对抗知识焦虑,从看懂这条开始
App 下载
说方言赚红包,背后是AI的方言补课计划
语音转写准确率|红包激励|数据采集活动|方言语音识别|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载语音转写准确率|红包激励|数据采集活动|方言语音识别|AI产业应用|人工智能
当你用带着乡音的普通话发语音时,有没有过转出来的文字驴唇不对马嘴的尴尬?对AI来说,那些和普通话差异显著的方言,曾是一道难以逾越的坎——直到有人开始用现金红包,换用户开口说家乡话。
这不是什么营销噱头,而是一场针对AI语音识别的「数据急救」。中国的方言多达百余种,光是声调就能有八九个变体,可过去的语音识别模型,几乎是在普通话的单一语境里训练出来的。面对夹杂方言的语音,它就像听外语的新手,连声母韵母都对应不上,更别说理解语义。而这次的红包活动,就是要补上最稀缺的真实方言数据——那些来自不同年龄、地域、场景的口语样本,是实验室里合成不出来的「活数据」。
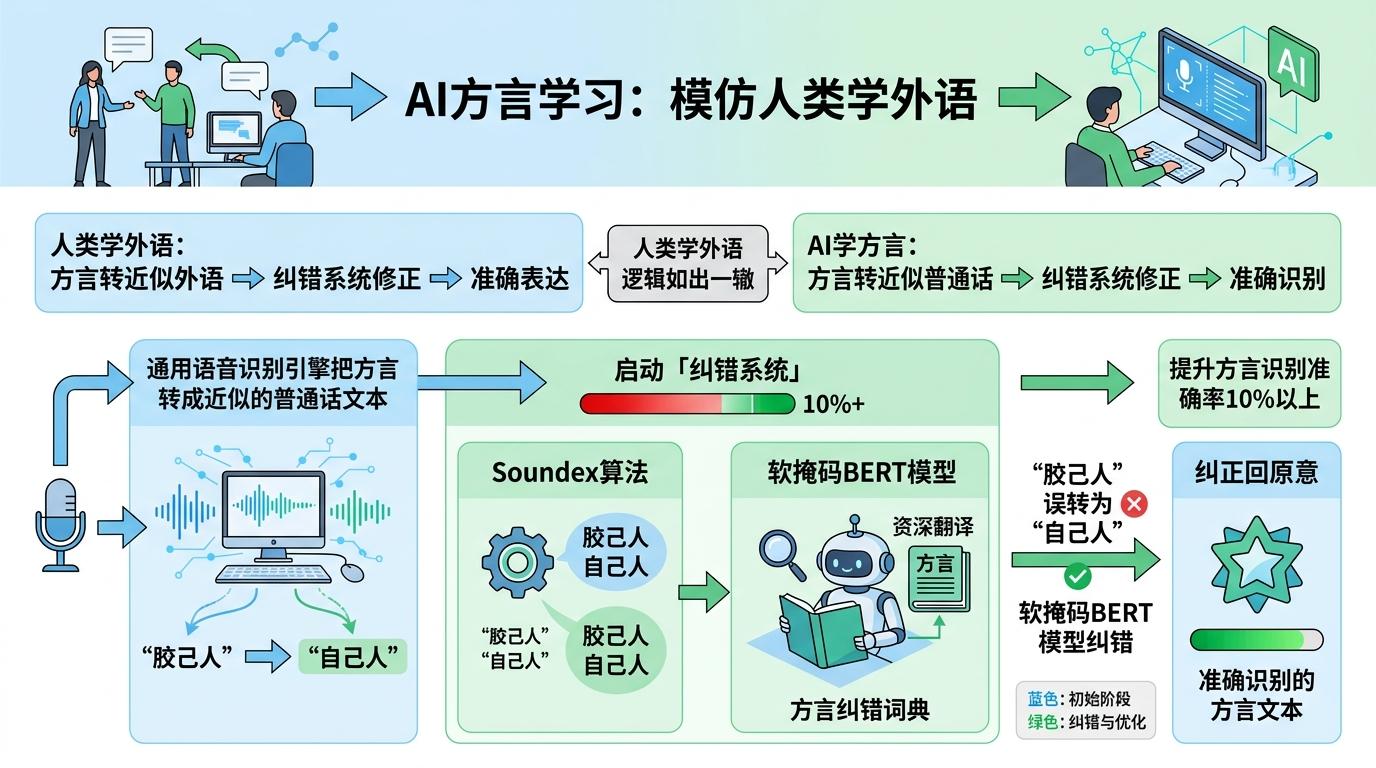
你可能想不到,AI学方言的过程,和人类学外语的逻辑如出一辙。它先靠通用语音识别引擎把方言转成近似的普通话文本,就像你用蹩脚的英语直译家乡话,然后再启动「纠错系统」:用Soundex算法把发音相似的词归为一类,再让软掩码BERT模型像资深翻译一样,对照方言纠错词典修正错误。比如把潮汕话里的「胶己人」,从误转的「自己人」改回原意,这个过程能让方言识别的准确率提升10%以上。
更聪明的是,AI还学会了「借鸡生蛋」。当某类方言的真实数据不足时,它会用合成语音技术生成模拟样本,和真实数据混合训练。就像你学一门小语种,找不到语伴就先听广播跟读,合成数据的纯净性能帮AI快速掌握发音规律,再结合真实数据打磨细节。这种混合训练的方式,能让低资源方言的识别错误率降低近5%。
但这场AI的方言补课,也藏着待解的难题。比如那些仅在小范围使用的方言,连足够的词汇词典都没有,AI根本无从纠错;还有方言里的俚语、谐音梗,背后是特定的地域文化,光靠语音和文字匹配远远不够。更重要的是,如何在收集数据时保护用户隐私——毕竟每一段方言语音,都藏着说话人的身份特征,稍有不慎就可能泄露信息。
当AI终于能听懂你的家乡话,它改变的不只是语音输入的体验。对那些不习惯说普通话的老人、偏远地区的用户来说,这是一把打开数字世界的钥匙;对地域文化而言,AI的记忆库也成了方言的数字存档。技术从来不是冷冰冰的工具,当它开始学着理解每一种乡音,其实是在试着读懂每一种生活。