对抗知识焦虑,从看懂这条开始
App 下载
AI算力卡脖子?存算一体正在破局
低功耗推理|冯·诺依曼架构|存算一体|先进材料|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载低功耗推理|冯·诺依曼架构|存算一体|先进材料|AI算力|前沿科技|人工智能
2026年春天,中国日均AI token调用量突破140万亿——这个数字比2024年初翻了1000倍。AI智能体、多模态聊天、长文本推理的爆发,让市场对大吞吐、低功耗的推理算力需求呈指数级增长。但传统算力卡却卡在了一道看不见的墙上:数据在存储和计算单元之间来回搬运,99%的能耗都耗在了“运输路”上,真正用在计算上的能量不足1%。当AI的需求已经飙到了天花板,传统架构却还在原地踏步,这道“存储墙”,到底要怎么破?
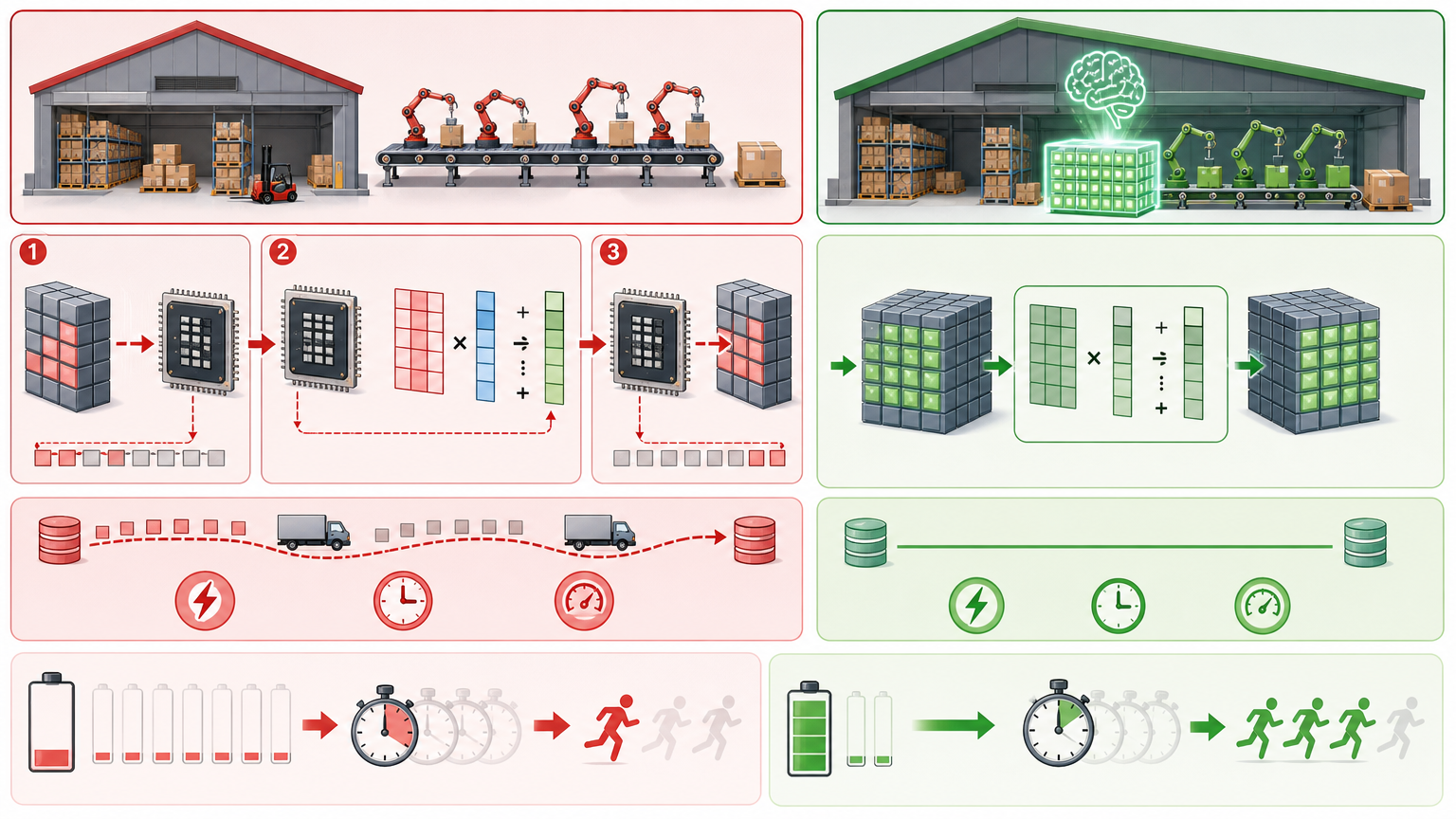
要理解存算一体的价值,得先回到现代计算机的“老祖宗”——冯·诺依曼架构。你可以把它想象成一间分工明确的工厂:计算单元是车间,存储单元是仓库,数据和指令就是原材料。车间要生产,必须先从仓库把原材料运过来,做完了再把成品送回去。在AI还没爆发的年代,这种分工高效又清晰,支撑了计算机行业近百年的发展。
但AI时代的到来,把这套体系彻底逼到了极限。现在的大模型动辄千亿级参数,相当于仓库里堆了一座原材料大山,车间每做一个零件,就得来回跑几十趟搬运。根据图灵奖得主约翰·轩尼诗的测算,现在AI计算中数据搬运的成本,已经是计算本身的100倍。更要命的是,仓库到车间的“公路”带宽有限,原材料运不过来,车间再先进也得停工待料——这就是业内头疼的“存储墙”和“带宽瓶颈”。

传统算力卡的解决方案,无非是把仓库建得更大、把公路修得更宽,但这都是治标不治本的办法。直到存算一体的出现,才真正跳出了冯·诺依曼的框架:既然搬运这么费事儿,那干脆把车间搬进仓库里。
存算一体的核心逻辑,说穿了就是“近水楼台先得月”——把计算电路直接嵌入存储阵列,让数据在存储单元里就地完成计算,彻底减少甚至消除数据搬运。
你可以把它想象成在仓库里直接搭建生产线,原材料不用挪窝就能变成成品。以AI最核心的矩阵乘加运算为例,传统架构需要把权重数据从存储单元读到计算单元,做完运算再写回去;而存算一体直接在存储单元里完成乘法和累加,数据全程不用离开仓库。这样一来,不仅能耗能降到原来的几十分之一,计算速度也能提升几倍甚至几十倍。
当然,存算一体也不是只有一条路。目前业内主要分为模拟和数字两大技术路径:模拟存算利用存储介质的物理特性直接计算,能效极高,但精度和稳定性有待提升;数字存算则用数字电路实现计算,精度高、兼容性好,是当前产业化的主流方向。国内某团队的数字存算产品,在长上下文推理场景中,能效和吞吐指标已经实现了突破性提升,单卡处理token的能力是传统算力卡的数倍。

存算一体的优势显而易见,但从实验室走到产业化,还有三道坎要跨。
第一道坎是算法的快速迭代。AI领域平均每2-3年就会出现新的主流范式,今天为大语言模型设计的硬件,明天可能就跟不上多模态模型的需求。这就要求存算一体硬件必须具备足够的通用性,不能“一招鲜吃遍天”。国内某早期玩家就选择了“通用存算一体”路线,不绑定单一存储介质,能兼容SRAM、3D DRAM等多种存储技术,还能通过指令集兼容CUDA等主流软件生态,降低开发者的迁移成本。
第二道坎是工程实现的难度。不同存储介质在密度、功耗、读写性能上各有优劣,如何根据应用场景选择合适的介质,同时解决3D堆叠、异构融合等工程问题,对研发团队是极大的考验。比如3D DRAM能提供大容量和高带宽,但制造工艺复杂、成本高;SRAM速度快、精度高,但存储密度低。研发团队需要在这些参数之间找到最优解。
第三道坎是软件生态的兼容。当前AI开发高度依赖CUDA等成熟生态,新架构如果不能兼容这些工具链,就很难获得开发者的认可。这就要求存算一体厂商不仅要做好硬件,还要在编译器、算子优化等软件层面下功夫,实现“能跑”更要“跑得好”。
当AI的需求像潮水一样涌来,传统算力架构已经撑不起这片蓝海。存算一体不是万能的“银弹”,它无法替代CPU、GPU等传统计算架构,但在AI推理、边缘计算等数据密集型场景中,它能发挥出不可替代的作用。
未来的AI算力体系,必然是多种架构互补共存的生态:CPU负责通用计算,GPU负责大规模并行计算,存算一体则专攻高吞吐、低功耗的推理场景。而存算一体真正的价值,不仅是突破了“存储墙”的技术瓶颈,更是为中国半导体产业提供了一条差异化的突破路径——在先进制程受限的情况下,通过架构创新实现算力的弯道超车。
存算一体,不是对过去的颠覆,而是对未来的补位。