对抗知识焦虑,从看懂这条开始
App 下载
AI不再只会夸照片好看,成了你的专属摄影导师
图像创作|摄影指导|Venus大模型|彭宇新团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载图像创作|摄影指导|Venus大模型|彭宇新团队|大语言模型|人工智能
你有没有过这种经历:对着刚拍的照片自我欣赏,转头发给AI求点评,得到的却只有千篇一律的“构图优美”“色彩和谐”?明明总觉得照片差点意思,AI却像个只会说场面话的社交达人,半点有用的建议都掏不出来。
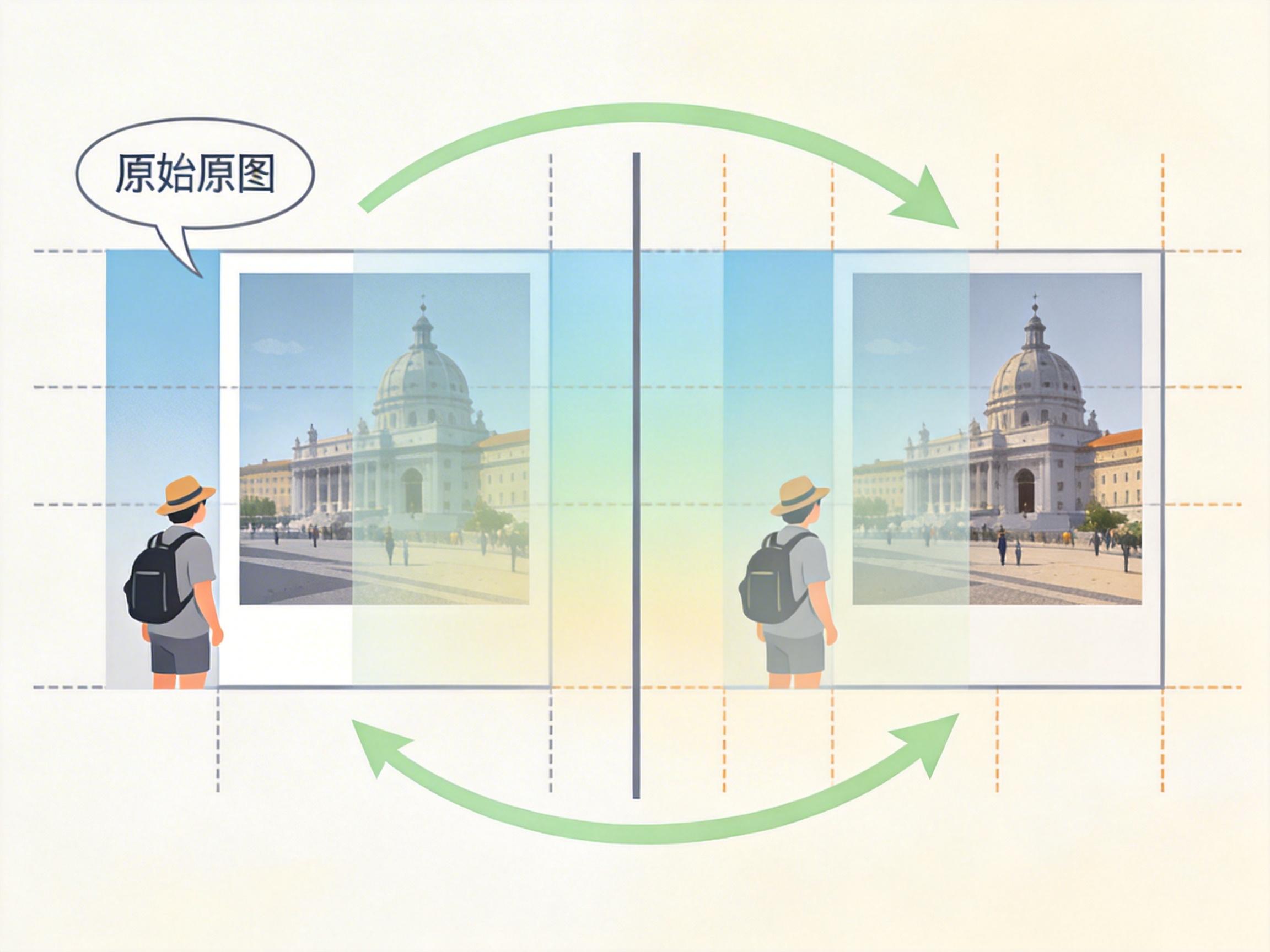
直到2026年3月,北京大学彭宇新教授团队把这个“社交达人”改造成了能挑刺、会教人的“摄影导师”——他们训练的Venus大模型,不仅能一眼看穿你照片里构图松散、主体模糊的问题,还能像专业摄影师一样告诉你:“蹲低30厘米,用三分法把人物放在右侧交叉点”。这背后,是AI第一次真正跨过“描述图像”到“指导创作”的门槛。
要让AI学会指导摄影,首先得给它找对老师。过去的AI美学训练,要么用的是标着“好看/不好看”的打分数据,要么是泛泛的图像描述,就像只给学生看了一堆画,却没告诉他们为什么好、怎么画才好。
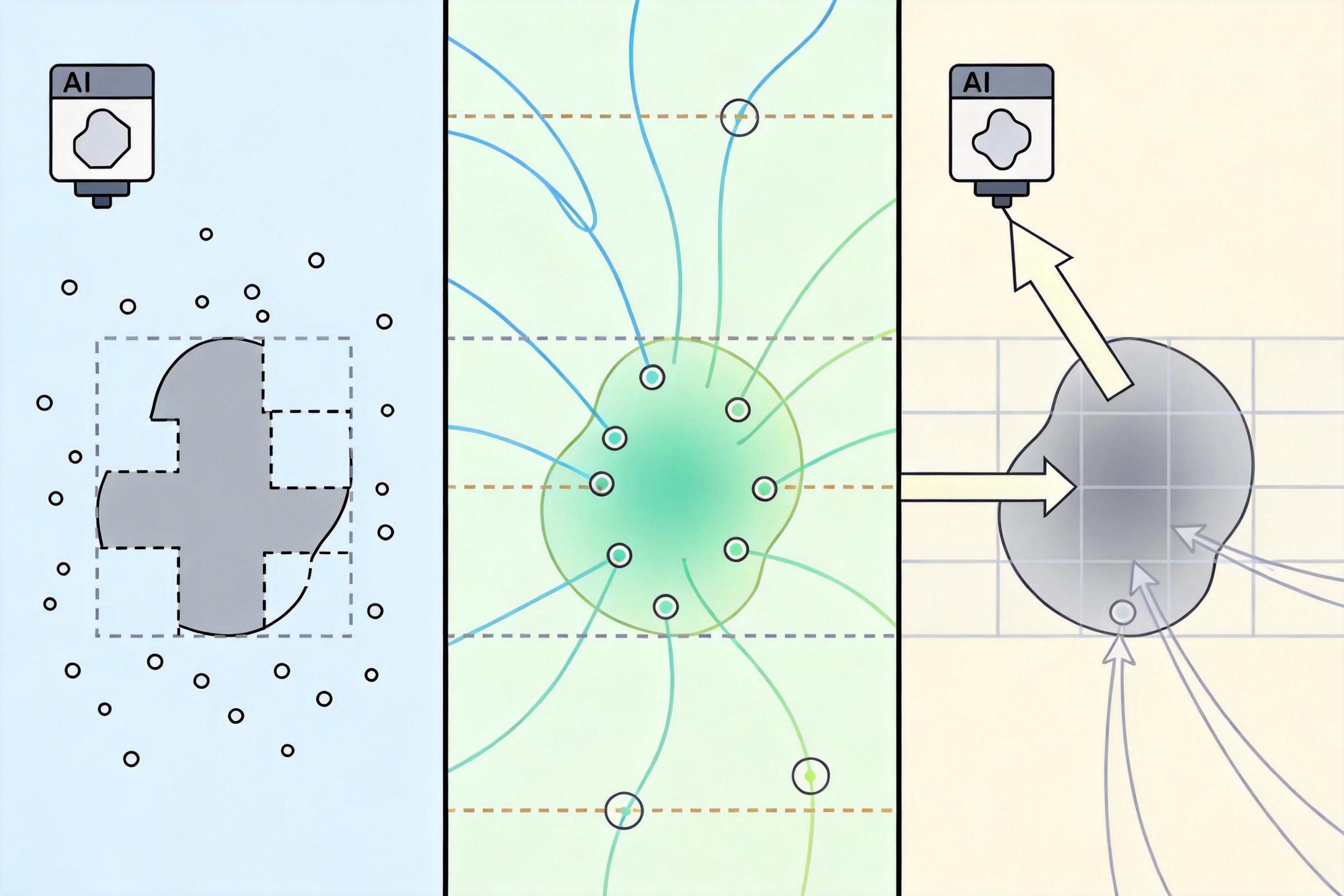
彭宇新团队的解法是打造了AesGuide数据集——10748张真实拍摄的照片,每张都配着专业摄影师的“问题诊断书”和“整改方案”:比如一张把游客拍在画面边缘的照片,标注会写“问题:主体偏离视觉重心,画面失衡;原因:拍摄时未遵循三分构图法;调整建议:后退半步重新取景,将人物移至右侧1/3处”。
这就像给AI请了20位专业摄影师当私教,把“看照片”变成了“学思路”。而不是像以前那样,只让它死记硬背“什么样的照片算好看”。
有了好教材,还要有对的教学方法。Venus模型的核心,是模仿人类审美思考的两个关键步骤:渐进式审美问答和思维链裁剪推理。
所谓渐进式审美问答,就是让AI像人看照片那样,从整体到细节一步步分析:先判断“这张照片整体感觉怎么样”,再拆解“问题出在构图还是光线”,最后给出“具体怎么调整”。这种从模糊到精准的推理链,就像你请摄影师点评时,他不会直接说“重拍”,而是先聊整体感受,再揪出细节问题,最后给你可落地的建议。团队在训练时,就用这种“整体印象-细致分析-可操作建议”的阶梯式提问,把AI的审美逻辑从“凭感觉”掰回“讲逻辑”。
而思维链裁剪推理,则是解决了AI“只会剪不会说”的老问题。以前的AI裁剪,只会闷头给你框出一个它觉得好看的区域,却解释不清为什么这么剪。Venus不一样,它会一边给你画裁剪框,一边告诉你:“裁剪掉左侧的空墙,是为了让人物成为视觉中心,符合紧凑构图原则”。这背后是团队让AI同时学习“裁剪坐标”和“构图逻辑”,每一次裁剪都得说出道理,相当于把AI的“黑箱操作”变成了“透明教学”。
说个有意思的细节:为了让AI的裁剪理由够专业,团队还搞了个“生成-校验-再生成”的闭环——先让GPT-4o写裁剪理由,再用另一个大模型Qwen2.5-VL-72B审核,不合格就打回去重写,直到逻辑通顺、符合摄影原理为止。
Venus的厉害之处,不止是能当摄影导师,更在于它第一次让AI的审美能力从“被动感知”变成了“主动输出”。
在AesGuide数据集的测试里,Venus系列模型在美学指导的准确性、完整性上,直接超过了GPT-4o、Gemini 2.0 Pro这些商业大模型;在开源的FLMS美学裁剪基准上,它甚至比专门做裁剪的AI模型表现更好,还能顺便给你讲明白裁剪逻辑。要知道以前的专用裁剪模型,就像只会干活不会说话的工匠,而多模态大模型又像只会说不会干的评论家,Venus第一次把两者的优势捏在了一起。

更重要的是,它打破了AI“只会赞美”的惯性。过去的AI面对有缺陷的照片,总倾向于说好听的,就像怕得罪人的老好人。但Venus会直接点出“画面左侧的电线杆抢了主体的风头”“光线太硬导致人物脸部阴影过重”——这种“敢说真话”的能力,才是普通用户真正需要的。
我们总说“审美是主观的”,但好的审美指导,从来不是给你一个标准答案,而是帮你找到表达自我的方法。Venus的出现,不是要替代摄影师,而是给每个普通人配了一个随时在线的“摄影启蒙老师”——它不会否定你的拍摄意图,只会告诉你怎么用技术把想法落地。
从“夸照片好看”到“教你拍得更好”,这一步的本质,是AI终于从“图像的观察者”变成了“创作的合作者”。审美无标准答案,但指导有可操作路径。未来当我们再举起手机拍照时,或许不用再羡慕别人的“摄影天赋”——因为AI已经把专业摄影师的思路,装进了我们的口袋里。