
14 天前
14 天前
2026年3月的OpenRouter平台上,小米一款大模型以4.82万亿Token的周调用量登顶全球第一——这是过去两年里,中国模型第一次在全球开发者的选择中碾压美国同行。此前谁也没想到,那些曾被调侃为“性价比选手”的国产大模型,会在智能体爆发的风口下,凭借一项叫MoE的技术,把全球AI产业链的执行环节变成了自己的主场。这背后到底藏着怎样的技术逻辑?又会如何改写全球AI的竞争格局?
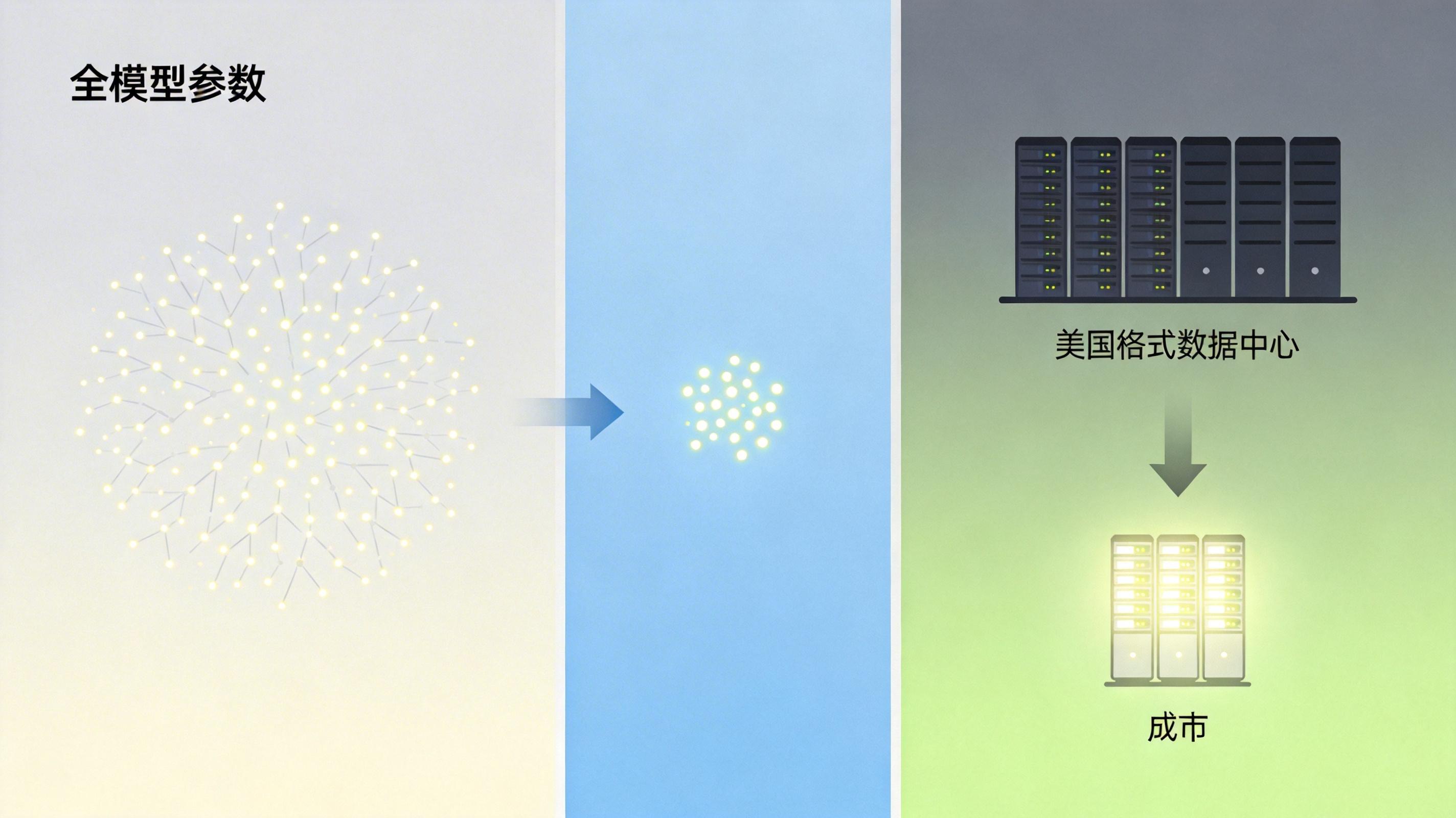
你可以把传统大模型想象成一个什么都管的全能办公室,不管是打印文件还是制定战略,全公司所有人都要一起加班;而MoE(混合专家模型)架构则是把办公室拆成了几十个专业部门——写代码的去编程部,做文案的去创意部,每次只让对应部门的人干活,其他人都能休息。
这种“稀疏激活”的逻辑,让国产大模型实现了参数规模和计算成本的解耦:比如DeepSeek的一款MoE模型总参数超过6000亿,但每个Token实际只激活约370亿参数,计算量直接砍到了传统模型的1/5。再配合中国低成本的自建算力集群——数据中心建设成本仅为美国的60%,电力成本不到美国的一半——国产模型的API价格能做到美国同行的1/10甚至更低。
更关键的是,MoE架构还能通过细分“专家”的分工,针对性提升特定任务的能力。在编程这个智能体的核心场景里,国产模型已经能和美国顶尖模型掰手腕:MiniMax的一款模型在SWE-Bench代码修复评测中拿到80.2%的得分,和Anthropic的Claude Opus 4.6仅差0.6个百分点。
2026年初,一款叫OpenClaw的智能体工具突然爆红,单周消耗超过6000亿Token——这个数字是2025年同期整个OpenRouter平台的一半。和传统聊天场景几千Token的消耗相比,智能体执行编程任务时,一次完整的“写代码-运行-报错-修改”循环就能消耗几十万Token,价格差距瞬间从“几毛钱的区别”变成了“每月几千美元的成本差”。
这波Token消耗的爆发,直接把国产大模型的性价比优势放大成了核心竞争力。开发者们开始用分层调用的策略:简单的文本生成用低价国产模型,复杂的逻辑推理再调用高价美国模型,平均成本能从每百万Token25美元降到2美元。甚至连美国的Anthropic都在官方文档里跟进了类似的分层设计,默认用便宜模型处理日常任务。
有意思的是,当大家都以为国产模型会靠低价一直走“AI富士康”路线时,2026年2月开始,智谱、腾讯云等厂商反而集体涨价,最高涨幅超过460%。但涨价并没有吓跑用户——智谱的调用量反而增长了400%。这说明国产模型已经跳出了“低价换规模”的陷阱,开始凭借技术能力和生态掌控力拿到定价权。
现在,约80%的美国开源AI初创公司都在使用中国模型——不是因为情怀,而是因为中国模型的开源策略和生态适配性,刚好踩中了全球开发者的痛点。比如DeepSeek的开源模型占全球开源模型下载量的30%,超过美国的15.7%,开发者可以免费下载、修改、部署,甚至商用,完全没有闭源模型的各种限制。
GitHub上的ClawRouter工具就是最好的例子:这个开源的智能路由工具能自动把不同任务分配给最合适的模型,用低价国产模型处理简单任务,用高价美国模型处理复杂任务,最多能节省92%的成本。它支持55+模型,其中一半以上是中国模型,已经集成到VS Code、Cursor等主流开发工具里,成了全球开发者的标配。
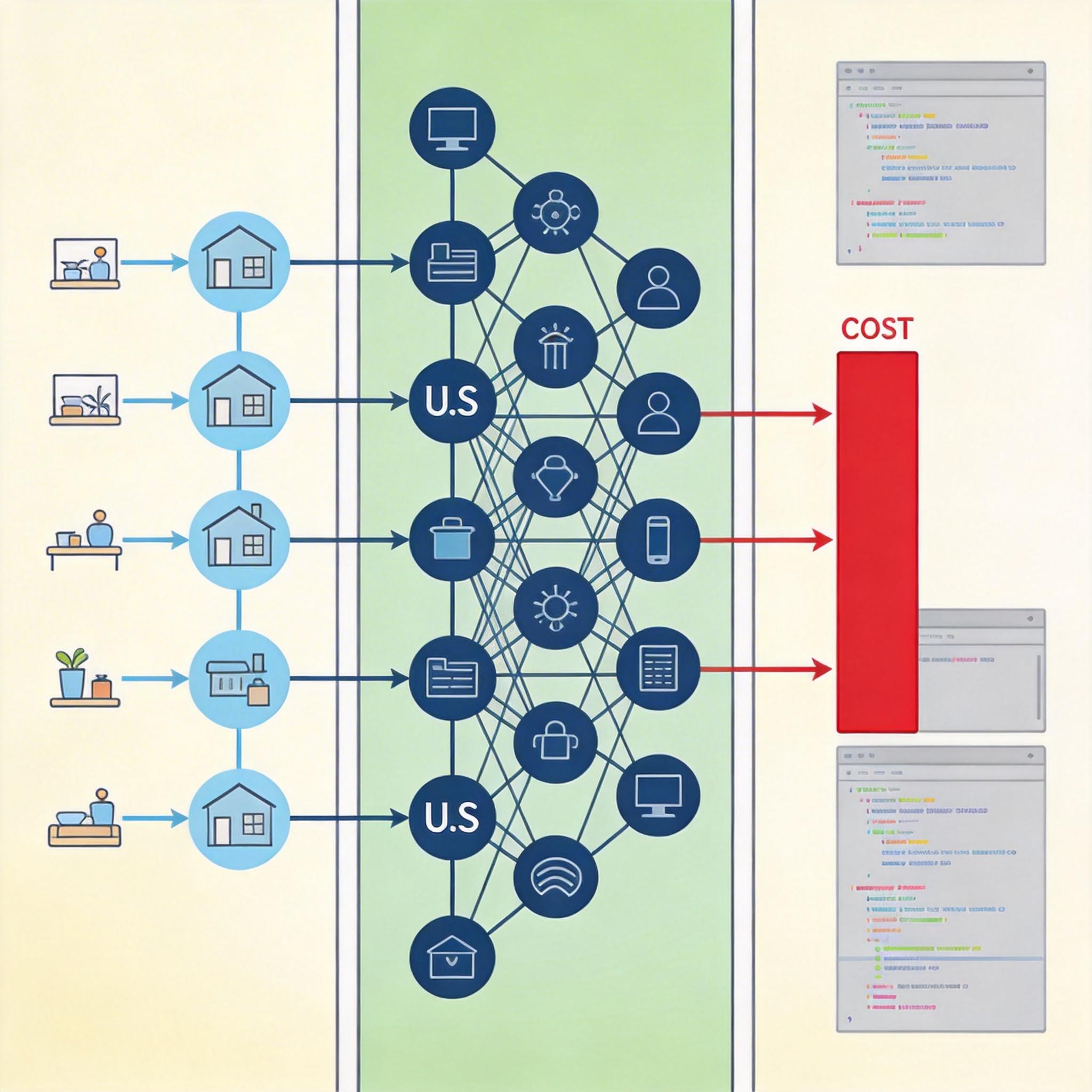
更值得注意的是,全球开发者对模型的“国籍”越来越不敏感,他们更关心的是性能、成本和交付速度。Airbnb、Siemens等国际企业已经公开采用中国模型,OpenRouter平台上中国模型的Token消耗占比超过60%——这不是简单的市场份额增长,而是全球AI产业链正在从“美国定义规则”向“多国协同创新”的新格局转变。
30年前,中国制造业靠成本优势切入全球电子产业链的组装环节;30年后,中国大模型靠MoE架构和算力优势,切入了全球AI产业链的执行环节。但这一次,我们不再是只能赚辛苦钱的代工厂——凭借开源生态和技术迭代,国产大模型正在从“成本竞争者”变成“规则参与者”。
算力不是一切,但能决定AI落地的速度和广度。当全球开发者都在为Token成本头疼时,国产大模型用技术给出了一个更高效的答案。未来的全球AI格局,或许不再是某一家独大,而是像MoE架构一样,由无数个专业的“专家”共同构建——而中国,已经在其中拿到了关键的一票。
算力定成本,技术夺话语权
点击充电,成为大圆镜下一个视频选题!