对抗知识焦虑,从看懂这条开始
App 下载
不用文本提示,AI也能生成高清多样图像
扩散模型|无文本提示生成|vivo研究团队|上海交大|自交换引导技术|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载扩散模型|无文本提示生成|vivo研究团队|上海交大|自交换引导技术|多模态视觉|人工智能
当你输入“一只戴着草帽的猫坐在海边”,AI能生成逼真画面——这早已不是新鲜事。但如果完全不给任何文字提示,只让AI“自由发挥”,过去的结果往往是模糊的色块、重复的纹理,或是逻辑混乱的拼接。现在,上海交大与vivo的研究团队打破了这个僵局:他们提出的自交换引导(SSG)技术,能让无文本提示的AI生成图像,在真实感和多样性上直接追平甚至超越有文本引导的水平。这背后,是一次对AI生成逻辑的底层重构——不用外部指令,而是让AI自己“折腾”自己的内部信号。
要理解SSG的突破,得先搞懂AI生成图像的核心逻辑。现在主流的扩散模型,是靠“逐步去噪”生成图像:从一团随机噪声开始,每一步去掉一点噪声,慢慢还原出清晰画面。为了让生成结果更贴合需求,过去最常用的是分类器无关引导(CFG)——简单说就是“用文本指令拉拽AI的生成方向”:把AI根据文本生成的结果,和它随便生成的结果做对比,然后沿着“更像文本描述”的方向推得更远。
但CFG有个致命缺陷:必须有文本指令。一旦没有提示词,它就成了无本之木。过去的研究者试过给AI“添乱”来引导无文本生成——比如在输入里加全局噪声,或者打乱注意力图,但这种粗暴的方法要么破坏了整体结构,要么让图像变得过度平滑,细节尽失。
SSG换了个思路:不在AI的“输入端”捣乱,而是在它的“思考过程”里动手脚。你可以把AI生成图像时的内部信号想象成一堆拼图块——每一块代表图像的一个局部特征。SSG做的,就是在这些拼图块里,挑出那些最不搭的几块交换位置:比如把猫耳朵的特征和草地的特征交换,把海浪的纹理和天空的纹理交换。
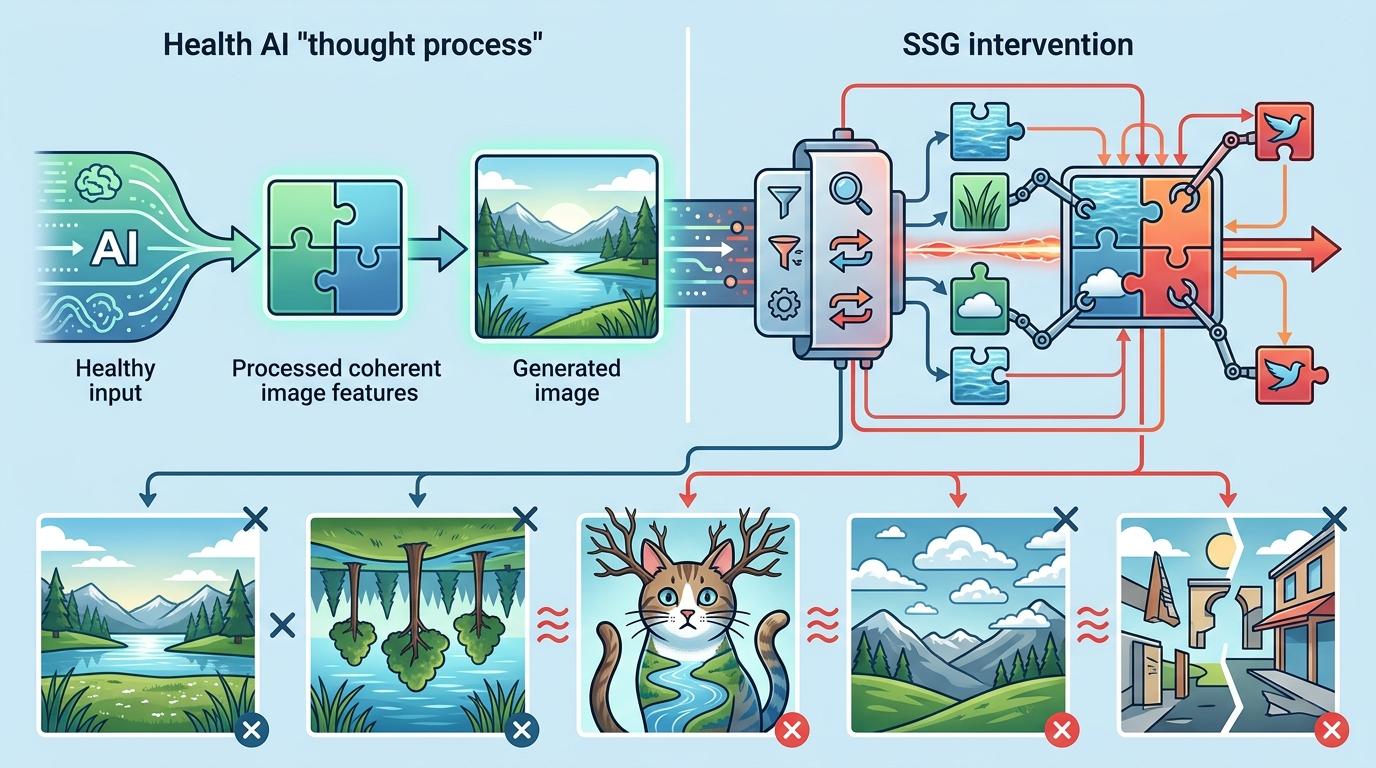
这种交换不是乱换的。SSG会先计算每块拼图(也就是AI里的token特征)之间的语义相似度,专门挑那些差异最大的配对交换——就像在一堆食材里,故意把辣椒和冰淇淋放在一起。这种精准的“捣乱”,会让AI的“思考”产生冲突:它原本以为这里该是猫耳朵,结果拿到的是草地的特征,于是会更努力地去修正这个矛盾,最终生成的细节反而更清晰。
更聪明的是,SSG会在两个维度同时动手:空间维度交换不同位置的特征,负责调整图像的结构和布局;通道维度交换特征的内部属性,负责优化纹理和材质。两者结合,就像给AI同时施加了“结构校正”和“细节打磨”两个buff。
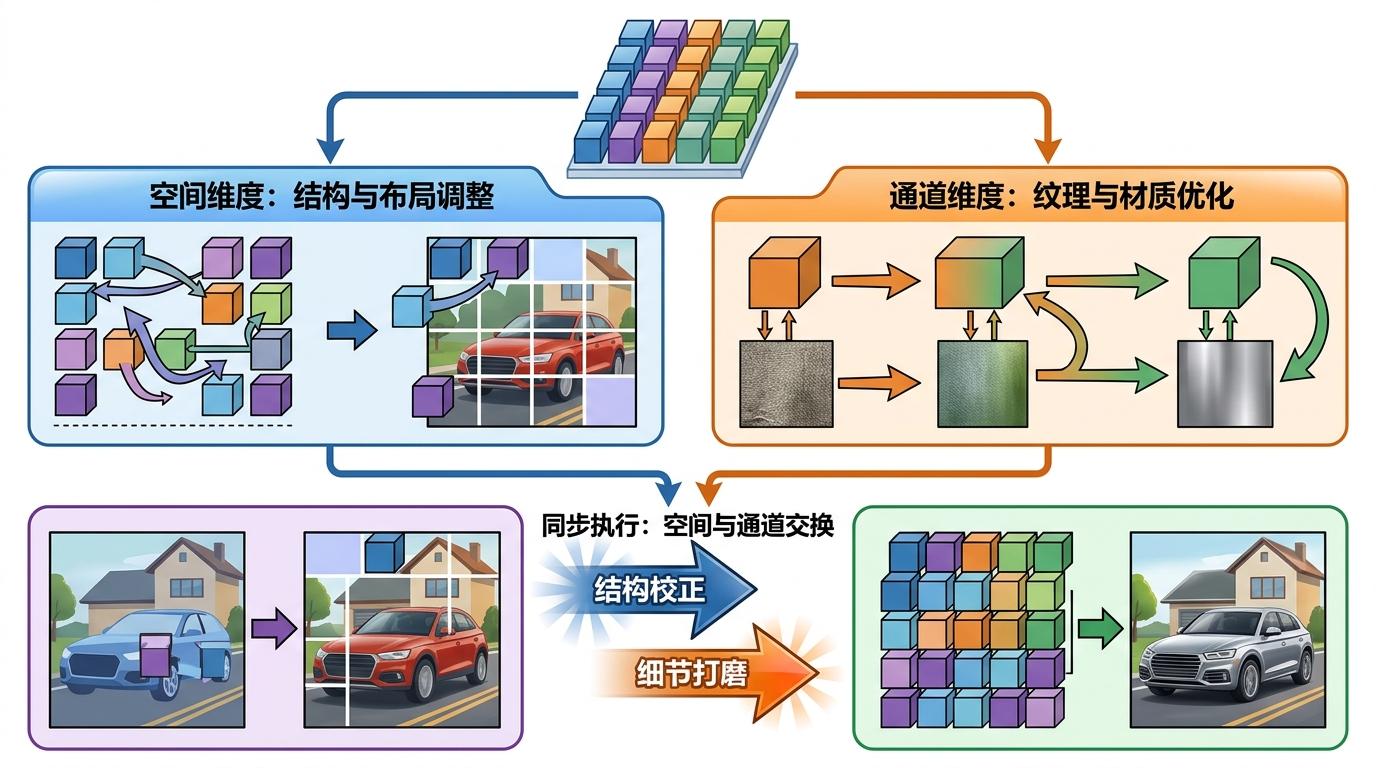
最关键的是,整个过程完全不需要额外训练,就像一个即插即用的插件——只要把它接到现有的扩散模型上,不管是Stable Diffusion v1.5还是SDXL,不管是生成风景还是人像,都能立刻生效。实验数据最能说明问题:在MS-COCO数据集上,SSG让无文本生成的FID(衡量真实度的指标)从119.04降到70.91,IS(衡量多样性的指标)从9.08升到16.44——这意味着生成的图像不仅更像真实照片,内容也不再千篇一律。
SSG的厉害之处,还在于它能和传统的CFG兼容。当你有文本提示词时,SSG可以在CFG的基础上进一步优化:CFG负责让图像贴合文本,SSG负责打磨细节和提升多样性。比如输入“一只戴着草帽的猫坐在海边”,CFG能保证生成的是猫、草帽和海,而SSG能让猫的毛发更蓬松,草帽的编织纹理更清晰,海边的浪花更有层次。
当然,它也不是完美的。目前SSG在处理极端复杂的场景时,比如包含十几个对象的拥挤画面,偶尔还是会出现局部逻辑混乱的问题。而且它的计算开销虽然不大,但比纯CFG还是多了约一倍的前向推理时间——不过对于大多数应用场景来说,这点代价完全值得。
更重要的是,SSG为AI生成打开了新的可能性:过去我们总觉得AI生成必须有“指令”,要么是文本,要么是参考图,但SSG证明,AI可以通过“自我调节”来生成高质量内容。这就像从“必须按剧本演戏”,变成了“给个主题就能即兴发挥”——AI的创造力,终于不再完全依赖人类的指令。
当我们谈论AI生成时,总在追求“更精准的指令”“更逼真的结果”,但SSG的出现提醒我们:有时候,给AI一点“自我折腾”的空间,反而能得到更惊喜的结果。它让AI从“执行指令的工具”,向“有自主创作潜力的伙伴”又靠近了一步。
最好的引导,是让AI自己引导自己。 未来的AI生成,或许不再是人类提要求、AI来完成,而是人类和AI一起,在探索可能性的过程中创造新的内容。而SSG,就是这个方向上的一块重要路标。