对抗知识焦虑,从看懂这条开始
App 下载
S3变文件系统:不用搬数据也能秒读秒改
科研数据|EFS|高性能文件系统|对象存储|S3 Files|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载科研数据|EFS|高性能文件系统|对象存储|S3 Files|AI产业应用|人工智能
想象一下:你存了几十TB的科研数据在云端对象存储里,想用来跑AI训练,却发现传统工具根本没法直接读取——要么得花几天把数据全搬去文件存储,要么用模拟工具凑活,结果延迟高到拖垮GPU利用率。这是过去十年里,无数做AI、大数据的团队天天要面对的麻烦。直到2026年4月,AWS推出的S3 Files把这个死结解开了:不用搬迁任何数据,就能把S3直接当成高性能共享文件系统用。这不是简单的功能叠加,而是把对象存储和文件系统的核心能力真正焊在了一起。
你可以把S3 Files的逻辑看成三层:最底层是作为「数据真源」的S3,存着所有原始数据;中间层是EFS——亚马逊的弹性文件系统,负责承接需要低延迟访问的活跃数据和所有元数据;最上层是给用户用的文件系统接口,支持完整的POSIX权限、文件锁和一致性。
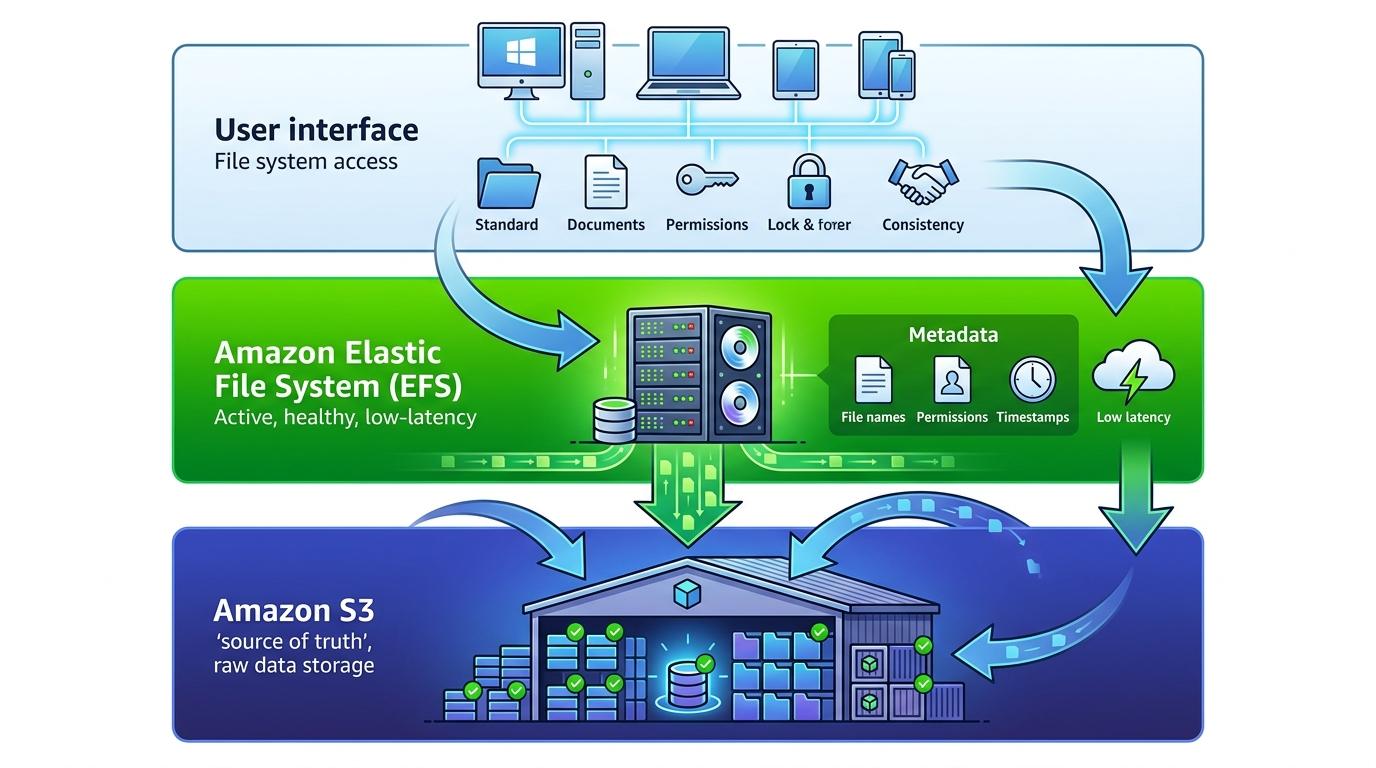
和之前那些在访问层做模拟的工具不同,S3 Files是直接把EFS的原生文件系统能力嫁接到了S3上。当你挂载一个S3桶时,系统不会把全量数据搬去EFS,而是只把你正在用的「工作集」——比如AI训练要读的一批小文件、频繁修改的配置文件——缓存到EFS里。这些数据在EFS里能享受到1ms级的读延迟,还支持上万个计算节点同时共享访问,完全是正经文件系统的体验。
更关键的是,所有修改都会先落到EFS,再由后台自动同步回S3,S3始终是最终的权威数据源。就算EFS出了问题,只要同步完成,数据就不会丢。
但S3 Files也不是什么场景都能打。它的优势和局限,全藏在「按需缓存」和「异步同步」这两个核心机制里。
先说小文件和大文件的区别:默认情况下,只有小于128KB的文件会被完整缓存到EFS,更大的文件只存元数据,读的时候直接从S3流式拉取。这意味着如果你的AI训练用的是10MB一张的图片,就算挂载了S3 Files,大部分读取还是要走S3的原生路径,延迟和直接用S3差不多。
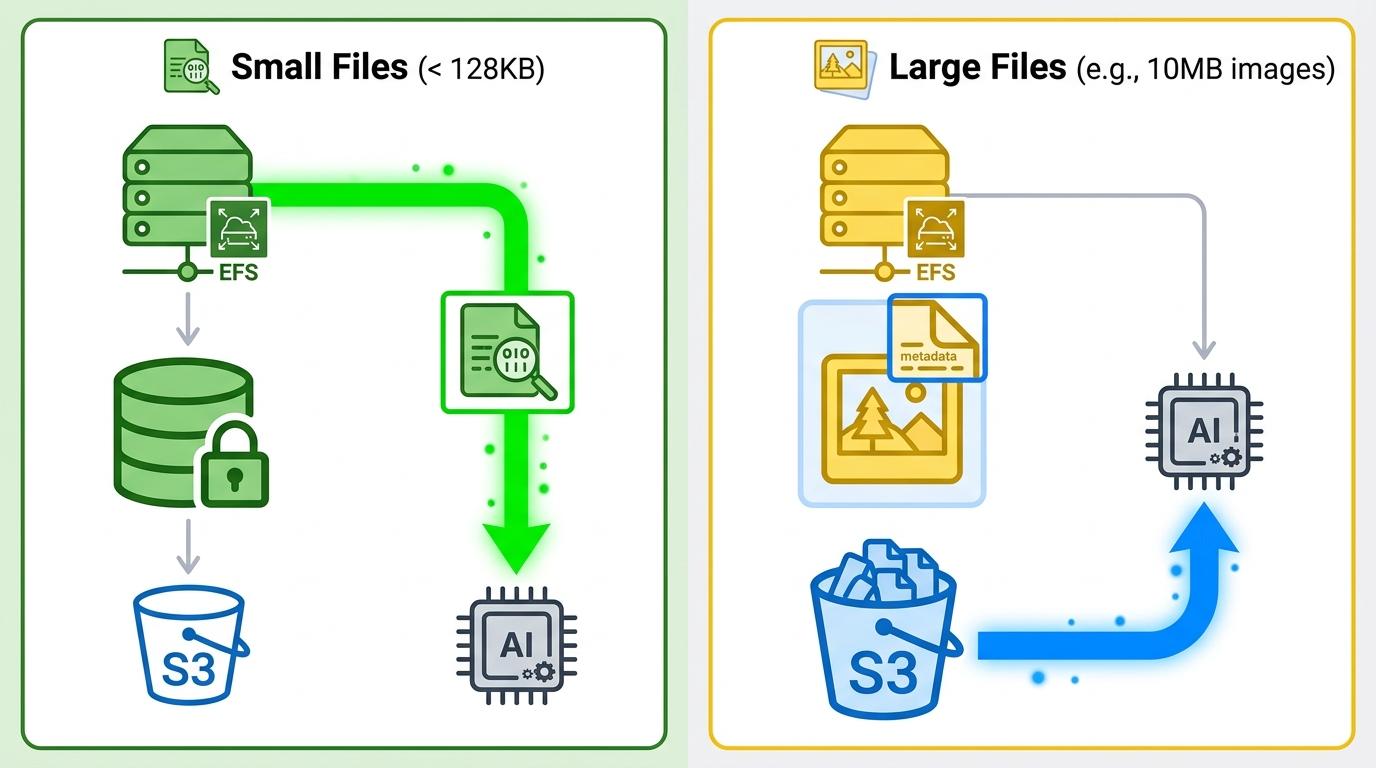
再看写入:所有写操作都要先过一遍EFS,再异步同步回S3。如果是一次性写几百TB的训练结果,相当于数据要在EFS里先待一段时间,不仅会多花EFS的存储费,同步的时候还要额外走一遍数据流转——按某区域的价格算,每写1TB就要多花约90美元的附加成本。
还有个容易踩坑的点:S3的扁平命名空间,决定了S3 Files的目录重命名本质是把目录里的每个对象都重新写一遍。如果目录里有上千万个文件,这个操作可能要跑几个小时,期间文件系统和S3的数据还会不一致。
把S3 Files和同类方案放在一起比,就能更清楚它的定位:
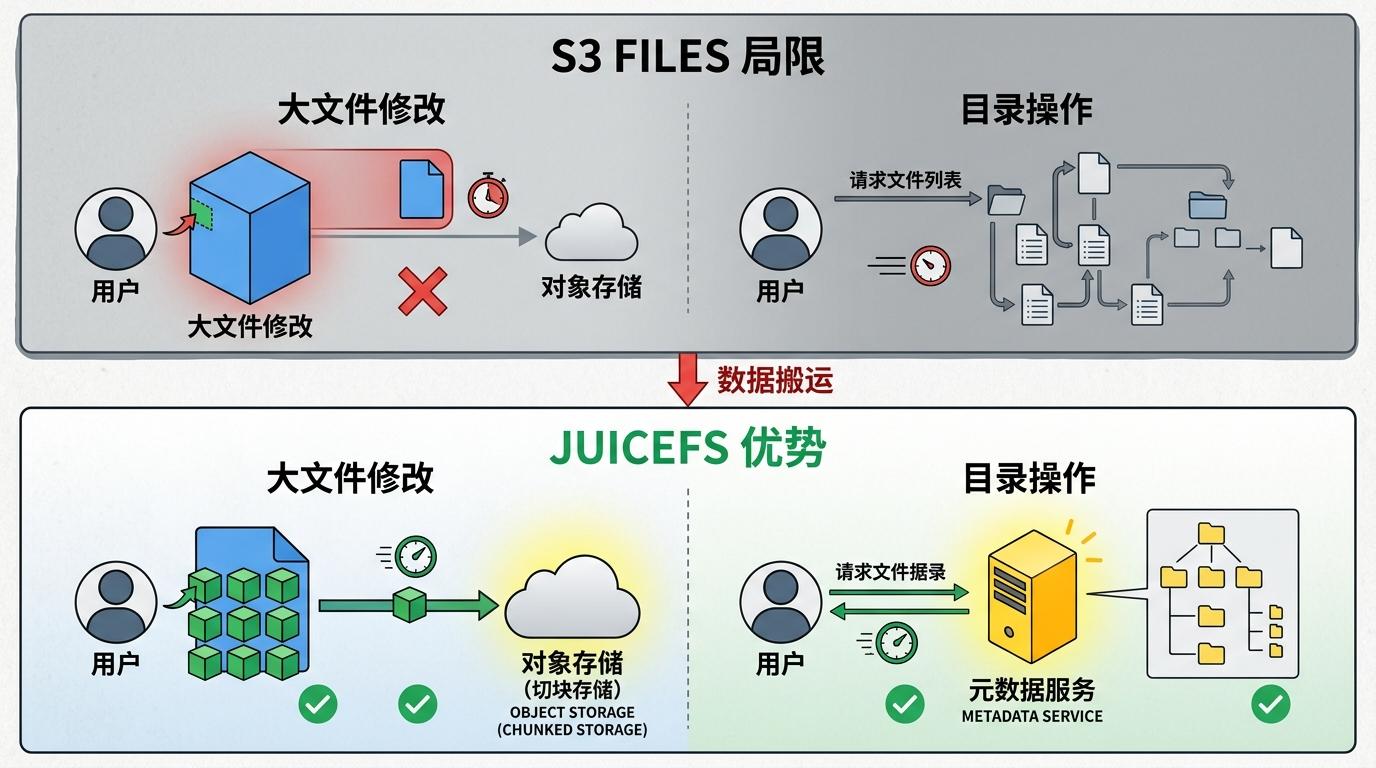
和早期的s3fs、后来的Mountpoint比,S3 Files的优势是真·文件系统语义——支持文件锁、多节点共享一致性、POSIX权限,这些是那些模拟工具根本做不到的。比如AI多代理协作,多个代理要同时读写同一个共享目录,用Mountpoint可能会出现数据覆盖,用S3 Files就没问题。
但和JuiceFS这种在对象存储上重新做元数据的分布式文件系统比,S3 Files的局限就出来了:JuiceFS会把大文件切成小块存,局部修改不用重写整个对象,目录操作也快得多,但它需要额外部署元数据服务,还得把数据从S3转成自己的格式——相当于还是要搬数据。
总结下来,S3 Files最适合的场景是:不想动现有S3数据,又需要用文件系统接口访问,且以小文件、只读或轻量写为主的场景——比如传统应用上云、AI训练的小数据集读取、多团队共享文档。但如果是大文件随机写、大规模持续输出结果的场景,它的成本和延迟都会让你头疼。
S3 Files的出现,本质上是云厂商在「不搬数据」和「好用」之间找到的一个平衡点。它没有试图颠覆对象存储的底层逻辑,而是用EFS做了个柔软的缓冲,把对象存储的扩展性和文件系统的易用性捏在了一起。
未来十年,对象存储和文件系统的融合会是必然趋势,但不会只有一条路:像S3 Files这样的「原生嫁接」方案,会成为轻量场景的首选;而那些重新构建元数据的分布式文件系统,会在重负载场景里站稳脚跟。
数据不用搬,接口随心换——这可能是云存储最实在的进步:不是追求技术上的极致,而是解决用户每天都要面对的麻烦。