对抗知识焦虑,从看懂这条开始
App 下载
90%视觉Token可丢弃,多轮对话AI不再卡壳
多轮视觉对话|视觉Token压缩|阿里巴巴团队|浙江大学|MetaCompress框架|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载多轮视觉对话|视觉Token压缩|阿里巴巴团队|浙江大学|MetaCompress框架|多模态视觉|人工智能
你有没有过这种经历:对着AI问完一张照片里的人物,刚想追问背景的老建筑,屏幕突然卡住——要么加载半天给出答非所问的结果,要么干脆提示“资源不足无法继续”。这不是你的网络问题,而是AI在处理多轮视觉对话时的通病:每一轮新提问,都要带着上一轮所有的视觉信息重新计算,Token越攒越多,算力像被塞进了膨胀的气球。
现在有人把这个气球戳破了。浙江大学与阿里巴巴团队提出的MetaCompress框架,能在扔掉90%视觉Token的同时,让AI准确接住你所有的后续提问。这不是简单的“删东西”,而是彻底改写了AI保存视觉信息的规则。
要理解这个问题,得先搞懂什么是视觉Token——你可以把它看成AI给图片每一个细节贴的“标签”,比如人物的头发、背景的窗户、墙角的花盆。现在的AI为了看清细节,会生成几千个这样的标签,而Transformer模型的计算量,是和标签数量的平方成正比的。
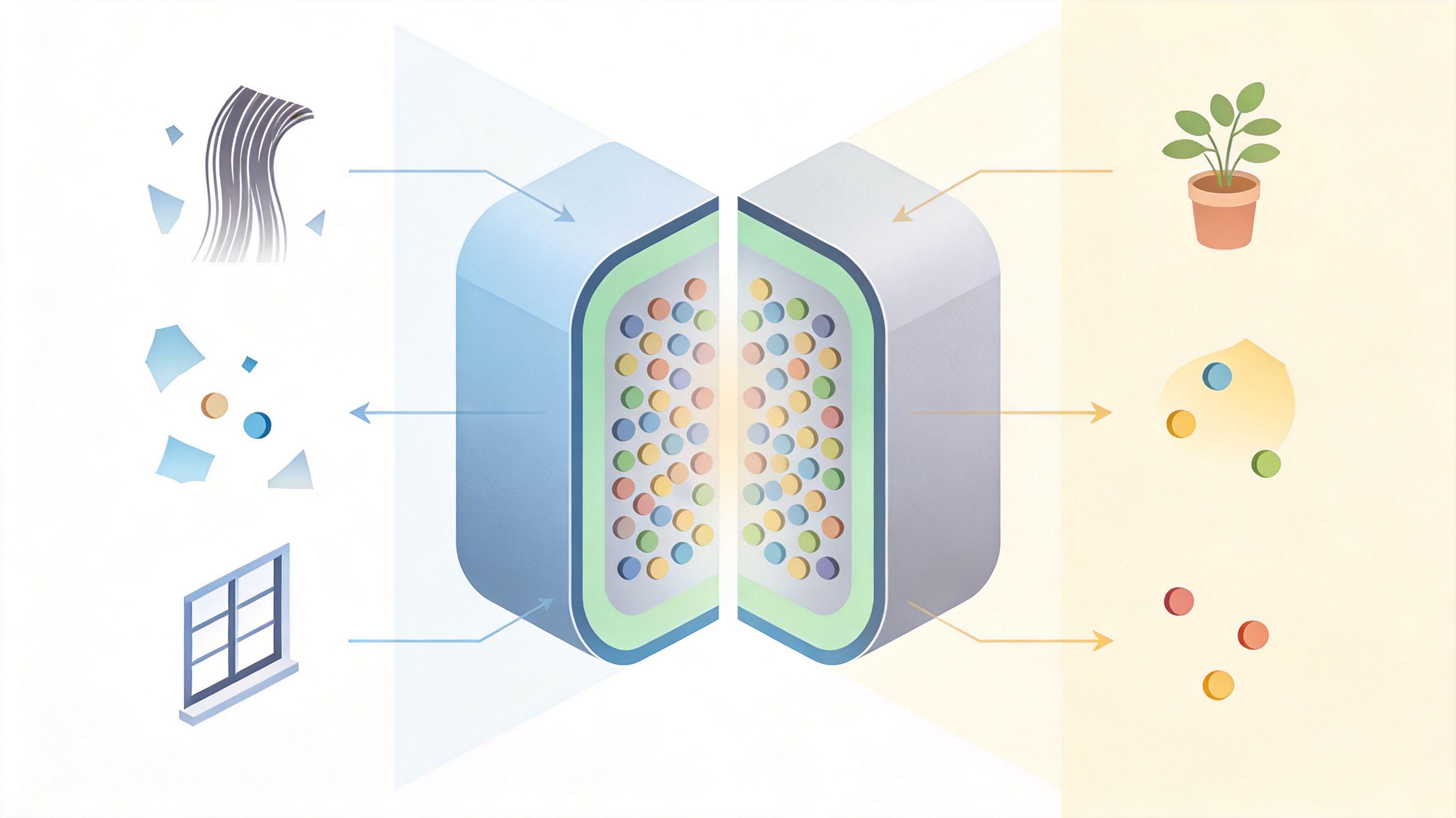
单轮提问时还好,AI可以只盯着和问题相关的标签,比如问人物就只留人物的标签。但多轮对话不一样:你可能先问前景的猫,再问猫身后的书架,最后问书架上某本书的颜色。AI根本猜不到你下一秒会关注哪里。
之前的压缩方法要么“鼠目寸光”——只保留第一轮提问相关的标签,后面问别的就抓瞎;要么“凭感觉删”——根据AI自己的注意力分数挑标签,结果发现那些被认为“不重要”的标签,恰恰是后续提问的关键。实验数据更扎心:最优保留的标签里,只有1.71%是高注意力分数的。

MetaCompress的核心逻辑,是把“删标签”从“凭经验选”变成“让AI自己学”。
团队给AI定了一个明确的目标:找到一套最优的压缩规则,让压缩后的图片标签,能在回答任意问题时,和没压缩的标签给出几乎一样的结果。为了实现这个目标,他们设计了一个轻量级的“元生成器”——它会根据每张图片的特点,自动生成对应的压缩方案,就像给不同的照片定制不同的“精简说明书”。
这个元生成器有三个关键设计:一是能适配不同分辨率的图片,不管你给的是高清图还是缩略图,它都能算出合适的压缩比例;二是完全靠数据驱动,不用人设定“什么重要什么不重要”,AI会从训练数据里学会判断哪些标签是多轮对话里的“潜力股”;三是本身几乎不占算力,不会为了压缩反而增加负担。
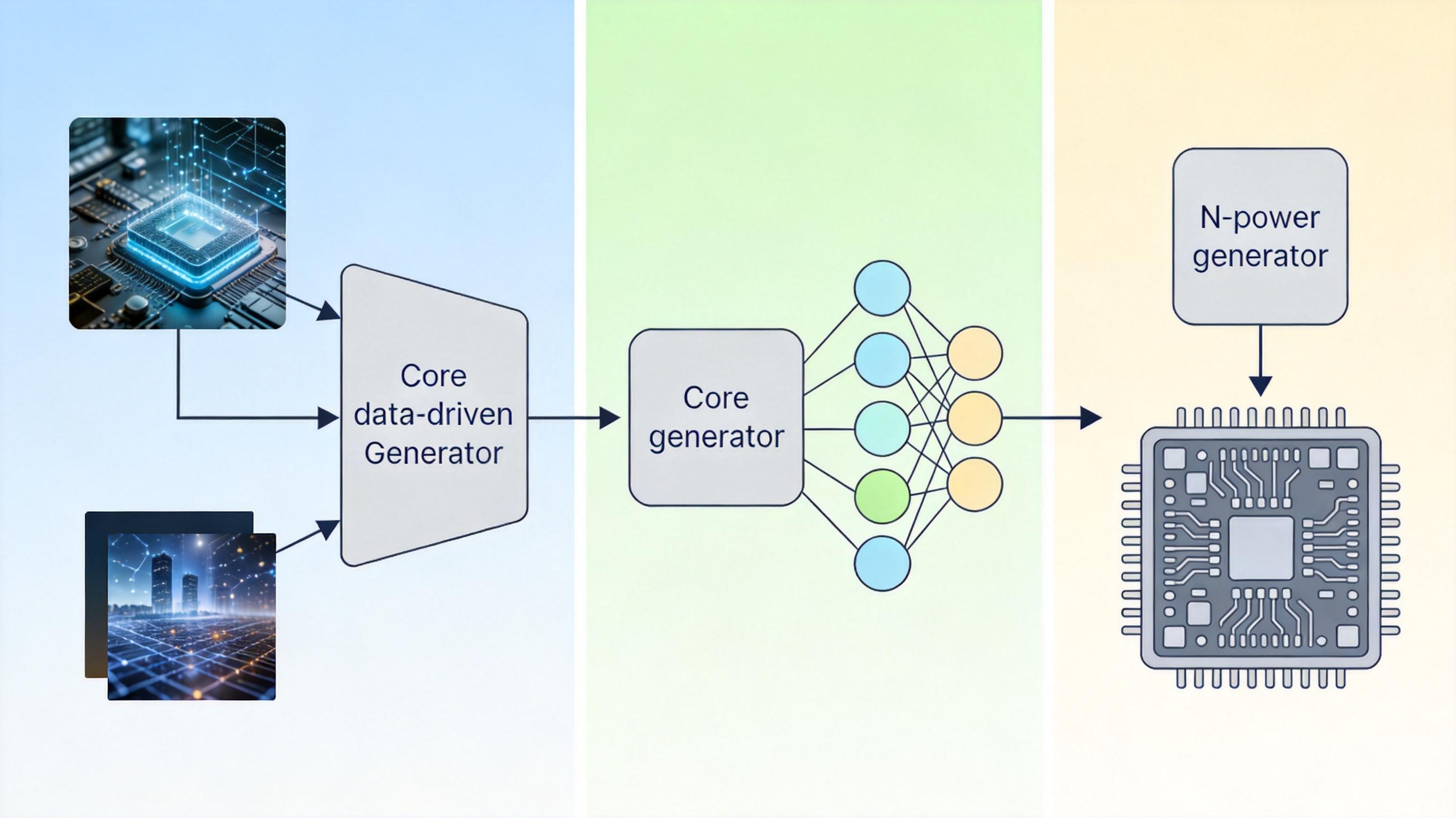
简单说,以前是人类告诉AI“留哪些”,现在是AI通过学习知道“该留哪些”。
实验结果比预想的更惊人。在三个主流多轮视觉问答数据集上,MetaCompress在扔掉90%视觉Token的情况下,准确率比之前最好的方法高出2%-5%。比如在MT-GQA数据集上,LLaVA-1.5模型用了MetaCompress后,准确率从70.68%涨到了72.94%。
效率提升更直接:Token生成延迟从232ms降到98ms,端到端推理时间缩短了近30%,显存占用也大幅下降。更重要的是,它不用针对新任务重新训练,直接就能用到没见过的数据集甚至视频问答里——相当于学会了一种“通用精简法”,不管处理什么图片都能用。
当然它也不是完美的:目前还只针对视觉Token压缩,没涉及对话文本的优化;在极端复杂的多轮推理中,偶尔还是会丢失一些极其细微的信息。但这些都是可以通过后续迭代解决的小问题,核心的突破已经完成。
当我们谈论AI的“智能”时,往往聚焦于它能回答多么复杂的问题,却忽略了“流畅对话”这种最基础的需求。MetaCompress的意义,不止是让AI在多轮对话中不卡壳,更在于它提供了一种思路:与其让AI记住所有细节,不如让AI学会“预判”哪些细节可能有用——这其实更接近人类的思考方式:我们看一张照片时,也不会记住每一个像素,只会在脑子里留下那些可能需要的信息。
数据驱动的选择,比人工经验更懂未来需求。未来的AI或许不需要变成“记忆大师”,只要学会做聪明的“减法”,就能在有限的算力里,实现更自然的交互。