对抗知识焦虑,从看懂这条开始
App 下载
国产GPU软件破壁:93% CUDA代码无缝迁移,意味什么?
软件兼容性|算力生态|CUDA代码迁移|国产GPU|沐曦股份|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载软件兼容性|算力生态|CUDA代码迁移|国产GPU|沐曦股份|AI产业应用|人工智能
在人工智能(AI)的浪潮之巅,算力是驱动一切创新的引擎。然而,对于中国的AI开发者而言,一座名为CUDA的“隐形长城”长期横亘在面前。英伟达凭借其GPU硬件与CUDA软件生态的深度绑定,构建了一个强大但封闭的帝国。开发者们早已习惯在这个生态中工作,无数算法、模型和应用都构建于其上。因此,即便国产GPU在硬件性能上奋起直追,开发者们依旧望而却步——迁移到新的硬件平台,意味着高昂的代码重写、学习和调试成本,这道无形的软件壁垒,一度成为阻碍国产AI产业自主落地的最大瓶颈。
近日,刚刚完成IPO的国产GPU公司沐曦股份,发布了一则看似常规的技术更新,却可能成为撬动这座“长城”的关键支点。其全新的MXMACA软件栈3.3.0.X版本正式发布,其核心目标只有一个:让国产GPU真正“用起来”。这不仅是一次版本迭代,更像是一把递到所有开发者手中的“万能钥匙”,旨在以最低成本解锁被CUDA生态禁锢的庞大软件资产。
这份自信源于惊人的实测数据。沐曦团队选取了全球最大的代码托管平台GitHub上4490个含有“CUDA”关键字的活跃代码仓库进行验证,这些项目覆盖AI模型、高性能计算、气象模拟、计算化学等多个前沿领域。测试结果显示,高达92.94%(即4173个)的项目,无需修改任何核心代码,可以直接在沐曦的GPU平台上成功运行。其余不到6%的项目也仅需微小的编译配置调整。这意味着,全球开发者积累的海量CUDA项目,几乎可以“开箱即用”地迁移到国产算力底座之上。

如果仅仅是做一个兼容层,MACA的故事还不够完整。其真正的突破在于,它并非简单的“翻译官”,而是一套从底层硬件到上层应用的全栈自研软件体系。沐曦选择了最具挑战但也最能保证长期自主权的路线:基于全自研的GPGPU核心IP和自主指令集。
在这种“高门槛自研”的基础上,MACA通过构建高度兼容的软件栈,实现了“低成本迁移”的用户体验。它内置了完整的自研工具链,为开发者提供了一站式解决方案:
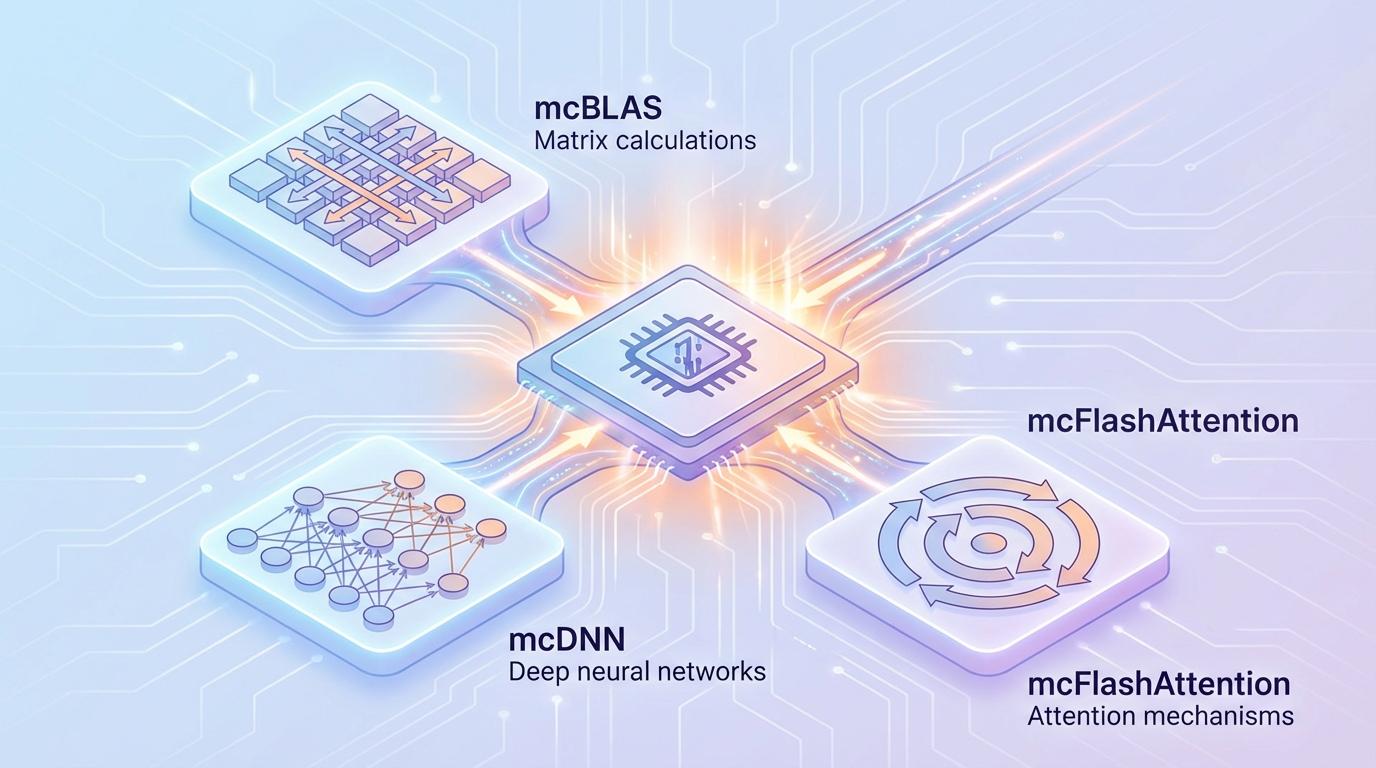
MACA的战略价值,最终体现在它如何将原始算力高效转化为生产力。新版本软件栈构建了一套覆盖大模型“训练-微调-推理-部署”的全流程一体化算力底座,彻底打破了训练与推理之间的场景壁垒。
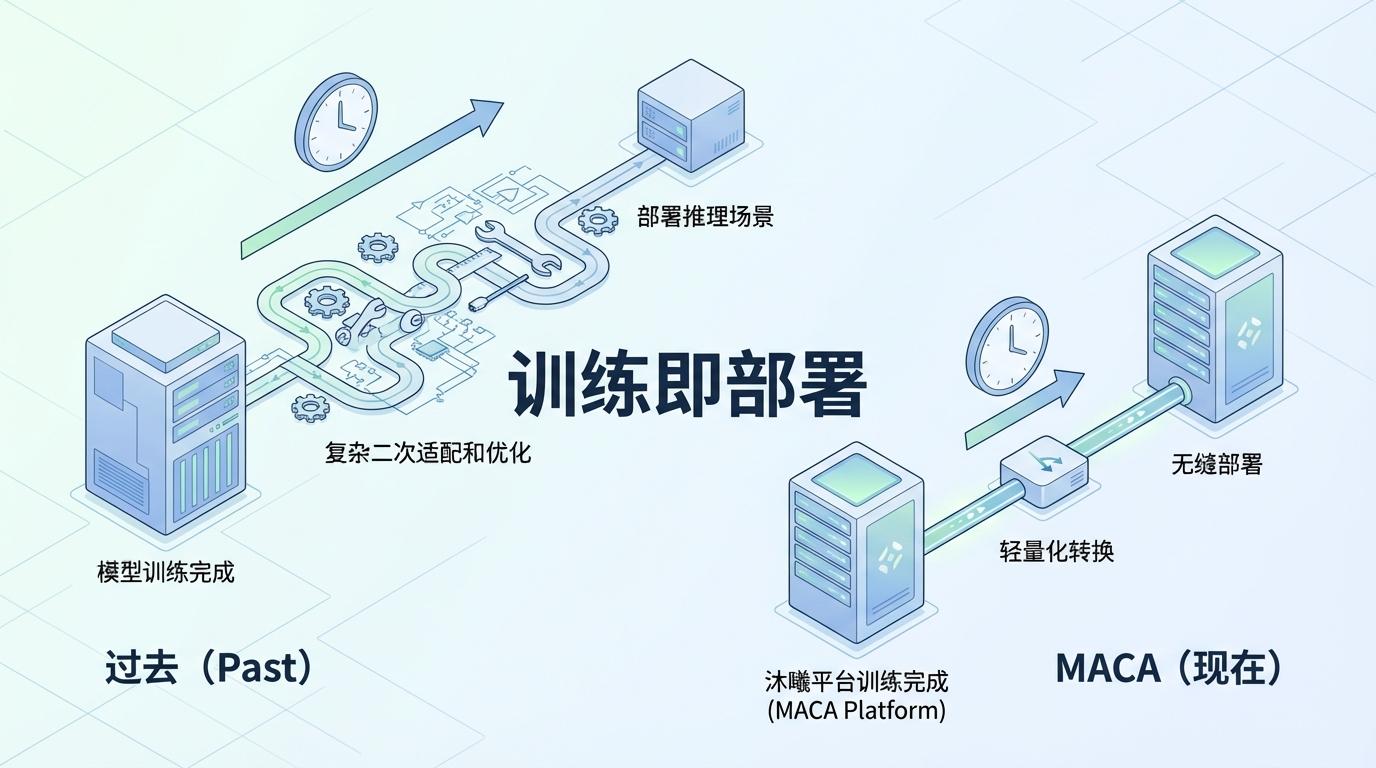
过去,一个模型在训练完成后,往往需要复杂的二次适配和优化才能部署到推理场景。而MACA通过统一的模型格式与接口规范,实现了**“训练即部署”**。这意味着,在沐曦平台上训练完成的模型,可以轻量化转换后直接无缝部署,极大地缩短了AI技术从研发到业务落地的周期与成本。
为了实现这一目标,MACA在技术层面进行了深度优化:
MACA 3.3.0.X的发布,不仅是沐曦一家公司的技术突破,更是国产GPU产业发展思路的一次关键跃迁。它标志着国产厂商在经历了硬件性能的“破冰期”后,正集体转向通过软件定义算力、通过标准重塑生态的“深水区”。
这种“高门槛自研、低成本迁移”的模式,在确保核心技术自主可控的战略前提下,最大限度地降低了用户的切换成本和风险,让海量的开发者和已有的软件资产能够平滑地流入国产算力生态的轨道。这不再是一场零和博弈,而是通过搭建桥梁,将全球的创新成果引入自主的算力底座之上。随着技术的不断演进,国产GPU正在用一种更聪明、更务实的方式,打破算力壁垒,为中国AI产业的全面自主化铺设一条坚实而宽广的道路。