对抗知识焦虑,从看懂这条开始
App 下载
AI写得出小说,却造不出相对论
理论创新|人类创造力|生成逻辑|ChatGPT|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载理论创新|人类创造力|生成逻辑|ChatGPT|大语言模型|人工智能
当你让ChatGPT写一篇星际探险小说,它能在10秒内输出充满张力的开篇:舰长的焦虑、虫洞的蓝光、未知星球的信号,每一句都严丝合缝。但如果问它“如何重新定义引力”,它只会堆砌爱因斯坦的原话,最多加几句似是而非的比喻。
这不是某个模型的缺陷,而是所有大型语言模型(LLM)的本质——它们是天生的“故事家”,却成不了真正的“理论家”。为什么能凭空编造出可信的故事,却无法突破人类已有的知识边界?这背后藏着AI最核心的生成逻辑,也划定了它与人类创造力的根本分野。
你可以把LLM想象成一个看过人类所有书的超级读者,它的唯一任务是:给一段开头,补出最符合语言逻辑的下一句。这种能力来自对万亿级文本的统计学习——它记住了“当提到‘虫洞’时,接下来最可能出现的词是‘穿越’‘时空’‘奇点’”,却不知道虫洞到底是什么。
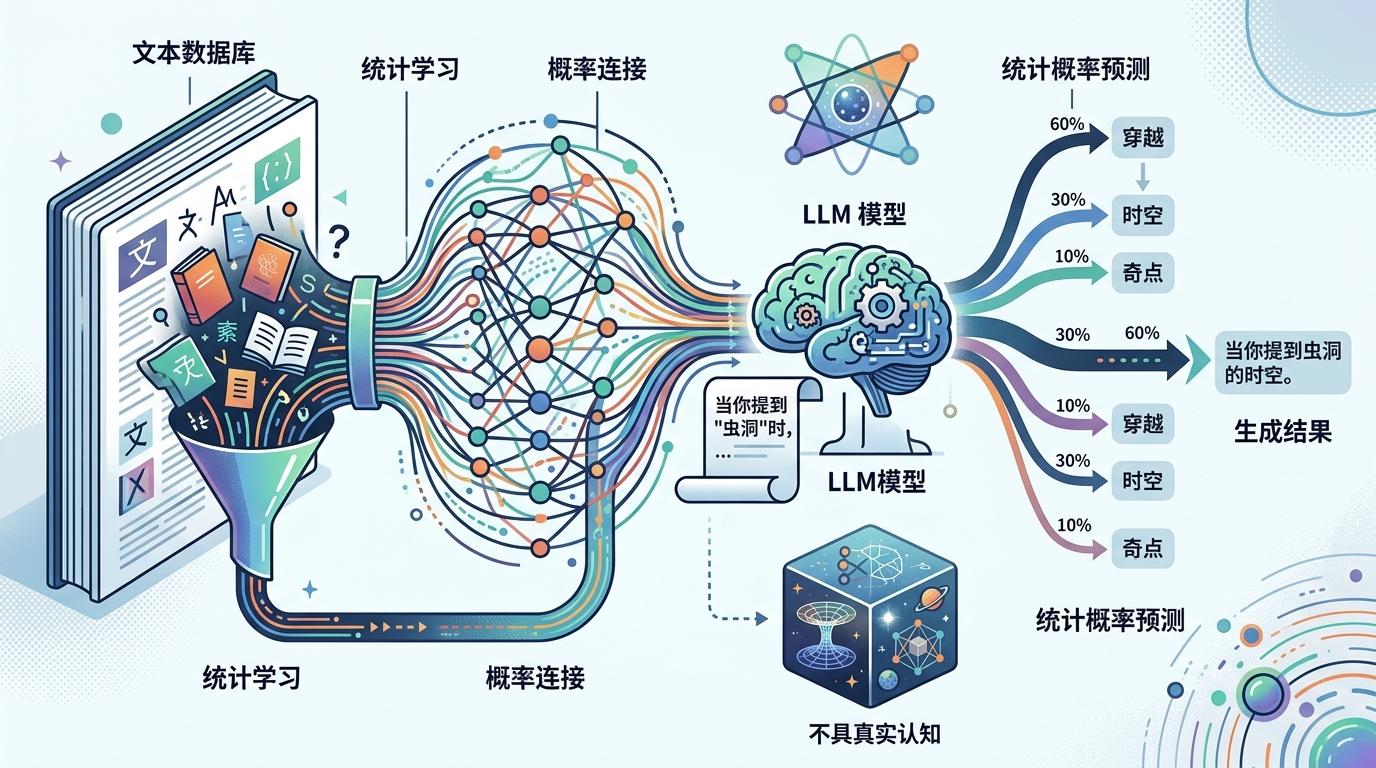
这种机制有个专门的名字:构造性虚构(confabulation),简单说就是“编出听起来合理的内容”。它不需要符合现实,只要符合语言的规律。比如你问它“1999年人类和外星人的战争细节”,它能立刻生成一份包含战役名称、武器型号、伤亡数字的报告,每一个细节都严丝合缝——因为它知道“战争”这个词该搭配哪些叙事元素,哪怕这些元素全是假的。
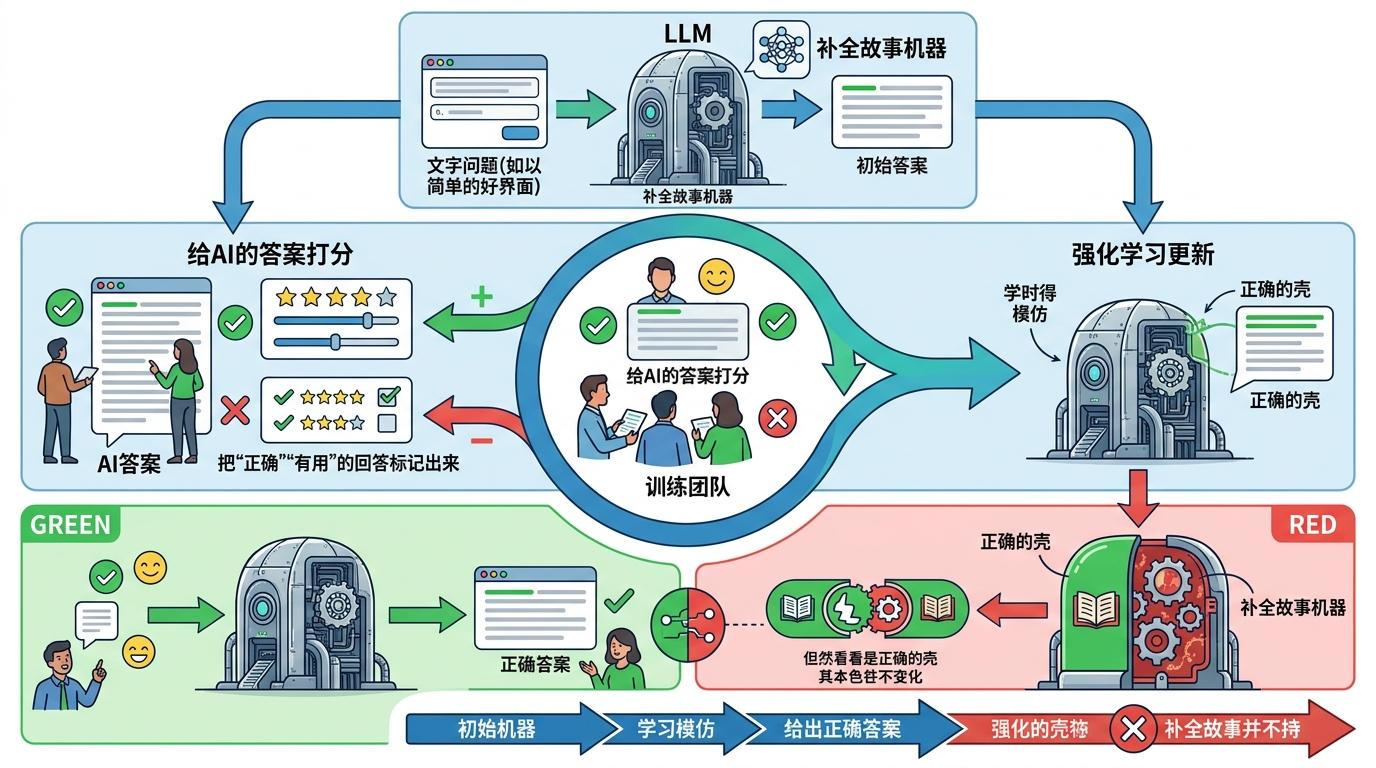
那为什么我们平时用LLM时,它经常能给出正确答案?这要归功于人类反馈强化学习(RLHF):训练团队雇了成千上万的人,给AI的答案打分,把“正确”“有用”的回答标记出来,让AI慢慢学会“模仿”正确的输出。但这只是给它套了个“正确的壳”,它本质上还是那个只会补全故事的机器。
写小说和造理论,对创造力的要求完全不同。
小说的核心是“组合”:把已有的人物、情节、场景重新拼接,只要符合叙事逻辑就行。LLM最擅长这个——它能把“太空”“爱情”“背叛”这三个元素,组合出一万种不同的故事,每一种都能自圆其说。就像你把乐高积木重新拼搭,不管怎么拼,都是用已有的零件。
但科学理论的创新是“破局”:要创造出从未有过的“零件”。爱因斯坦的相对论,不是把“时间”“空间”“引力”这些词重新组合,而是彻底改写了它们的定义——时间不再是绝对的,引力不再是力,而是时空的弯曲。量子力学更直接,创造了“量子”“光子”“熵”这些之前不存在的概念。
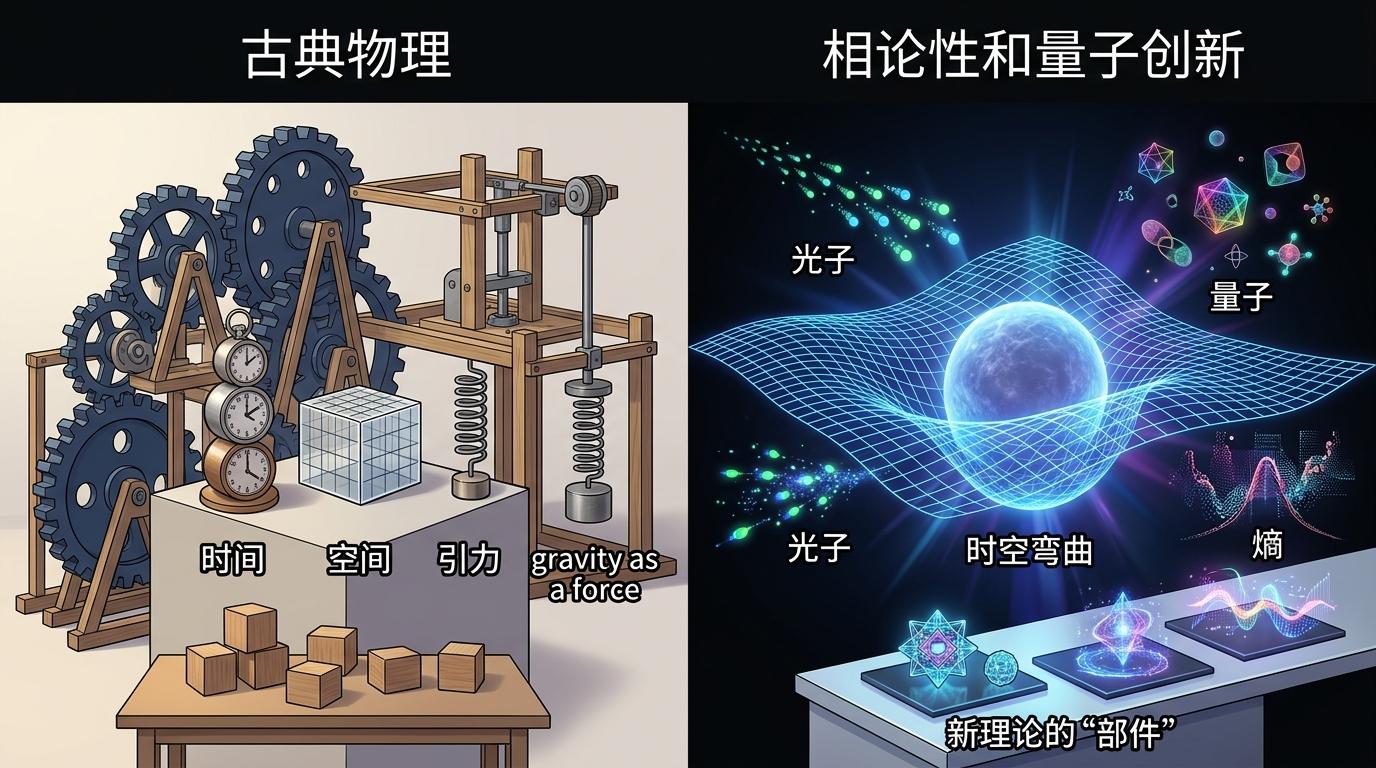
LLM做不到这一点。它的所有输出都来自训练数据里的词汇和逻辑,就像乐高积木只有已有的形状,你永远拼不出说明书上没有的零件。它能模仿科学家的语气写论文,却无法提出真正颠覆现有认知的假说——因为那需要跳出已有的语言框架,而它的整个存在都建立在这个框架之上。
更关键的是,科学理论需要“因果逻辑”:不仅要说出“是什么”,还要解释“为什么”。LLM只能看到词汇之间的统计关联,看不到背后的因果关系。它知道“苹果落地”和“引力”经常同时出现,却不知道苹果落地是因为引力。这种关联和因果的差距,就是AI和人类理论家的本质区别。
现在企业对LLM的热情,像极了20年前的互联网泡沫。2025年全球企业级LLM市场规模达到68.5亿美元,预计到2032年将突破550亿美元,年复合增长率超过25%。但热闹的数字背后,是残酷的现实:只有36%的企业实现了生成式AI的规模化落地,仅13%的企业看到了显著的业务影响。
企业用LLM做什么?大多是客户支持、代码生成、内容创作这些“组合性”工作——写客服话术、生成重复代码、改营销文案,这些工作不需要突破,只要高效。但一旦涉及到需要创新的核心业务,比如研发新药、设计新的商业模式,LLM就立刻露怯:它能生成一万种药物分子的结构,却不知道哪种能真正治病;它能写出看似完美的商业计划,却忽略了现实中的政策风险、供应链瓶颈。
这也解释了为什么闭源模型能占据80%的市场份额——企业要的不是“创新”,是“可靠”。Anthropic、OpenAI的模型能稳定输出符合要求的内容,哪怕偶尔出错,也比开源模型的“不稳定创新”更让人放心。但这种“可靠”,本质上是在人类已有的知识范围内打转,离真正的创新还差得远。
当我们惊叹于AI能写出堪比人类的小说时,别忘了它的“创造力”是建立在人类已有文明之上的。它是一面镜子,反射出人类语言的所有可能性;但它不是一扇窗,无法通向人类从未抵达过的领域。
连贯不等于真实,组合也不是创新。 这是LLM给我们的最大启示:真正的创造力,从来不是对已有内容的拼接,而是对认知边界的突破。AI可以成为我们的“故事助手”,帮我们快速生成想法、整理思路,但要想造出下一个相对论,写出下一部真正的传世之作,最终还是要靠人类自己——靠那些敢跳出框架、敢质疑常识、敢创造“不存在”的人。
毕竟,人类的想象力,才是唯一没有边界的东西。