对抗知识焦虑,从看懂这条开始
App 下载
北大团队用芯粒+光互连,把大模型训练提速20倍
大模型训练|光互连|芯粒技术|ChipLight框架|北京大学团队|先进材料|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载大模型训练|光互连|芯粒技术|ChipLight框架|北京大学团队|先进材料|AI算力|前沿科技|人工智能
当你用AI写文案、做代码调试时,可能不会想到:训练一个万亿参数的大模型,成千上万的GPU里,超过一半时间都在“干等”——等隔壁GPU把数据传过来。这不是算力不够,是通信成了“肠梗阻”:传统GPU集群里,节点内部是双向八车道,跨节点却瞬间变乡间小路,数据堵得水泄不通。
直到北京大学的团队拿出了一套“通肠术”:他们把芯粒和光互连这两项前沿技术拧成一股绳,用一套叫ChipLight的跨层优化框架,居然把大模型训练吞吐量提了近20倍。这不是简单的硬件堆叠,而是从底层重构了AI训练的“交通系统”。
要理解ChipLight的突破,得先搞懂芯粒是什么。传统芯片是“一块巨石”——把所有计算、存储、通信功能塞进一颗大硅片里,不仅制造难度大、良率低,还容易因某一个小瑕疵整块报废。芯粒技术则像搭乐高:把大芯片拆成一个个功能独立的“小积木”,比如专门负责计算的逻辑芯粒、管存储的内存芯粒、处理通信的I/O芯粒,再用先进封装技术把它们粘在同一个基板上,形成一个多芯片模块(MCM)。
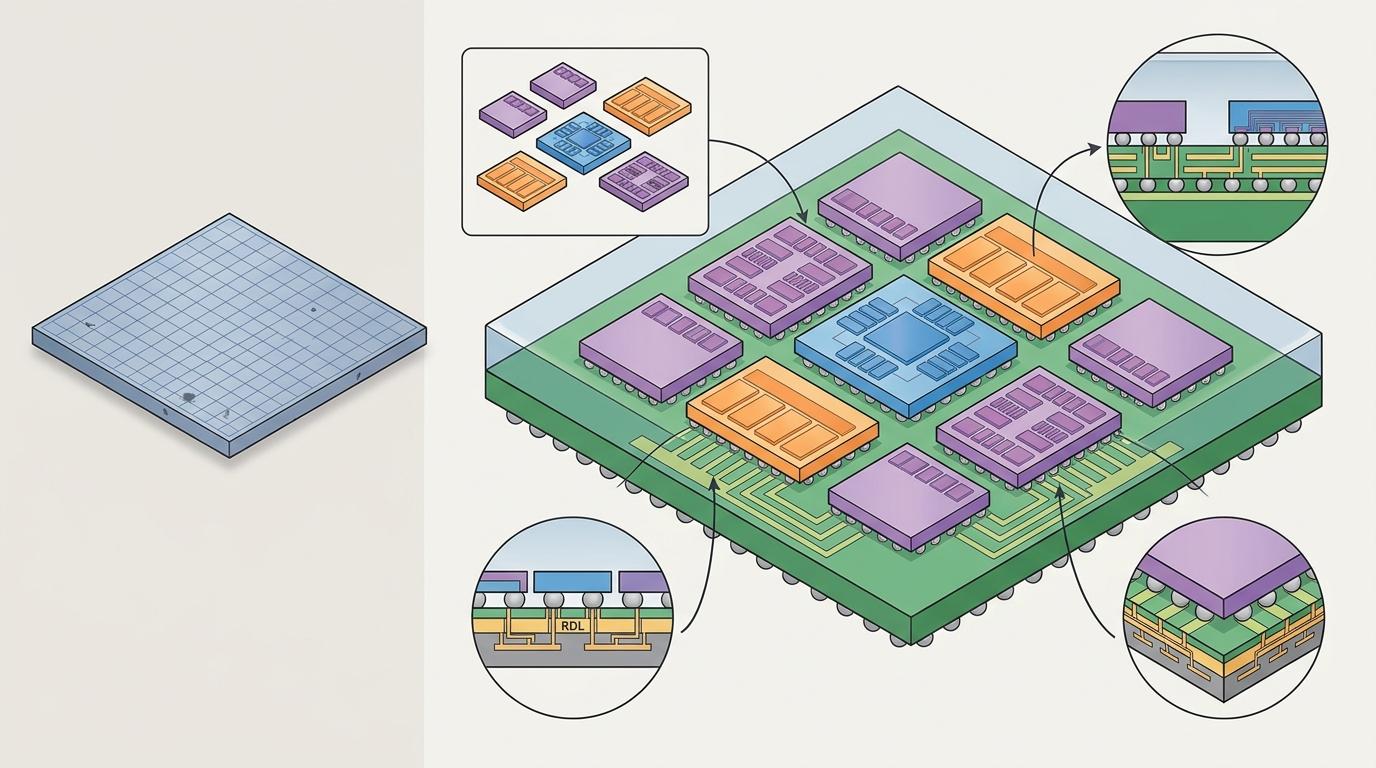
这种“化整为零”的思路好处太多:小芯片制造良率高,成本能降40%;还能混合搭配不同工艺的芯粒——比如用7nm做计算芯粒,用更成熟的14nm做存储芯粒,在性能和成本间找到最优解。更关键的是,芯粒之间的通信带宽能达到数百GB/s/mm,是传统单芯片内部互连的好几倍,相当于把节点内部的“高速路”修到了每个芯片角落。
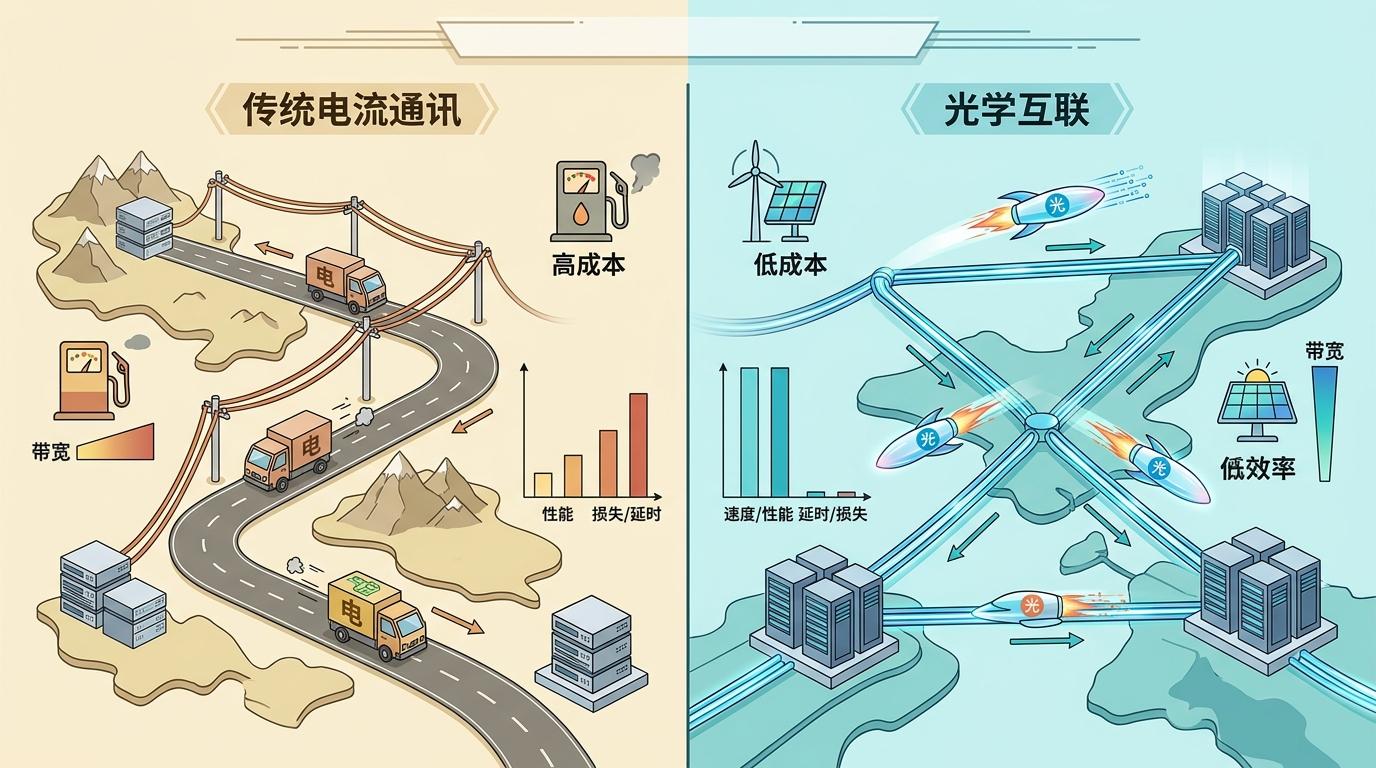
但芯粒只是解决了“节点内部”的拥堵,跨节点的“乡间小路”问题还没解决——这就得靠光互连了。
传统跨节点通信靠电信号,就像用快递车拉货:速度慢、损耗大,拉得越远成本越高。光互连则是用光纤传数据,相当于给数据开了“飞机”——带宽是电互连的10倍以上,延迟却只有几分之一,还几乎不受距离影响。
ChipLight用的是更先进的“共封装光学(CPO)”:把光模块直接焊在芯片封装边缘,电信号不用再走长长的铜线,刚出芯片就变成光信号,损耗直接降了90%,带宽密度能达到128GB/s/mm。再搭配光电路交换机(OCS),就像给数据建了个“空中调度中心”——能在毫秒级内切换光路,让不同的训练任务共享同一根光纤,把链路利用率提了30%。
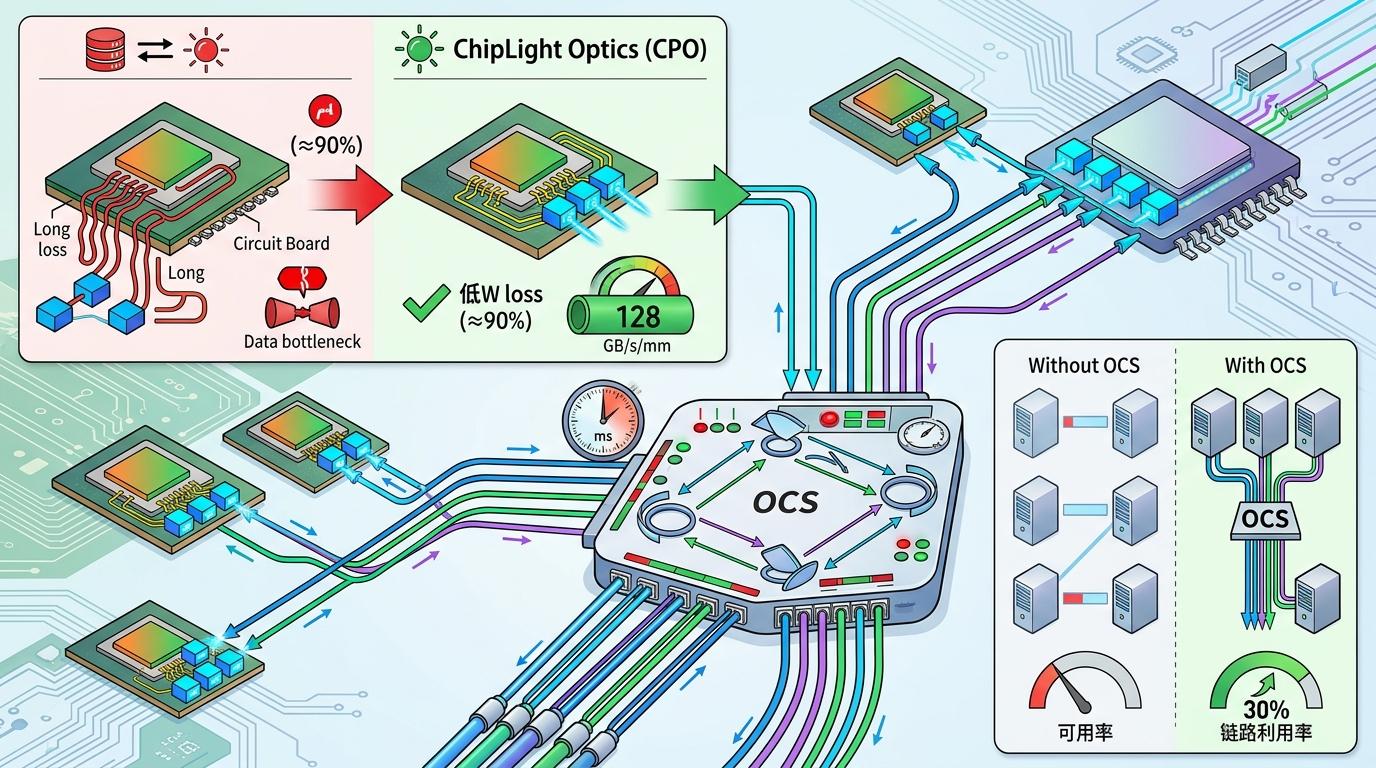
但ChipLight的厉害之处,不止是把两个好技术凑在一起,而是搞懂了大模型训练的“交通规律”:大模型训练时,不同并行策略的通信高峰是错开的——比如上下文并行的通信在注意力层,专家并行的通信在FFN层,两者根本不会同时堵车。他们就利用这个特点,让同一根光纤在不同时间干不同的活,相当于把一条路早上给公交车用,晚上给货车用,彻底把资源用满了。
过去做AI集群设计,是“各自为政”:芯片厂商只管做芯片,网络厂商只管做网络,算法工程师只管调并行策略,最后凑在一起,难免出现“鞋不合脚”的问题——比如芯片的通信带宽和网络的带宽不匹配,或者并行策略的通信模式和网络拓扑不兼容。
ChipLight则是“全局一盘棋”:它把芯粒规模、内存配置、光链路数量、网络拓扑和并行策略都放进一个优化框架里,用嵌套搜索的方法找最优解。外层先找最合适的MCM架构——比如用多少个芯粒、配多少内存;内层再根据训练任务的通信模式,把流量智能分配到芯粒内部的高速网或者跨节点的光网,甚至能动态调整并行策略,让硬件和算法完美适配。
实验结果说话:用Qwen3-235B模型测试,ChipLight集群比传统H100集群的训练吞吐量高了19.58倍;和同样用芯粒+光互连的RailX方案比,在相同成本下吞吐量还高了41%。更重要的是,他们还得出了6个关键洞察——比如小规模MCM加光互连,性能能媲美大规模MCM,但成本能降23%;逻辑芯粒配的HBM内存,得比传统GPU多一倍以上才够用。这些洞察直接给未来AI超算的设计指明了方向。
ChipLight的意义,不止是把大模型训练提速了20倍,更是给AI基础设施的未来画了一张清晰的路线图:当单芯片的性能摸到天花板时,芯粒+光互连的组合,就是突破通信瓶颈的最优解。
当然,这条路也不是一帆风顺:芯粒封装的翘曲问题、光互连的成本问题、软硬件协同的复杂度问题,都是摆在眼前的坎。但至少我们已经看到了方向——不是靠堆更多的GPU,而是靠重构底层的“交通系统”,让每一分算力都用在刀刃上。
算力的未来,不在单块芯片里,在芯片的连接里。