对抗知识焦虑,从看懂这条开始
App 下载
不堆参数的AI,摸到了性价比的天花板
帕累托前沿|调用成本|智能评分|xAI|Grok 4.3|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载帕累托前沿|调用成本|智能评分|xAI|Grok 4.3|大语言模型|人工智能
当所有人都在盯着AI模型的参数数字——1万亿、1.5万亿,比谁堆得更大时,有个模型悄悄换了赛道。它把参数维持在5000亿,却让智能评分涨了4分,在真实工作任务中的胜率超过上一代87%;更狠的是,它把调用成本砍了六成,跑完全套行业测试的花费,只有顶尖模型的1/12。
这不是什么小众实验室的玩具,而是xAI推出的Grok 4.3。它被评测机构放在了一个特殊的位置:智能与成本的帕累托前沿——那条「再便宜就会变笨,再聪明就得加钱」的临界线。为什么不堆参数反而能做到两全其美?这背后藏着AI行业正在发生的悄悄转向。
你可以把AI大模型想象成一个超级图书馆:参数是书架的数量,训练数据是架上的藏书,而推理机制就是找书、读书、整理答案的方法。过去大家都在疯狂扩建书架,以为书架越多,能装的知识就越多,回答就越准确。但Grok 4.3选择了另一条路:不扩建书架,而是把藏书更新到2026年初的最新版本,同时给图书馆换了一套更高效的检索系统。
这套检索系统就是它的「始终开启」链式推理机制——相当于让模型每次回答前,都像个研究员一样先列提纲、找依据,而不是凭直觉直接给答案。比如处理一份财务报表,它会先拆解「营收结构」「成本占比」「利润趋势」几个问题,逐个找数据验证,最后再整合结论。这种方法让它在法律推理、金融分析这类真实工作任务中的得分暴涨321分,直接超过了谷歌和Meta的同级别模型。
还有个关键的小设计:Prompt缓存。如果你问过相似的问题,模型会直接调用之前的思考框架,不用重新从零开始检索,这一下就把重复请求的成本降到了原来的1/10。相当于图书馆给常来的读者准备了专属阅览区,不用每次都重新查目录。
评测机构说Grok 4.3「稳坐在智能与成本的帕累托前沿」,这个听起来像经济学名词的概念,其实就是AI行业的「性价比天花板」。简单说就是:在当前的技术条件下,你找不到另一个模型,能比它更聪明的同时还更便宜,或者比它更便宜的同时还更聪明。
我们可以用一组数字来直观感受:跑完全套10项行业智能测试,Grok 4.3只花了395美元,而顶尖的Claude Opus 4.7要花4811美元——差了12倍。但Grok 4.3的智能评分,只比后者低了不到10分。如果把智能和成本做成一张坐标轴,Grok 4.3就站在那条向上倾斜的临界线上:再往左挪一点(更便宜),智能就会掉下来;再往上挪一点(更聪明),成本就会暴涨。
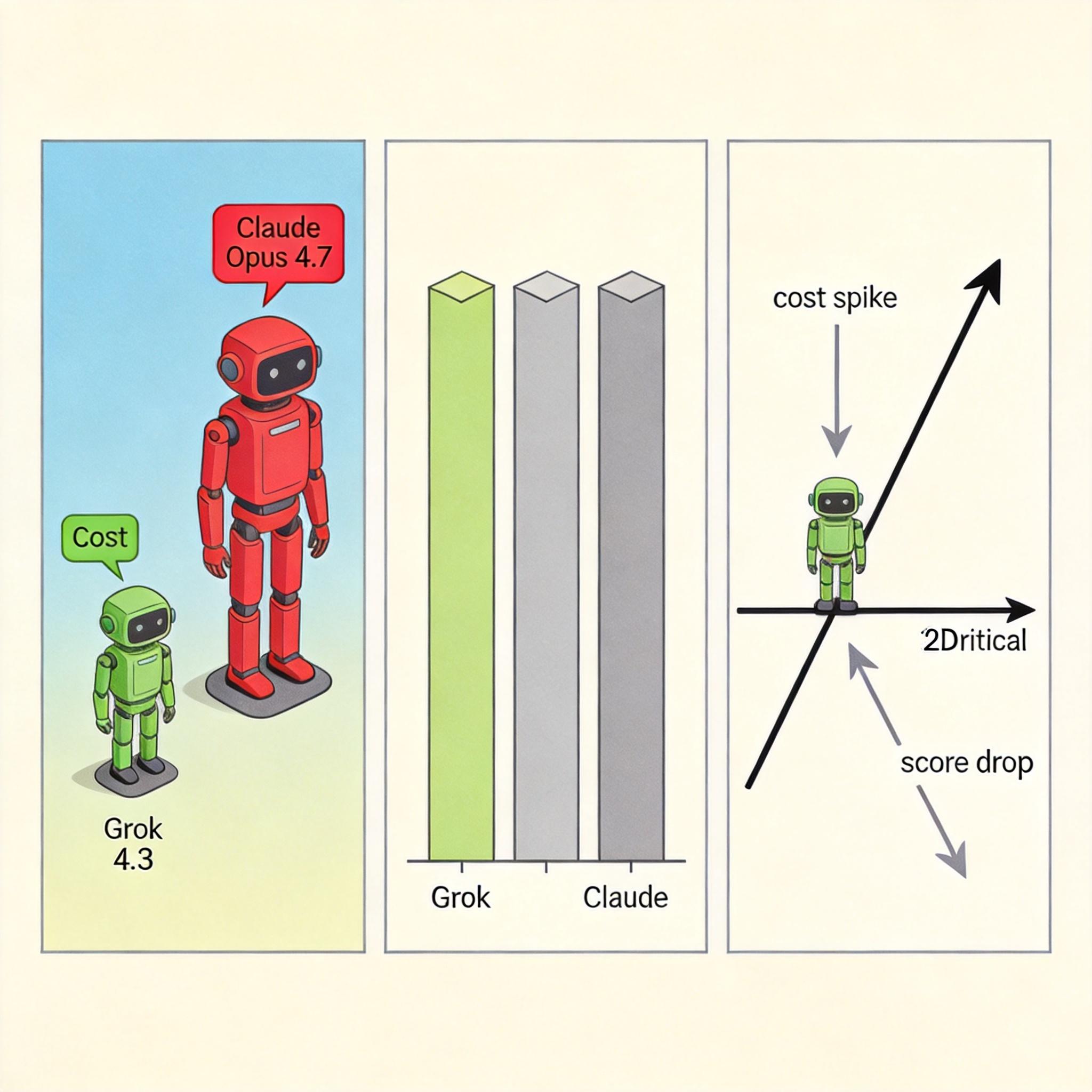
这其实戳破了AI行业的一个误区:不是参数越大,性价比就越高。之前有机构研究过,模型参数和训练数据之间存在一个非线性的平衡点——当参数达到一定规模后,再增加参数,能换来的智能提升会越来越少,而成本却会指数级上升。Grok 4.3就是踩中了这个平衡点:用5000亿参数的规模,配上最新的训练数据和高效的推理机制,把每一分算力都花在了能提升真实工作能力的地方。
当然,Grok 4.3不是完美的。它在物理推理测试里只拿了8分,写终端命令、调试代码的能力也明显掉队——这些需要精确逻辑计算的任务,还是参数更大的模型更擅长。更有意思的是,它超强的指令跟随能力,反而成了一把双刃剑:它能精准执行你说的每一个任务,但如果是恶意指令,它的服从度也更高,这给内容安全带来了不小的挑战。
还有那个「始终开启」的推理机制,虽然提升了准确性,但也带来了新问题:有时候模型会陷入「过度思考」,在一些简单任务上反而变慢,甚至出现用户说的「嗜睡症」——在连续推理过程中突然变慢或中断。这就像一个研究员,不管你问的是「今天天气怎么样」还是「分析一份年度报告」,都要先列个详细提纲,反而浪费了时间。
更现实的是,它的高性价比,目前只针对特定用户群体。要用到完整的功能,你得花300美元订阅SuperGrok Heavy会员,这把很多普通用户挡在了门外。而对于企业用户来说,它的稳定性、合规性还有待验证——毕竟,真实的商业场景里,比智能和成本更重要的是可靠。
Grok 4.3的出现,更像是AI行业的一个「提醒」:当所有人都在往同一个方向狂奔时,停下来看看脚下的路,或许能找到另一条更高效的赛道。
过去几年,我们见证了AI模型从百亿参数到万亿参数的狂奔,仿佛参数数字就是智能的代名词。但Grok 4.3告诉我们,智能的提升,从来不是只有堆参数这一条路。工程优化、推理机制创新、训练数据的精准投喂,这些看不见的细节,同样能让模型变得更聪明、更便宜。
智能的终极形态,从来不是越大越好,而是刚刚好。 未来的AI战场,或许不再是比谁的参数更大,而是比谁能在智能与成本之间,找到那个最精准的平衡点——毕竟,能真正走进千家万户、融入各行各业的AI,一定是既聪明又实惠的。