对抗知识焦虑,从看懂这条开始
App 下载
推荐系统的隐藏瓶颈:语义ID终于能跟着推荐学了
推荐准确率|RQ-VAE模型|生成式推荐|DIGER框架|语义ID|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推荐准确率|RQ-VAE模型|生成式推荐|DIGER框架|语义ID|AI产业应用|人工智能
你有没有过这种经历:刷电商平台时,明明刚买了一款面霜,首页却还在疯狂推送同款?不是算法笨,是它背后的「商品身份证」出了问题。传统推荐系统里,商品的「语义ID」——相当于它的「内容身份证」——是提前固定好的,只负责精准还原商品内容,却不管用户会不会真的感兴趣。直到格拉斯哥大学、山东大学等团队的DIGER框架出现,才第一次让推荐效果能反过来调教这张「身份证」,在三个公开数据集上把推荐准确率拉了最高10%。这背后,是生成式推荐领域卡了好几年的死结终于被解开。
你可以把传统生成式推荐的流程想象成「先做身份证,再办业务」:第一步用RQ-VAE这类模型给每个商品生成语义ID——就像把面霜的「保湿、敏感肌适用、玻璃包装」这些信息压缩成一串短码;第二步把这些固定好的短码丢给推荐模型,让它学「用户会点哪个短码」。
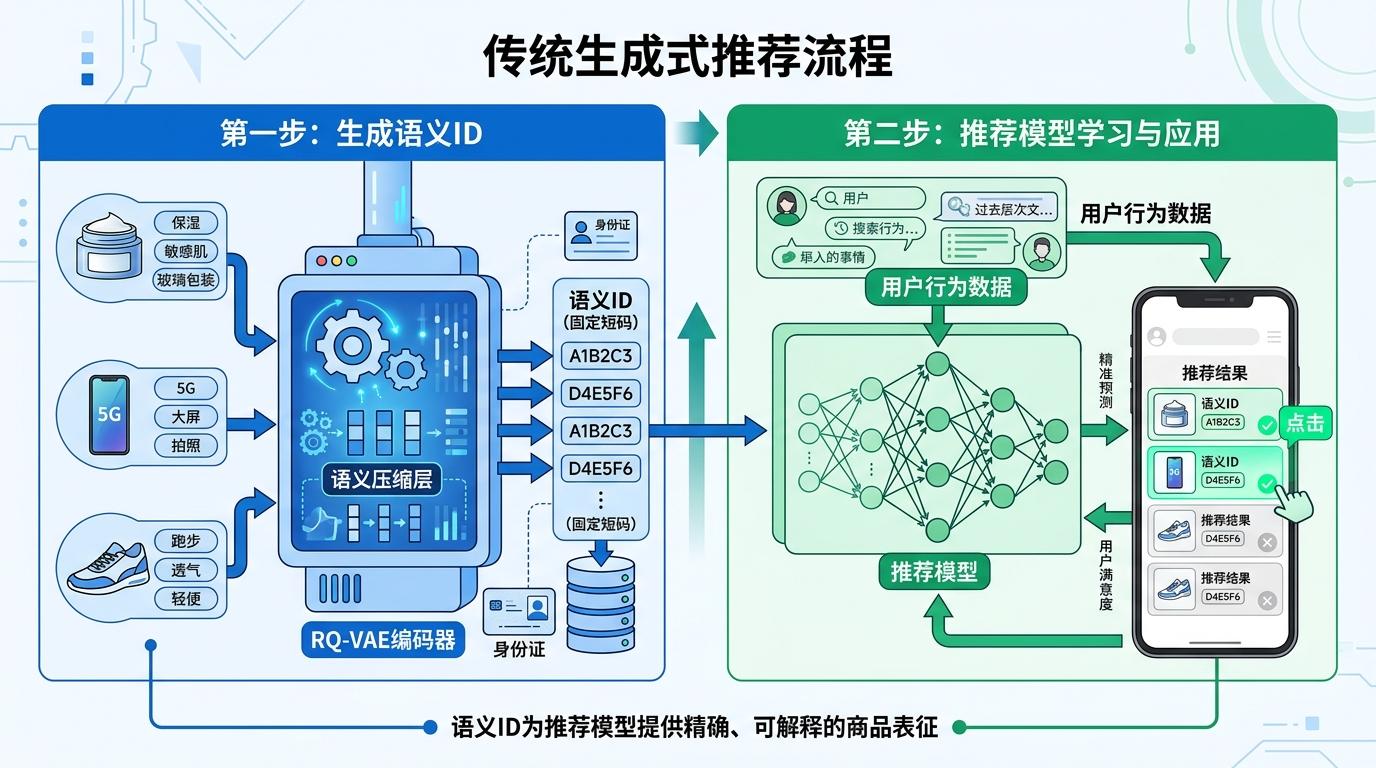
问题恰恰出在这两步的割裂上。生成语义ID的目标是「精准还原商品内容」,就像身份证要拍清楚你的脸;但推荐模型的目标是「猜中用户喜好」,相当于银行要判断你能不能贷款。这两个目标根本不是一回事——一款面霜的语义ID还原得再精准,也未必能帮模型判断「刚买过面霜的用户现在需要的是面膜」。
更关键的是,推荐模型就算发现了这个问题,也没办法改身份证——因为语义ID是提前冻结的,推荐效果的好坏传不到生成ID的环节里。就像银行明明知道你有稳定收入,却没法改你身份证上的「无业」标注。
DIGER的核心,就是给这张「固定身份证」装了个可调节的开关,让推荐效果能反过来调整语义ID的生成。
首先,它用Gumbel噪声替代了传统的「硬选择」——就像给身份证照片加了点模糊效果,让模型在训练初期不会死盯着某几个短码,而是多试试不同的组合,避免出现「几百个短码只用得上几个」的「码本塌缩」问题。
然后,它设计了两种「不确定性衰减」策略:一种是随着训练推进慢慢降低噪声,让模型从「广撒网试错」过渡到「精准锁定最优解」;另一种是盯着那些被用得太频繁的短码,主动给它们加噪声,逼着模型去发掘那些被冷落的短码。
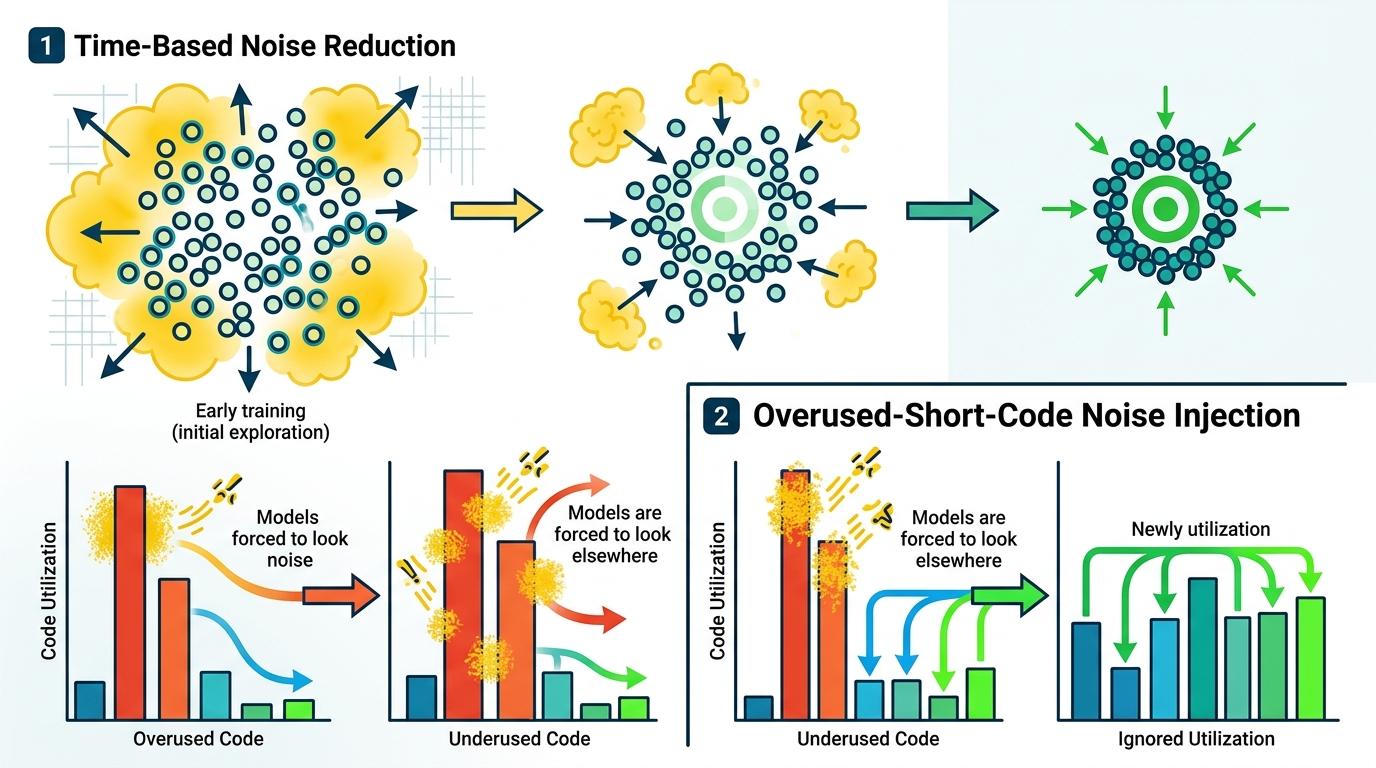
这套机制的效果很直接:在亚马逊Beauty数据集上,DIGER把Top10推荐召回率从6.1%拉到了最高6.96%;在Yelp数据集上,也稳定把召回率提升了0.25到0.32个百分点。更重要的是,它解决了传统方法的「码本塌缩」——原本只有少数短码被激活,现在几乎所有短码都能被用到,语义空间的利用率翻了好几倍。
DIGER的意义,其实不止于推荐系统。它本质上解决了一个机器学习领域的共性问题:当系统依赖离散的中间表示(比如语义ID、离散token)时,要不要让这个表示跟着最终任务一起优化?
过去的默认答案是「先学好固定表示,再做任务」,就像先学好单词再写作文。但DIGER证明了,只要设计好训练机制,让离散表示跟着任务走,能拿到更好的结果——就像一边写作文一边调整单词的用法,最终的文章会更贴合主题。
当然,它也不是完美的。比如目前它只优化了商品侧的语义ID,还没涉及用户侧的表示;而且在超大规模数据集上,训练效率还有提升空间。但不管怎样,它给生成式推荐指了一条新的路:与其让推荐模型去适配固定的语义表示,不如让语义表示主动适配推荐目标。
你刷到的每一条推荐背后,都是无数个模型在「猜你喜欢」。但过去的推荐模型,就像拿着固定字典猜谜语的人——字典里的字是死的,猜对全靠运气。
DIGER第一次让这本字典活了起来:推荐错了,字典里的字就会悄悄调整,下次猜中的概率就更高。这背后藏着一个更重要的信号:AI系统的进化,正在从「优化任务模型」转向「优化任务与表示的协同」。
好的表示,从来不是固定的,而是为任务而生的。 或许用不了多久,你刷到的推荐就不再是「算法觉得你需要」,而是「算法懂你需要」。