对抗知识焦虑,从看懂这条开始
App 下载
AI视频生成提速6.7倍:FlowCache如何破解实时化瓶颈?
字节跳动|厦门大学|推理加速|自回归视频模型|FlowCache|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载字节跳动|厦门大学|推理加速|自回归视频模型|FlowCache|AIGC|人工智能
AI视频生成的梦想近在咫尺:输入一行文字,产出一部电影。但现实却是一场漫长的等待。你让AI生成一段一分钟的视频,然后去泡了杯咖啡,回来发现它还在渲染第一帧。对于追求高分辨率、长时长的自回归视频模型而言,动辄数十分钟的生成时间是常态,这道无形的“效率墙”将AI视频的实时化应用牢牢挡在门外。
然而,就在最近,这堵墙似乎出现了一道裂缝。来自厦门大学和字节跳动的研究团队发布了一项名为FlowCache的技术,如同一把锋利的快刀,直插自回归模型效率低下的心脏。它不改变模型,不重新训练,仅仅通过优化推理过程,就实现了最高6.7倍的惊人加速,且视频质量几乎毫无损失。这不仅是一次技术迭代,更可能是一场开启AI视频实时化大门的革命。
要理解FlowCache的巧妙之处,首先要明白自回归模型为何陷入“慢动作”困境。为了生成连贯的长视频,自回归模型采取了一种聪明的策略:像拼接乐高一样,将长视频切成一个个“块”(chunk),逐块生成。后一块的生成会参考前一块,确保了时序的连贯性。
问题出在每一块自身的生成过程。每个视频块都需要经历数十步“去噪”,从一团模糊的噪声中逐渐变得清晰。研究人员自然想到,既然相邻去噪步骤之间画面变化不大,何不将上一步的结果“缓存”下来,直接复用,跳过一些计算?
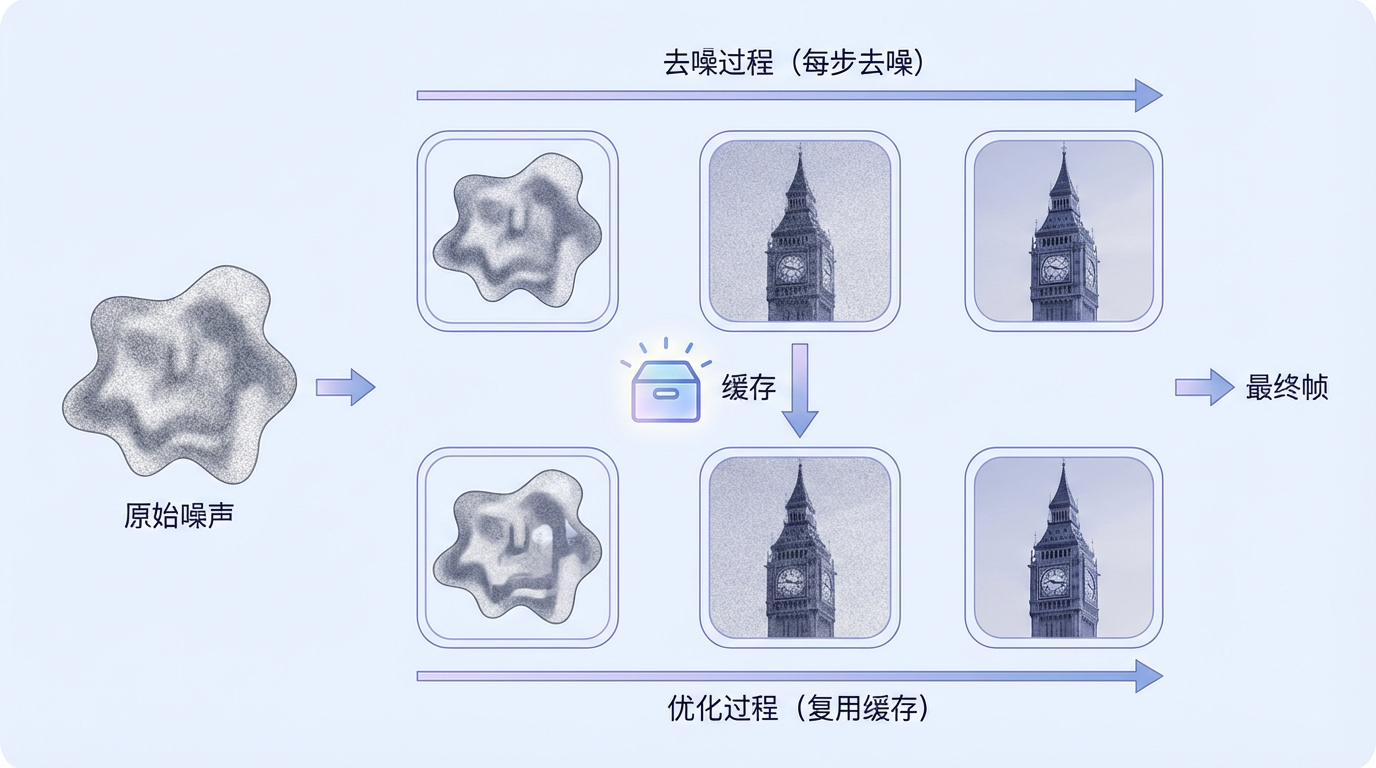
然而,当把现有缓存技术直接用于自回归模型时,却出现了严重的“水土不服”。原因在于,自回归模型的去噪过程是异步、分块进行的。想象一个三人绘画接力小组,当第三位画师正在为画卷末尾的C区域进行第5步上色时,中间的B区域可能已经进行到第15步精修,而最早开始的A区域早已完工。传统的缓存技术就像一个僵化的监工,在同一时刻对所有画师下达统一指令:“要么全画,要么全歇(复用缓存)。”这显然不合理——对需要精修的区域强制休息,会损害画质;为了保质量而不敢休息,又达不到加速效果。
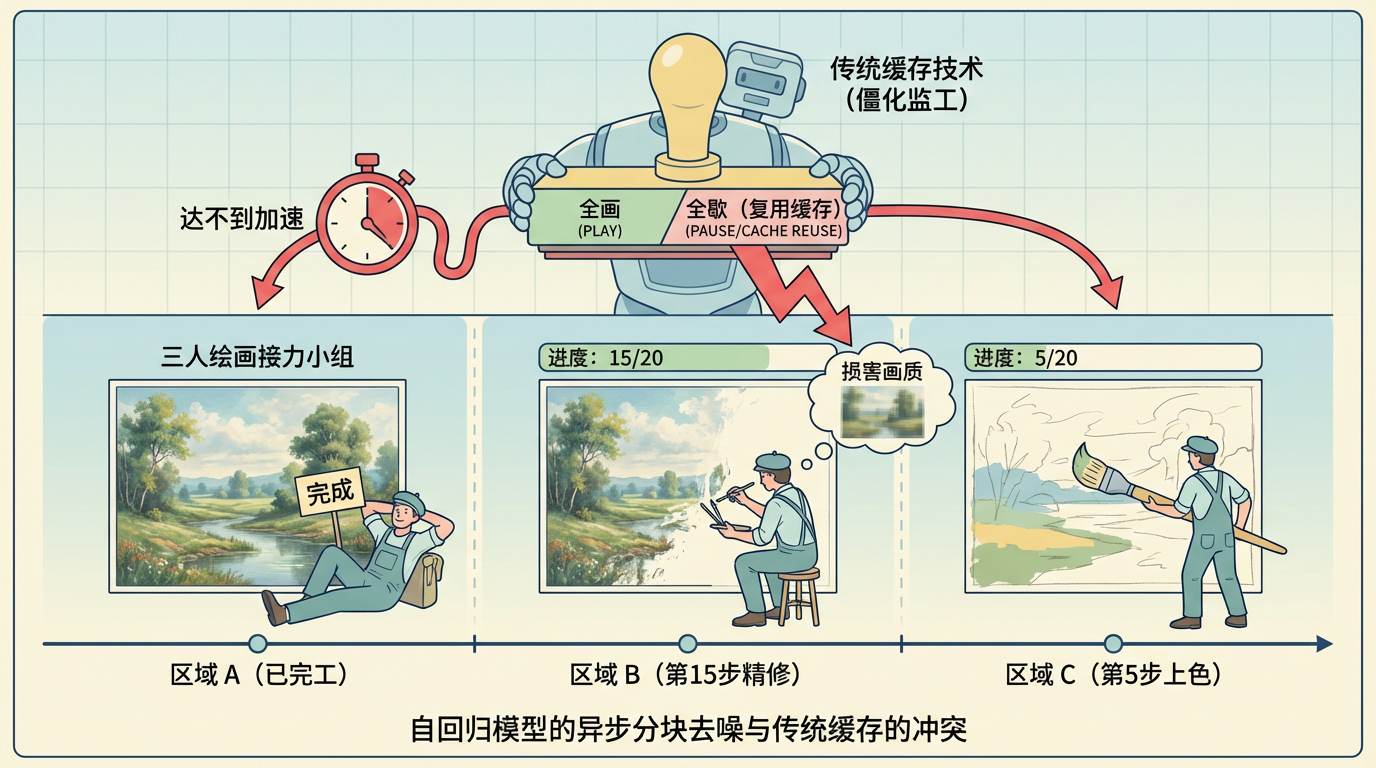
FlowCache的作者们正是洞察到了这个核心矛盾:在同一时间步,不同视频块处于完全不同的去噪阶段,需要区别对待。
基于上述洞察,FlowCache提出了优雅而高效的双引擎解决方案:
FlowCache为每个视频块配备了一个独立的“缓存状态累积器”。这个累积器会追踪该块在连续去噪步骤中的“累计变化量”。决策规则变得非常智能:
这种“因块施策”的策略,让每个视频块都能根据自身的“绘画进度”动态决定是否需要“精雕细琢”,在保证质量的同时,最大限度地榨干了计算优化的潜力。
解决了计算速度,另一个“内存杀手”——KV缓存浮出水面。这是自回归模型用来存储历史信息、保持视频连贯性的关键机制。视频越长,块越多,KV缓存就滚雪球般地增大,很快就能撑爆最顶级的GPU显存。
传统的压缩方法只关注信息的重要性,但这在视频中行不通,因为视频数据充满了冗余——相邻的帧、相似的区域,可能都“很重要”但信息却高度雷同。FlowCache的KV缓存压缩方案则引入了“多样性”的考量,其核心思想是:既要“重要”,也要“不重复”。
它通过一个综合评分机制来筛选历史信息: 最终得分 = λ × 重要性分数 - (1 - λ) × 冗余度分数
通过这套组合拳,FlowCache用有限的内存预算,保留了与当前生成内容最相关且信息最多样的历史精华,从而更好地维持了长视频的时空一致性。
FlowCache的成功并非个例,它标志着AI视频生成领域正从单纯追求模型规模,转向对推理效率的极致挖掘。在这条赛道上,群雄并起,各显神通:
这些技术路径虽有不同,但共同指向一个未来:通过精巧的算法和系统优化,将AI视频生成的成本(无论是时间还是硬件)大幅降低,使其飞入寻常百姓家。
当生成视频从数十分钟缩短到数秒甚至毫秒,一个全新的应用世界豁然开朗。AI视频正从一个“内容生产者”,蜕变为一个“实时交互伙伴”。
尽管前景光明,但通往AI视频实时化的道路并非坦途。FlowCache等技术虽然高效,但其阈值等超参数仍需针对不同模型进行微调。对于数十分钟乃至更长的视频,如何设计更全局、更自适应的缓存管理策略,依然是悬而未决的课题。
更深层次的挑战在于技术之外。随着生成门槛的降低,如何应对虚假视频的泛滥?AI生成内容的版权归属如何界定?这些伦理和法律问题,是技术浪潮下亟待建立的堤坝。
无论如何,FlowCache及其同行的探索雄辩地证明:在AI的军备竞赛中,除了追求更大、更强的模型“肌肉”,对现有模型推理过程“精打细算”的智慧同样能带来革命性的红利。正是这些看似微小的优化,正在撬动整个行业,将AI视频从遥远的科幻想象,一步步拉近到我们触手可及的现实之中。