
12 天前
12 天前
想象一下:让一个精通识别宋体、黑体、手写体,能精准拆分表格、公式的文档OCR专家,突然去读化学论文里的分子结构图——那些歪歪扭扭的化学键、挤在一起的原子符号,还有各种奇奇怪怪的立体构型标注。这就像让资深语文老师去解高等数学题,不仅要读懂图形,还要把它转换成计算机能认的「化学代码」SMILES,错一个字符,对应的分子就可能变成另一种完全不同的物质。2026年4月的一项研究真的这么干了,他们把通用视觉-语言大模型DeepSeek-OCR-2改造成了化学分子识别工具,结果如何?
直接让通用大模型硬刚化学任务,结果是灾难性的——原始模型在所有测试数据集上的准确率几乎为0。研究团队换了个思路:用「两阶段渐进微调」给大模型办个「化学补习班」。
第一阶段是「预科班」:用LoRA(低秩适应)技术,只在模型的关键层插入少量可训练的「适配器」,就像给模型戴一副专门看分子图的眼镜。这一阶段不改动模型的核心参数,只用19.2万对分子图-SMILES数据训练,让模型在保留通用文档识别能力的同时,初步建立「图形→化学语言」的映射。训练稳定,计算量只有全参数微调的几十分之一,还避免了「学了化学忘了文档」的灾难性遗忘。
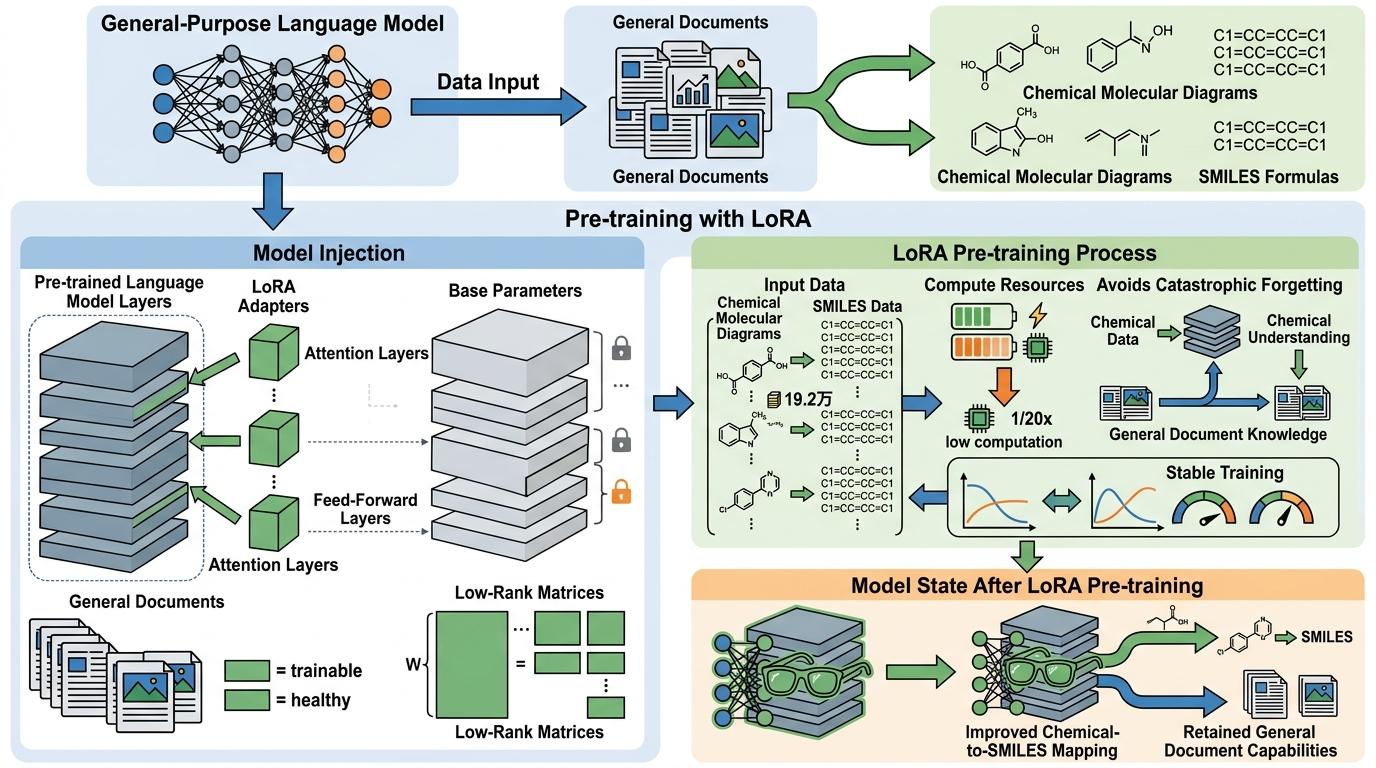
第二阶段是「专业课」:冻结模型底层负责识别线条、形状的视觉分词器,只微调高层的语义理解模块和语言解码器,还采用了「分叉学习率」——视觉模块用小学习率慢慢调,语言模块用大学习率强化SMILES生成能力。这一阶段把训练数据扩充到80万对,让模型在真实专利图像、扫描噪声的「实战」中打磨技能。
经过两阶段训练,模型的准确率从0提升到了50%-70%,部分场景能追上传统的图像到序列模型DECIMER。
光有补习班还不够,得有好教材。研究团队用「合成数据+真实数据」的混合食谱喂模型:合成数据像教科书,用PubChem数据库的分子结构生成两种风格的图像——一种是标准的ChemDraw风格,一种是模仿真实手绘的MolScribe风格,还添加了各种扰动,让模型见识分子图的各种画法;真实数据像高考真题,直接从USPTO专利里抽,有扫描不清的噪点、粗细不均的线条、专利特有的标注,全是现实中的「坑」。
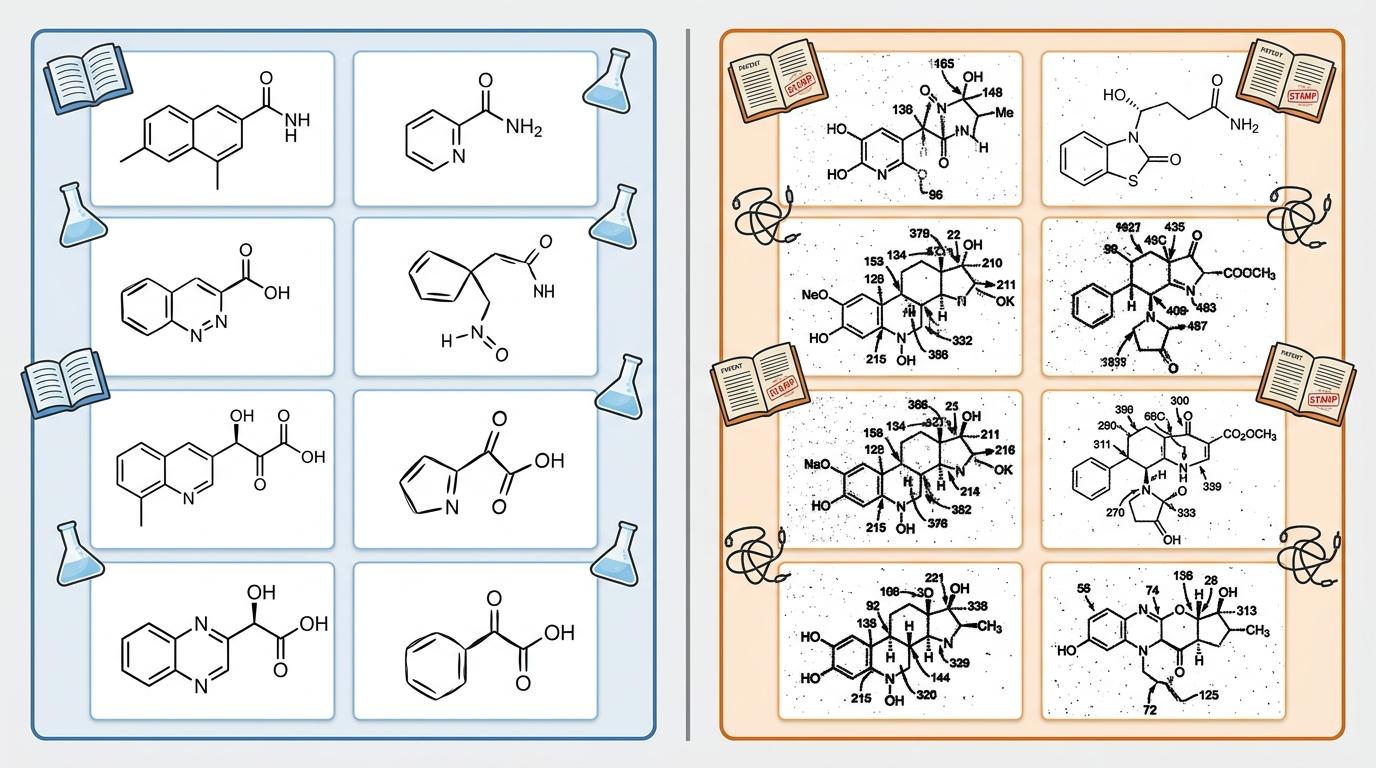
混合训练的效果很明显:只练合成数据的模型,在真实专利图像上的准确率只有46%-65%;只练真实数据的模型,因为数据量少容易过拟合,准确率也只有65%左右;而9:1的合成与真实数据混合训练,让模型的泛化能力大幅提升,在扰动数据集上的表现也更稳定。
但测试结果也暴露了短板:这个名叫MolSeek-OCR的模型,虽然能应付大部分常规分子图,但在识别立体化学构型、配位键这些复杂结构时,还是不如专门的「图像到图」模型MolScribe——后者能直接预测原子和化学键的空间关系,准确率能达到76%-93%,比MolSeek-OCR高出一大截。
研究团队还尝试用强化学习(GSPO)和数据清洗微调(ReFT)给模型「拔高」,结果却事与愿违:这些方法虽然提升了生成分子的化学有效性,比如让模型生成的SMILES更符合化学规则,但却牺牲了序列级的保真度——同一个分子可以有多种合法的SMILES表示,而评测只认标准答案那一种字符串。模型学会了「意思对就行」,但评测要求「一个字符都不能差」,最终导致精确匹配准确率不升反降。
这戳中了通用大模型做专业任务的一个深层矛盾:如何平衡语义正确和序列精确?对于化学数据库录入、专利审查这些需要绝对精准的场景,这个问题不解决,通用大模型就没法替代专用工具。
更现实的挑战是计算成本:即使用了LoRA,微调这样的大模型也需要至少8GB显存的GPU,推理速度也不如轻量的专用模型,很难部署在实时性要求高的场景里。
这项研究没有造出能颠覆化学界的神器,却做了一件更有价值的事:它用扎实的工程实践,证明了通用大模型可以通过「渐进微调+混合数据」的路径,跨界适应专业领域的高精度任务。它像一面镜子,照出了通用大模型的潜力——能快速学会新领域的基础知识,也照出了局限:在需要深度结构理解的任务上,还是不如量身定做的专用模型。
更值得关注的是,它给所有想把大模型落地到垂直领域的人提了个醒:大模型不是万能的「瑞士军刀」,在专业场景里,它更像一个需要针对性调校的「通用底盘」,得配上专门的「工具头」才能发挥最大作用。
跨界易,专精难,通用大模型需适配专业逻辑。
点击充电,成为大圆镜下一个视频选题!