对抗知识焦虑,从看懂这条开始
App 下载
类脑大模型瞬悉2.0:用1/10能耗处理百万级文本
记忆机制|能耗优化|超长文本处理|中国科学院|瞬悉2.0|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载记忆机制|能耗优化|超长文本处理|中国科学院|瞬悉2.0|大语言模型|人工智能
当你让AI一口气读完一整本书再写读后感时,传统大模型可能会直接“罢工”——要么计算慢到让你睡着,要么显存不够直接报错。这不是AI偷懒,而是它的“大脑”Transformer架构天生有个bug:处理的文本越长,计算量和能耗会像滚雪球一样疯涨。
但中国科学院的团队刚拿出的瞬悉2.0,把这个bug给补上了。它能轻松处理400万字的超长文本,首token生成速度比主流模型快10倍,能耗还能砍半,精度却没怎么下降。这不是简单的参数堆料,而是给AI换了个更像人类大脑的“思考方式”。它到底是怎么做到的?
你可以把传统大模型的注意力机制想象成:让一个人同时记住一本书里的每一个字,还要随时能说出任意两个字的关联——这显然是不可能完成的任务,不仅费脑子,还容易记混。而人类大脑的记忆方式是“选择性激活”:看到“猫”这个词,只会关联“猫粮”“猫砂”这些相关信息,不会去想昨天吃的火锅。
瞬悉2.0的核心创新“双空间混合稀疏注意力”,就是给AI装了这么一个“记忆开关”。它把注意力分成了两部分:一部分像人类的“精准回忆”,只对文本里的关键片段做密集计算;另一部分像“模糊联想”,对压缩后的文本框架做稀疏计算。两者按1:3的比例搭配,既保证了关键信息不遗漏,又砍掉了70%以上的无效计算。
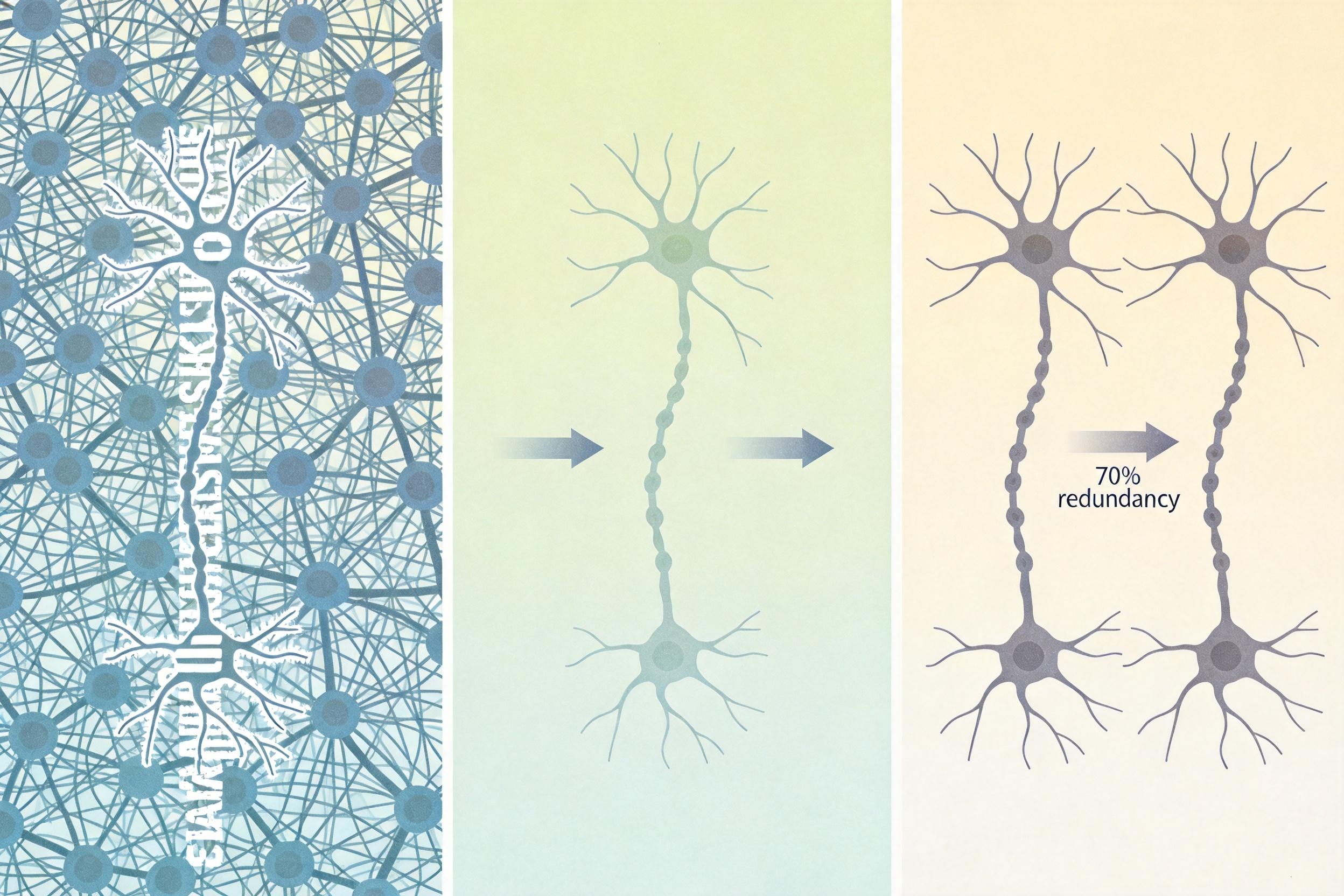
更关键的是,这个机制完全是类脑的——它模拟了人类大脑神经元的“兴奋-抑制”模式:只有收到强刺激的神经元才会活跃,大部分神经元都处于“待机”状态。这种设计让瞬悉2.0处理400万字文本时,计算量不再随长度平方增长,而是近乎线性增加,显存占用直接砍到了传统模型的1/10。
如果说稀疏注意力是给AI减了计算量,那脉冲编码就是给AI降了能耗。你可以把传统大模型的计算过程想象成:家里所有的灯24小时都亮着,不管有没有人在;而脉冲编码就像装了人体感应灯——只有需要的时候才亮,没人的时候就自动熄灭。
瞬悉2.0的INT8-Spiking脉冲编码路径,就是把AI的计算信号转换成了类似人脑神经元的“脉冲信号”:只有当计算结果超过某个阈值时,才会触发一次“放电”,进行整数累加计算;没超过阈值的部分就直接跳过。实测显示,瞬悉2.0的脉冲稀疏度高达64.3%——也就是说,有超过六成的计算都是“无效放电”,被直接省掉了。
这种设计带来的能耗下降是惊人的:模拟测试显示,它能让神经形态芯片的面积缩小70.6%,在250MHz工作频率下功耗降低48.1%。更难得的是,精度损失只有0.69%——相当于你用手机拍照,从4800万像素降到4760万像素,肉眼根本看不出区别。
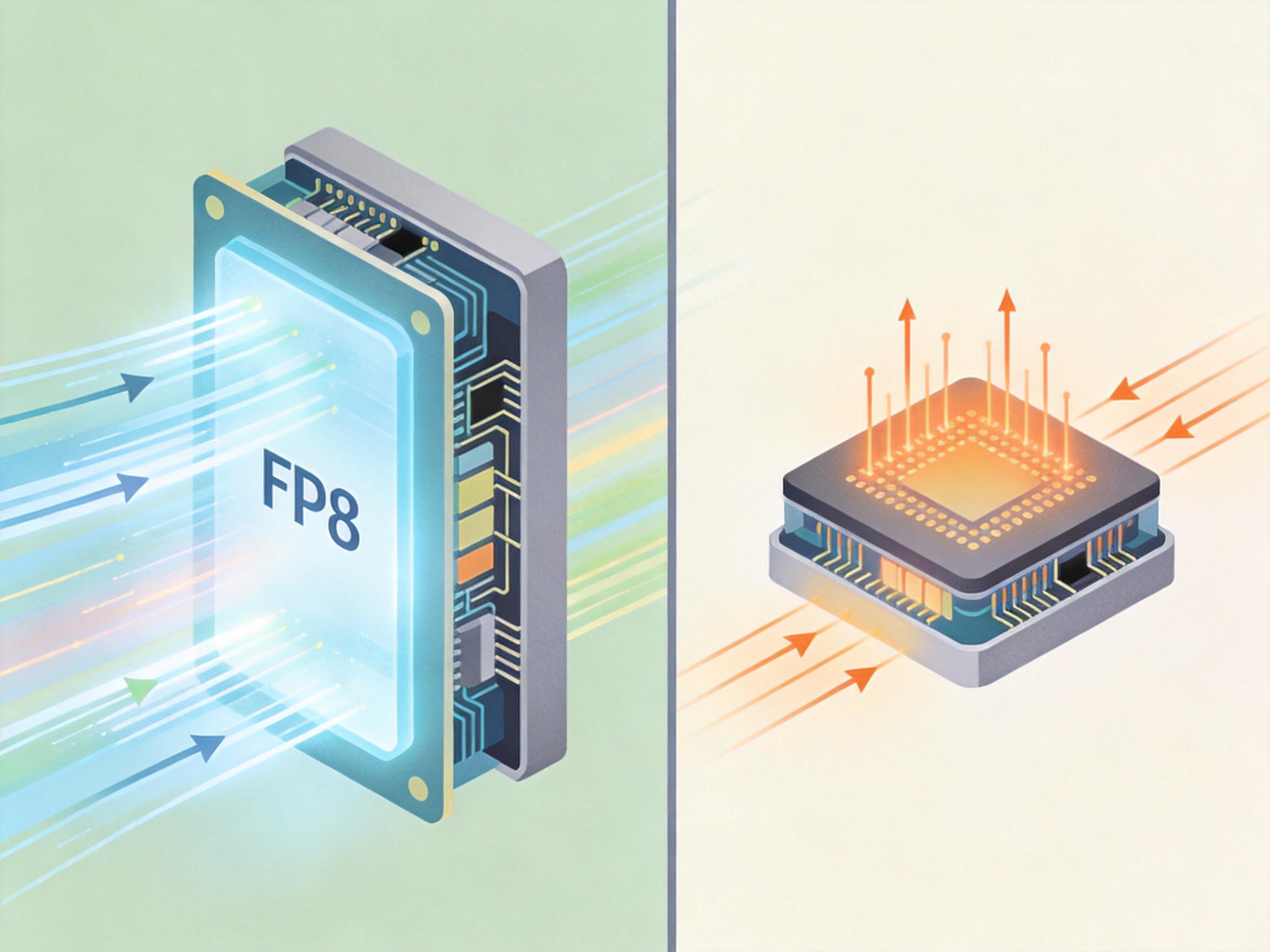
有意思的是,瞬悉2.0还做了双路径设计:一条路径用FP8低比特浮点数,适合在传统GPU上高速推理;另一条用脉冲编码,适合在神经形态芯片上低功耗运行。就像给AI准备了两套“操作系统”,既能在数据中心当“算力猛兽”,也能在边缘设备当“省电小能手”。
很多人可能会问:减了计算量,降了能耗,性能会不会打折扣?答案是不仅没降,还追平了主流模型。
瞬悉2.0的训练数据量从初代的1500亿token降到了140亿,只用32张A100显卡,9天就完成了训练——成本直接砍到了初代的1/10。但在通用知识任务(比如MMLU、ARC-C)和推理任务(比如数学计算、代码生成)上,它的表现能和Qwen3比肩;多模态任务上,也能追平Qwen2.5-VL的水平。
这背后的秘密是“Transformer-to-Hybrid”转换训练流程:先把成熟的Transformer模型“蒸馏”成稀疏架构,再用少量数据做针对性微调。相当于先抄一份学霸的笔记,再根据自己的情况做简化,既省了时间,又没丢核心知识点。
当然,它也不是完美的。比如在处理极短文本时,它的效率提升不如长文本明显;脉冲编码的硬件生态还不够完善,目前只能在特定的神经形态芯片上发挥最大优势。但这些问题,都挡不住它成为大模型“降本增效”的关键突破口。
当我们还在为大模型的参数规模和算力需求焦虑时,瞬悉2.0给我们指了另一条路:与其一味堆参数、堆算力,不如向人类大脑学习——用更高效的方式处理信息,而不是用更密集的计算硬扛。
这不仅是技术的突破,更是理念的转变。未来的AI,可能不是越算越快,而是越“懒”越聪明——只在必要的时候计算,只在关键的地方发力。
类脑不是模仿,而是找到更高效的智能。 当AI学会像人类一样“按需思考”,它才能真正走进我们的生活——从边缘设备到数据中心,从超长文本处理到低功耗实时推理,真正实现智能的“普惠”。