对抗知识焦虑,从看懂这条开始
App 下载
AI视频不闪烁了,秘密藏在模型的「激动神经元」里
画面稳定|Pinscreen|MBZUAI|激动神经元|AI视频生成|多模态视觉|人工智能
你有没有过这种经历:用AI生成的视频,前一秒还是棕毛小狗,后一帧突然变成花斑的;好好的古建筑,中间几帧突然「扭」成了麻花。这些恼人的闪烁和跳帧,是AI视频生成的老难题——之前要么靠额外训练烧钱,要么靠多轮推理费电,似乎总得付出点代价。但现在,来自MBZUAI和Pinscreen的团队找到了一个「作弊码」:不用改模型,不用加训练,只要在AI生成视频的过程中,轻轻「拨一下」模型内部的某个开关,就能让画面稳下来,画质还能提升,而且额外计算开销不到0.1%。这个藏在模型深处的开关,到底是什么?
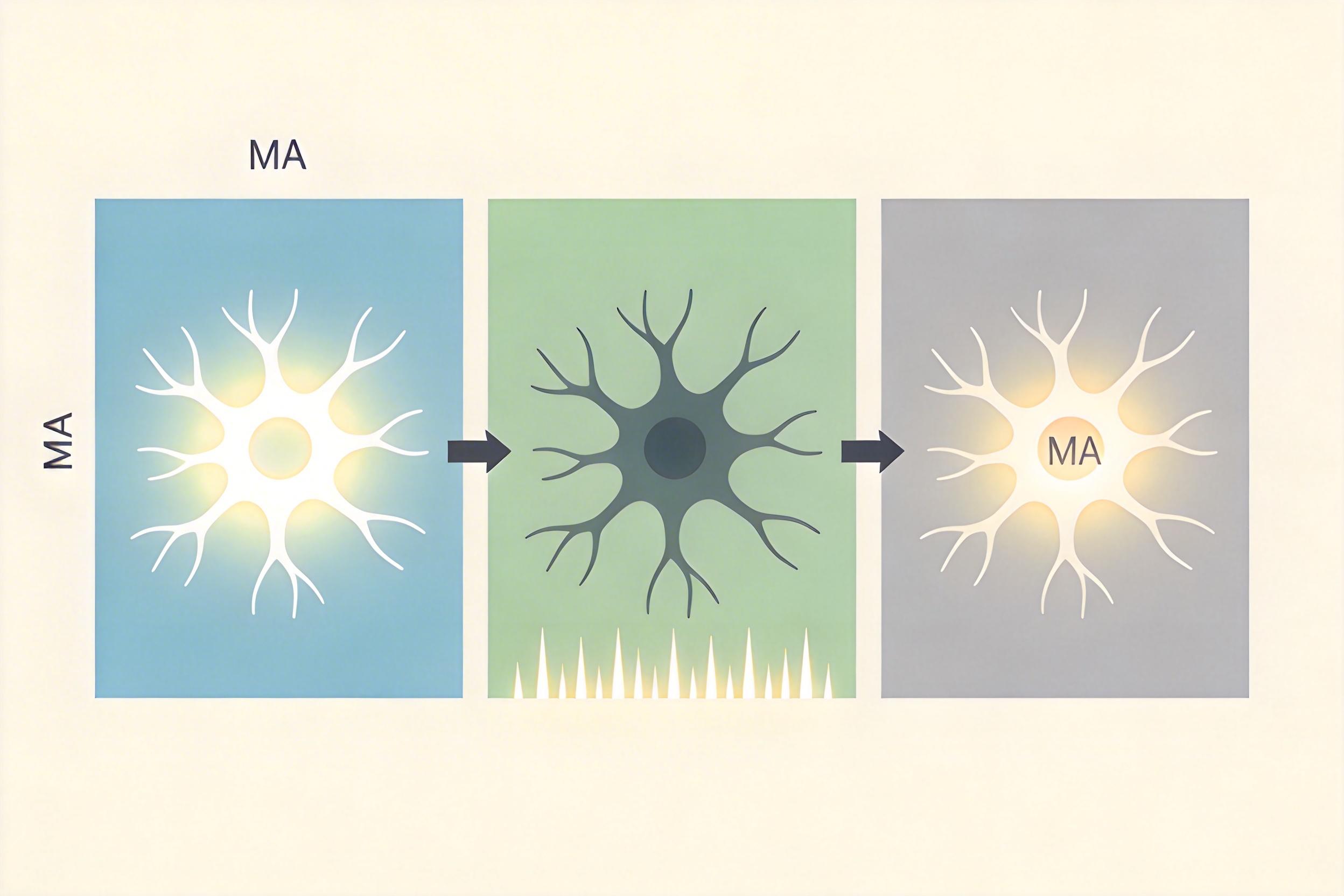
模型里的「特立独行神经元」:Massive Activations
你可以把AI视频生成模型想象成一个庞大的工厂:每一个神经元都是一个工人,负责处理特定的视觉信号。绝大多数时候,工人们都按部就班地干活,输出的信号强度差不多。但总有几个「特立独行」的工人,会突然亢奋起来,输出的信号比其他人高几十甚至上百倍——这就是Massive Activations(MA,大规模激活)。
之前研究在图像生成模型里发现过MA,知道它对细节很重要,但没人系统地盯着视频模型看。这次研究者一深挖,发现了一个惊人的规律:视频模型里的MA不是乱激动的,它的分布严格遵循着时空秩序。第一帧的神经元MA值最高,像整个视频的「锚点」,告诉模型「后面所有画面都得跟着它走」;每个被压缩的潜在帧的开头和结尾,MA值也会飙升,像在标注「这里是接缝,要平滑过渡」;而潜在帧内部的MA值,就温和得多。
更有意思的是,这种「锚点-接缝-内部」的等级差异,只在生成早期最明显。随着视频一步步生成,所有MA值都会慢慢衰减,接缝和内部的差异也会缩小——就像盖房子,早期要先搭好骨架,明确承重墙和梁柱的位置,后期再慢慢填充细节。
轻拨开关:不用训练的STAS策略
既然找到了MA的规律,怎么利用它?研究者提出了一个叫STAS(结构化激活引导)的方法——核心就是在生成视频的早期,有选择地放大那些关键位置的MA值,强化模型自己本来就有的时空秩序感。
说起来复杂,操作其实很简单:首先定位模型里那些会「激动」的MA维度,然后找到第一帧和潜在帧边界对应的神经元,在生成的前20步(也就是搭骨架的阶段),把这些神经元的激活值放大到当前全局最大值的一定比例——注意,不是瞎放大,是根据模型当前的状态动态调整,保持原有的正负信号。
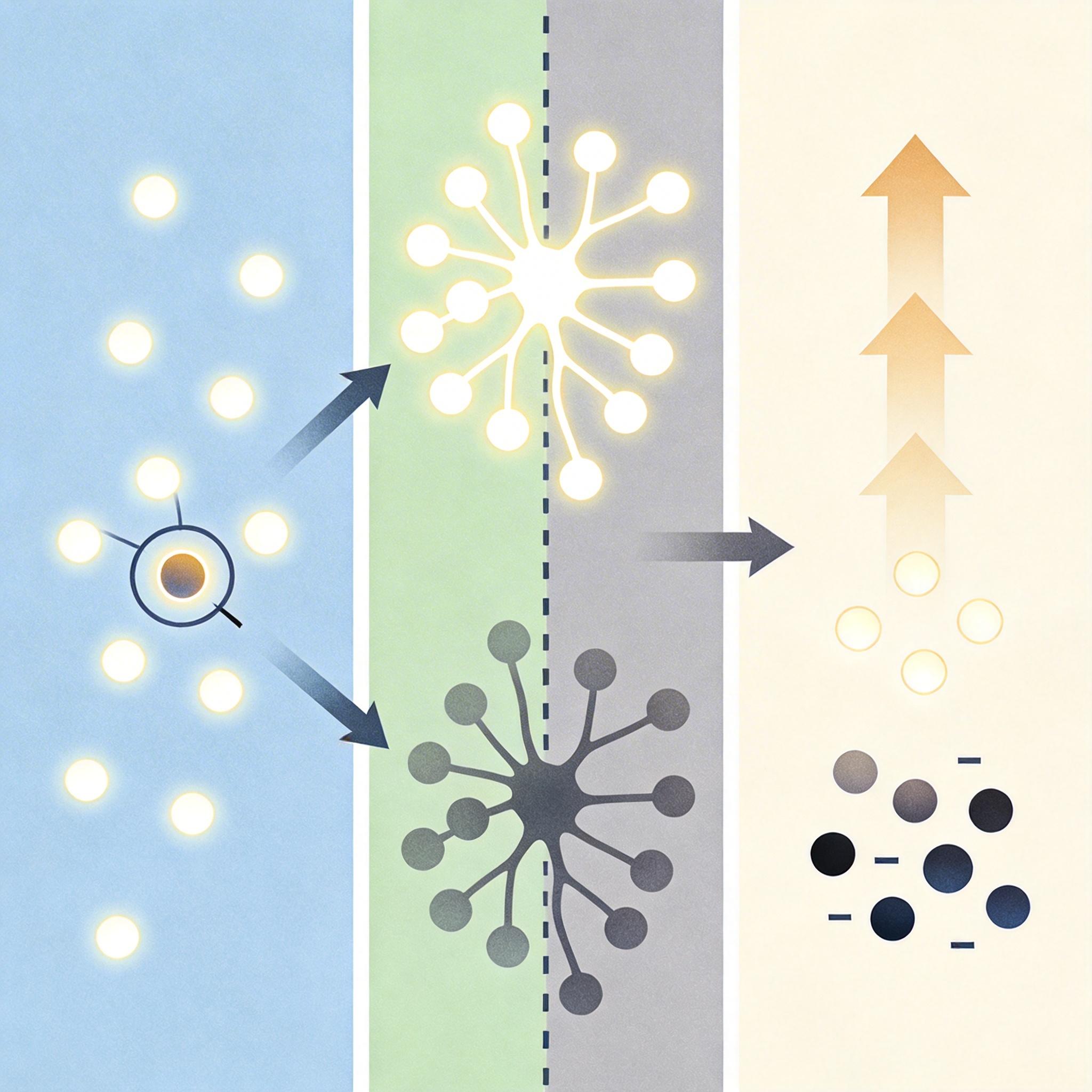
这个操作有多轻量?只是在推理过程中对少数神经元的数值做了点微调,完全不修改模型权重,额外计算开销不到0.1%——就像给手机调个亮度,几乎不耗电。而且它还能和现有的其他优化方法兼容,比如CFG-Zero*、FlowMo,叠加上去能实现「1+1>2」的效果。
实验结果很直观:在Wan2.1-1.3B、CogVideoX-5B等主流模型上,STAS让视频的整体质量评分提升了0.2-0.4分,跨帧边界的相似度明显上升,那些恼人的闪烁、跳帧几乎消失了。比如生成的厨房视频里,烤面包机旁的泰迪熊不会突然长出奇怪的伪影;中世纪石塔的结构,在整个视频里都能稳稳保持。

不是银弹,是更聪明的思路
当然,STAS不是万能的。它的本质是「放大模型本来就有的能力」,如果基础模型在训练时就没学好某种运动模式,比如复杂的舞蹈动作,再怎么调MA也没用——它是「锦上添花」,不是「无中生有」。而且目前它只适配用VAE做时间压缩的Video DiT架构,换成U-Net之类的模型,还得重新研究MA的规律。
更值得关注的是,STAS代表的是一种全新的AI优化思路:之前我们总想着给模型加数据、改结构、训参数,像给汽车换引擎、加涡轮;但现在我们发现,有时候不用动硬件,只要找到仪表盘上的隐藏旋钮,轻轻一拨,就能让车跑得更稳更快。这种「模型内省+轻量级干预」的思路,比盲目堆参数要聪明得多——毕竟,理解模型已经学会的东西,比强迫它学新东西,成本低多了。
AI视频生成的进步,从来都不只是「模型更大、参数更多」。这次STAS的突破,更像是给我们提了个醒:与其总想着从外部给模型「灌输」能力,不如先低头看看模型内部,那些已经存在却被忽略的信号。
未来的AI优化,可能会越来越像「中医」:通过观察模型的「脉象」(内部激活),找到失衡的地方,用最温和的方式调整,而不是上来就动大手术。「最好的优化,是利用模型本来就有的智慧」——这句话,或许会成为下一代AI研究的核心思路。毕竟,有时候最强大的力量,一直都在我们眼前,只是我们没发现而已。