对抗知识焦虑,从看懂这条开始
App 下载
AI觉醒“视觉”:当机器不再“阅读”谜题,而是开始“看见”答案
视觉网格|图形变换规律|François Chollet|抽象推理语料库|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视觉网格|图形变换规律|François Chollet|抽象推理语料库|多模态视觉|人工智能
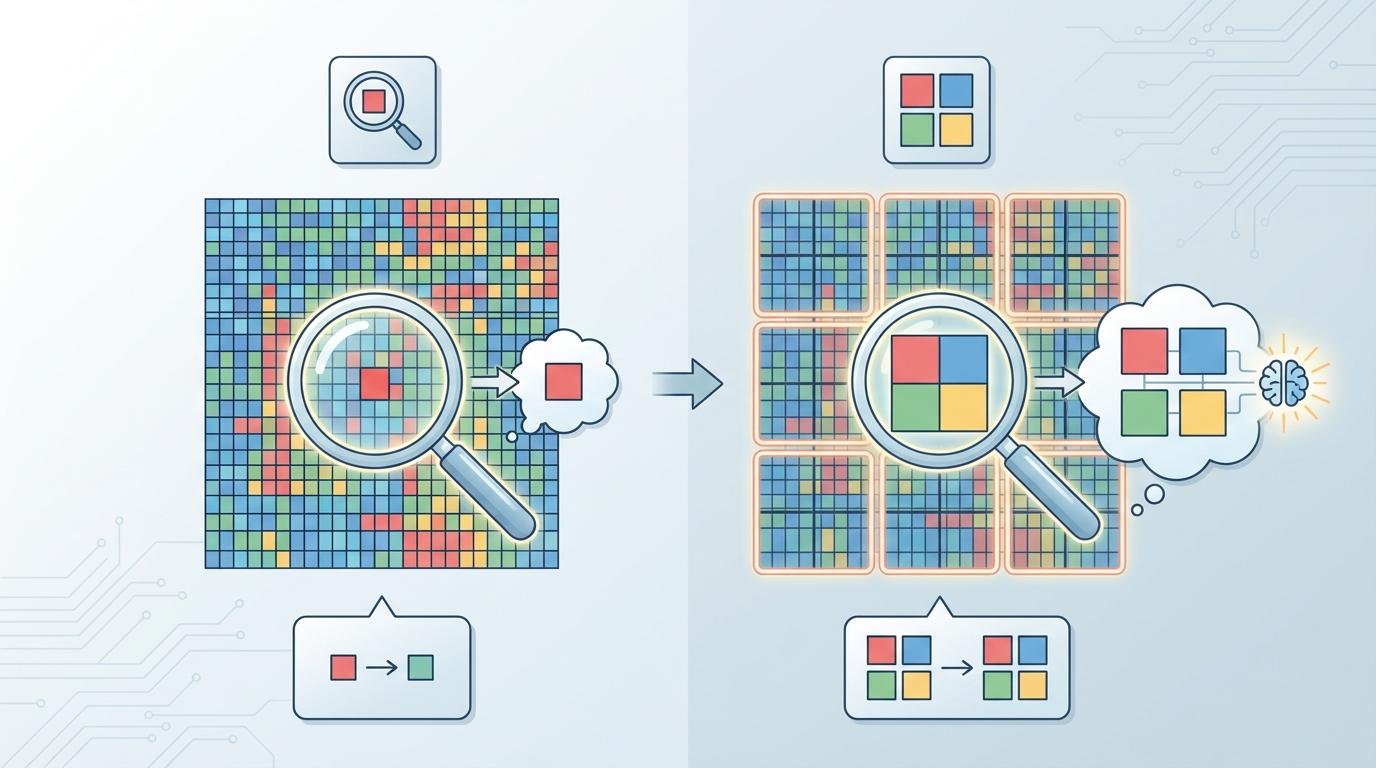
在一间虚拟的考场里,坐着当今最强大的人工智能。它们能写诗、能编程、能与人对谈如流。然而,考卷上的题目却让它们陷入了困境。这些题目并非深奥的语言迷宫,而是一系列色彩斑斓的方格谜题,名为“抽象推理语料库”(ARC)。
ARC,由Google的AI研究员François Chollet于2019年推出,被誉为“通用人工智能的试金石”。它的规则简单到孩童都能理解:通过观察几个“输入-输出”的示例,找出其中隐藏的图形变换规律,并应用到新的输入上。然而,这些对人类直觉不言而喻的谜题,却成了AI难以逾越的天堑。多年来,AI界的通行做法是,将这些视觉网格“翻译”成文本序列,然后让大语言模型(LLM)去“阅读”和“理解”,试图用语言逻辑破解视觉密码。这就像蒙着眼睛,只通过他人的口头描述来学习绘画,终究隔了一层。
这场持续数年的“范式之争”——究竟该用语言的逻辑,还是视觉的直觉来叩开通用智能的大门——在2025年11月26日迎来了一个决定性的转折点。来自MIT何恺明团队的一篇论文,以一句石破天惊的宣言给出了答案:“ARC是一个视觉问题!”
这篇名为《ARC Is a Vision Problem!》的论文,提出了一个名为**视觉ARC(Vision ARC, VARC)**的全新框架。它彻底抛弃了“语言中介”的弯路,将ARC任务重新定义为一个纯粹的“图像到图像”的转换问题,让AI第一次真正用“眼睛”去看待这个谜题。
VARC框架的设计充满了视觉艺术般的直觉与优雅。研究团队没有直接处理那些大小不一的原始网格,而是引入了一个绝妙的概念——“画布”(Canvas)。
想象一下,每个谜题的输入网格不再是一个孤立的数据矩阵,而是一张被随意“贴”在64x64固定尺寸画布上的小图片。这张小图片可以被随机缩放和平移。这个看似简单的操作,却蕴含着深刻的视觉智慧:
有了这张“画布”,团队顺理成章地请出了为视觉而生的主角——视觉Transformer(Vision Transformer, ViT)。这个模型架构,配上能理解二维空间结构的2D位置编码,开始直接端到端地学习如何将输入的“画布”变成答案“画布”。
训练过程也独具匠心,分为两步:
结果是惊人的。在ARC-1基准上,VARC的集成模型取得了60.4%的准确率,不仅大幅超越了其他所有从零开始训练的模型,其性能甚至媲美那些参数量大几个数量级的顶级大语言模型,并与人类的平均水平(60.2%)几乎持平。
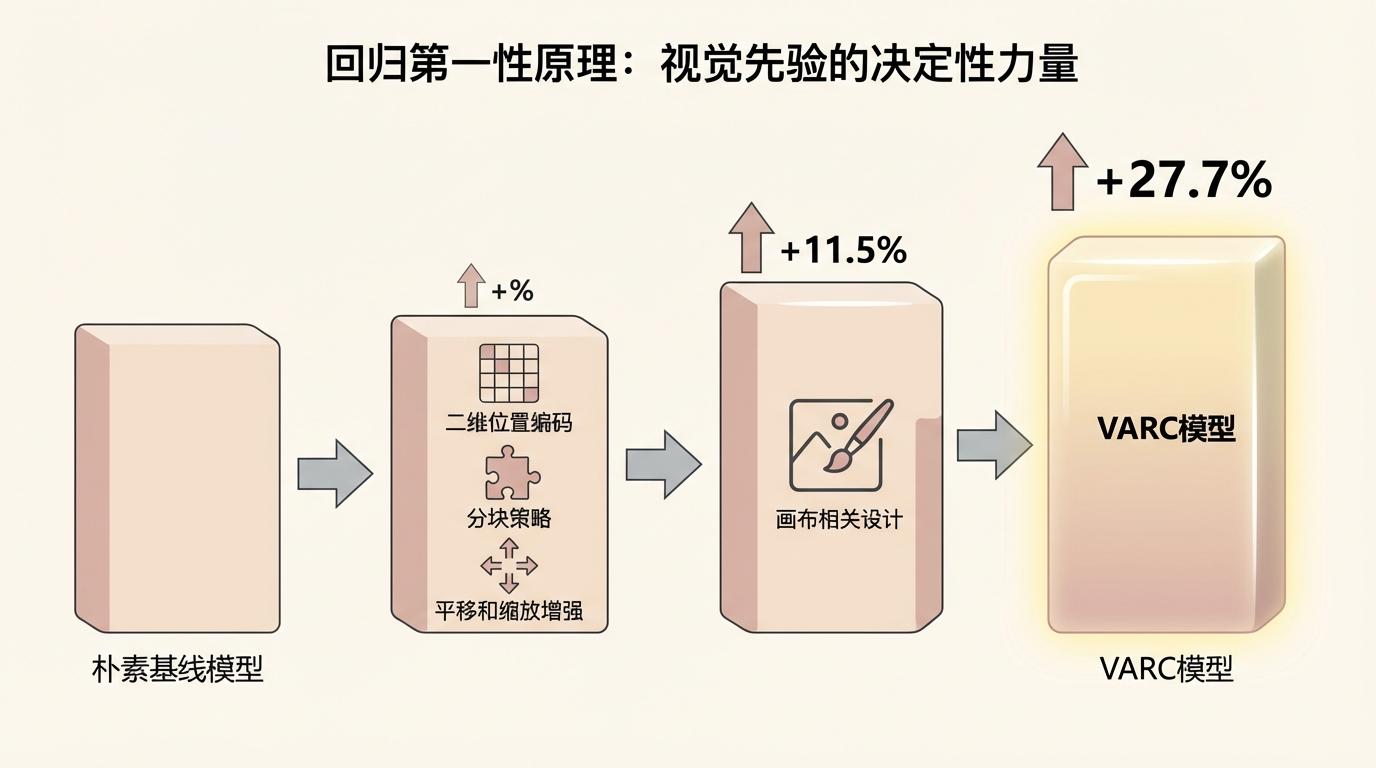
VARC的成功并非偶然,而是一次对“第一性原理”的回归。消融实验清晰地揭示了视觉先验的决定性力量。从一个朴素的基线模型开始,逐步加入二维位置编码、分块策略、平移和缩放增强等视觉元素后,模型的性能累计提升了27.7个百分点,其中仅“画布”相关的设计就贡献了11.5个点的增益。
这证明,抽象推理能力并非只能从海量的语言数据中涌现。当给予正确的“视觉偏置”(Inductive Biases)时,智能可以直接从原始像素中诞生。VARC用一个相对小巧、且仅在ARC自身数据上训练的模型,挑战了“大力出奇迹”的行业信条,上演了一场优雅战胜蛮力的好戏。
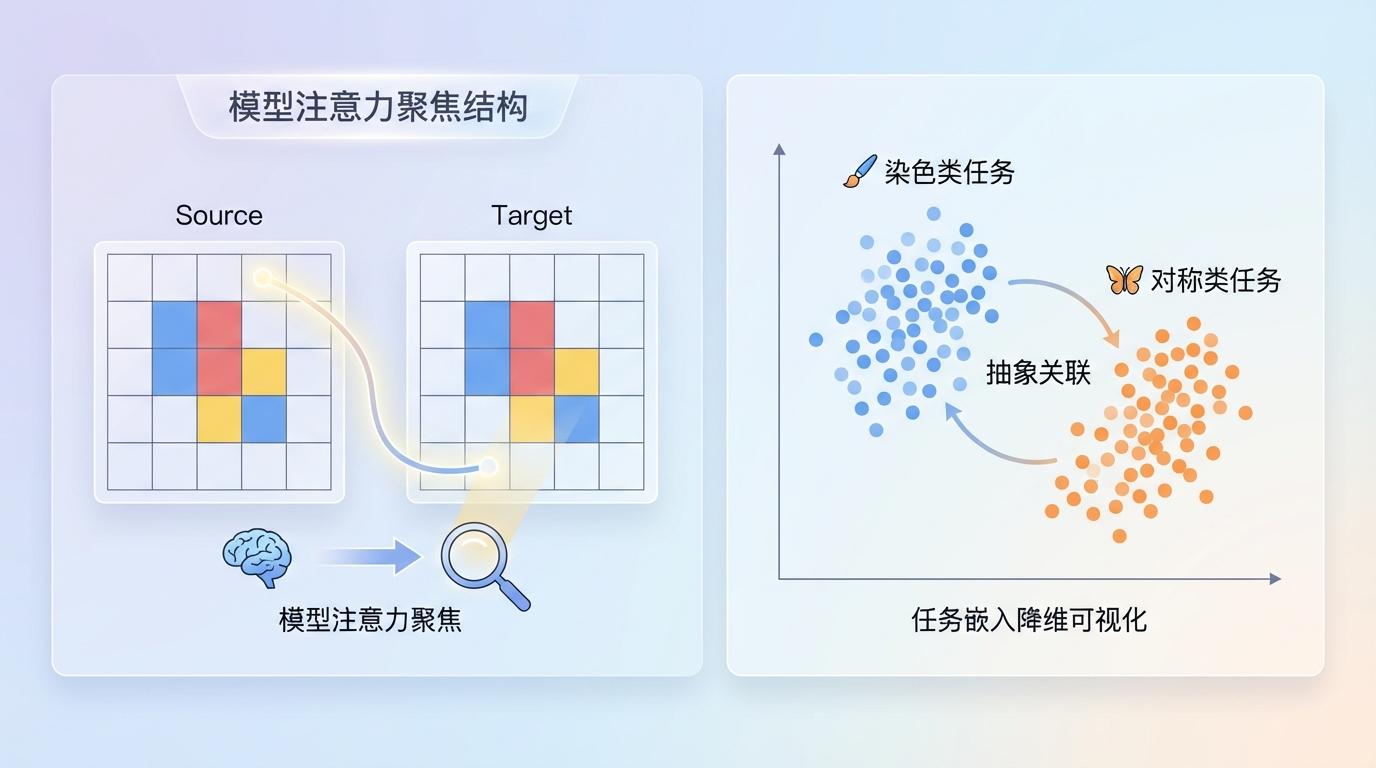
更有趣的是,通过可视化模型的“注意力”,研究者发现模型确实在学习有意义的视觉模式。例如,在处理复制任务时,模型的注意力会精确地从源像素聚焦到目标位置。将不同任务的学习嵌入进行降维可视化后,语义相似的任务(如“染色”类或“对称”类)在空间中自然地聚集在一起。这表明,VARC不仅在解决单个问题,更是在学习这些视觉谜题之间内在的、抽象的关联。
VARC的突破,其意义远不止于攻克一个AI基准测试。它标志着在通往通用人工智能的道路上,一次深刻的范式转换正在发生——从语言中心主义,向植根于感知的视觉本源回归。
长期以来,AI领域似乎有一种默认假设:高级智能等同于语言能力。但人类智能的根基,恰恰建立在对物理世界的感知和互动之上。我们在学会说话之前,就已经通过眼睛理解了空间、物体和因果。VARC的成功恰恰印证了这一点:真正的抽象能力,或许本就源于视觉经验的归纳,而非语言符号的排列组合。
这一“视觉为中心”的范式,与AI领域另一前沿方向——“世界模型”(World Models)不谋而合。无论是自动驾驶、具身智能还是机器人,AI若想在真实世界中行动,就必须首先构建一个关于世界如何运作的内在视觉模型。它们需要理解重力、理解碰撞、理解空间关系,而这些都无法仅从文本中学到。
当然,VARC并非终点。它依然依赖于耗时的“测试时训练”,对某些复杂规则的理解也存在局限。但它开辟了一条全新的、极具潜力的道路。未来的研究或许可以将这种纯视觉方法与更大规模的视觉预训练相结合,探索更高效的适配机制,甚至融入多模态信息,让AI同时拥有“看”和“说”的能力。
正如论文结语所言:“ARC不仅仅是一个谜题集合;它是一个视觉世界,理应被用视觉的眼睛来看待。” VARC的出现,让我们得以一窥通用智能的未来图景:一个不再仅仅依赖语言符号,而是能真正“看见”并“理解”我们所处世界的智能。这或许才是AI从“鹦鹉学舌”走向“乌鸦反哺”式真智能的关键一步。