刚开始看起来像对的,后面发现是错的,“过早锁定”会导致连锁错误;而有些词明明已经100%确定,却因为没到及格线还要反复计算。
动态“节流”:给AI的算力做“精准配送”
这套叫Dynamic-dLLM的系统,核心就是解决“算力浪费”和“错误锁定”这两个问题,用了两个关键方法:动态缓存预算分配(DCU)和自适应并行解码(APD)。
先看动态缓存预算分配。它会先给每一层模型“体检”:计算相邻两轮中,每个词的特征变化程度——用余弦距离来量化,就像对比两张图片的相似度。然后把有限的缓存更新额度,全部分配给变化最剧烈的深层模型,浅层模型则只更新那些必须改的部分。
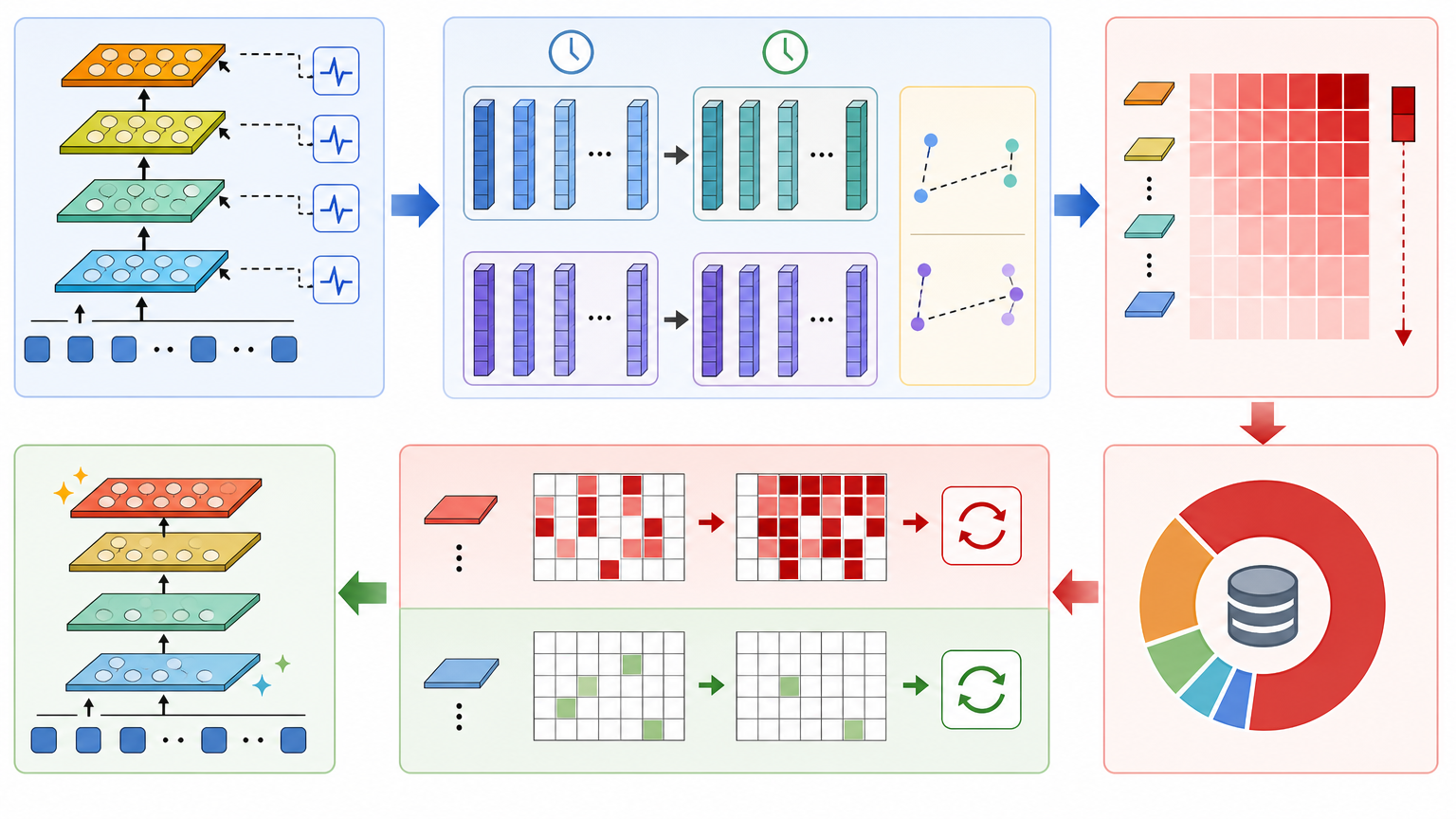
为了防止有些词“躺平”——比如某个词一直没被更新,导致后面的模型都以为它不需要改——系统还加了个“强制更新窗口”:每过一定轮数,就强制更新关键位置的词,确保AI不会漏掉重要的上下文变化。
再看自适应并行解码。它给每个词单独定“及格线”:如果某个词的最高概率和次高概率差得很远——比如“三角形”的概率是99%,“圆形”是1%——就直接降低及格线让它提前锁定;如果某个词的概率分布很分散——比如“高”和“底”的概率都是45%——就提高及格线,让AI再想想。同时还会参考这个词之前几轮的变化,如果它一直摇摆不定,就再加严及格线,避免过早犯错。
说人话就是:让该快的地方快,该慢的地方慢,把算力用在刀刃上。
不止是提速:更懂AI的“动态调度”
在LLaDA-8B、Dream-v0-7B等3个主流模型,以及数学推理、代码生成等5个任务的测试中,这套系统都拿到了当前最好的结果。跨任务平均提速3倍以上,在某些任务上甚至能达到4.48倍的吞吐量提升,而准确率几乎没有损失。
和其他加速方法比,它的优势在于“动态”。比如之前的Fast-dLLM用的是固定的缓存块和阈值,在遇到复杂任务时,要么因为更新不及时丢了精度,要么因为更新太频繁浪费算力;而Dynamic-dLLM能根据每一轮的实际情况调整策略,就像给AI配了个实时的“算力调度员”。
当然它也有局限:目前只针对扩散大语言模型,而且在超长篇文本生成时,内存占用还是会随着文本长度增加而上升。但它最大的价值在于,找到了一种不用重新训练模型就能大幅提速的方法——这意味着现有的扩散模型,都能直接用上这套系统,不用再花几百万GPU小时重新训练。
当我们都在盯着AI的训练数据大小、模型参数数量时,Dynamic-dLLM的出现提醒了我们:有时候,让AI更聪明不一定是给它塞更多知识,而是让它学会更高效地使用已有的能力。
就像人类解决复杂问题时,不会每一步都重新梳理所有信息,而是会记住关键部分,把精力放在需要调整的地方。AI的进化,也正在从“堆参数”转向“提效率”——从追求“能做更多事”,到追求“把事做得更快”。
算力不是无限的,但对效率的优化是无限的。