对抗知识焦虑,从看懂这条开始
App 下载
告别六指怪手,AI学会边画边思考意味着什么?
美团|香港中文大学|细节错误|逻辑推理能力|AI画作|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载美团|香港中文大学|细节错误|逻辑推理能力|AI画作|多模态视觉|人工智能
你一定见过那些令人啼笑皆非的AI画作:本该是五个手指的手掌,却凭空多出一根;温馨的窗边小猫,身体却诡异地悬浮在窗外;要求画三个苹果,AI却慷慨地赠送了第四个。这些作品在细节上无比逼真,但在基础的逻辑、空间和数量关系上却错漏百出。这仿佛是AI的幽灵BUG,一个缺乏常识的“数字画家”,它能模仿世间万物的纹理,却无法理解它们之间最简单的联系。长期以来,这种“有佳句无佳章”的窘境,成为衡量AI视觉生成能否从“学徒”走向“大师”的关键瓶颈。
就在2025年12月22日,一篇来自香港中文大学、美团等机构研究团队的论文,为解决这一难题提出了一个颠覆性的新范式——Thinking-while-Generating(TwiG)。这不再是让AI在下笔前制定一份无法更改的死板蓝图,也不是在画错后进行昂贵的“返工”,而是首个让模型在创作过程中实现“边生成边思考”的框架。
想象一位人类画家,他不会一口气画完整幅作品。他会先勾勒背景,再画主体,期间不断审视、调整、思考下一步的布局。TwiG正是模仿了这一过程,它将原本“一气呵成”的黑盒生成,拆解为**“生成-思考-再生成”**的动态循环。模型在绘制过程中会多次“暂停”,插入一段被称为“思维链”的文本推理,用文字总结刚刚画了什么,并规划接下来要画的局部内容。
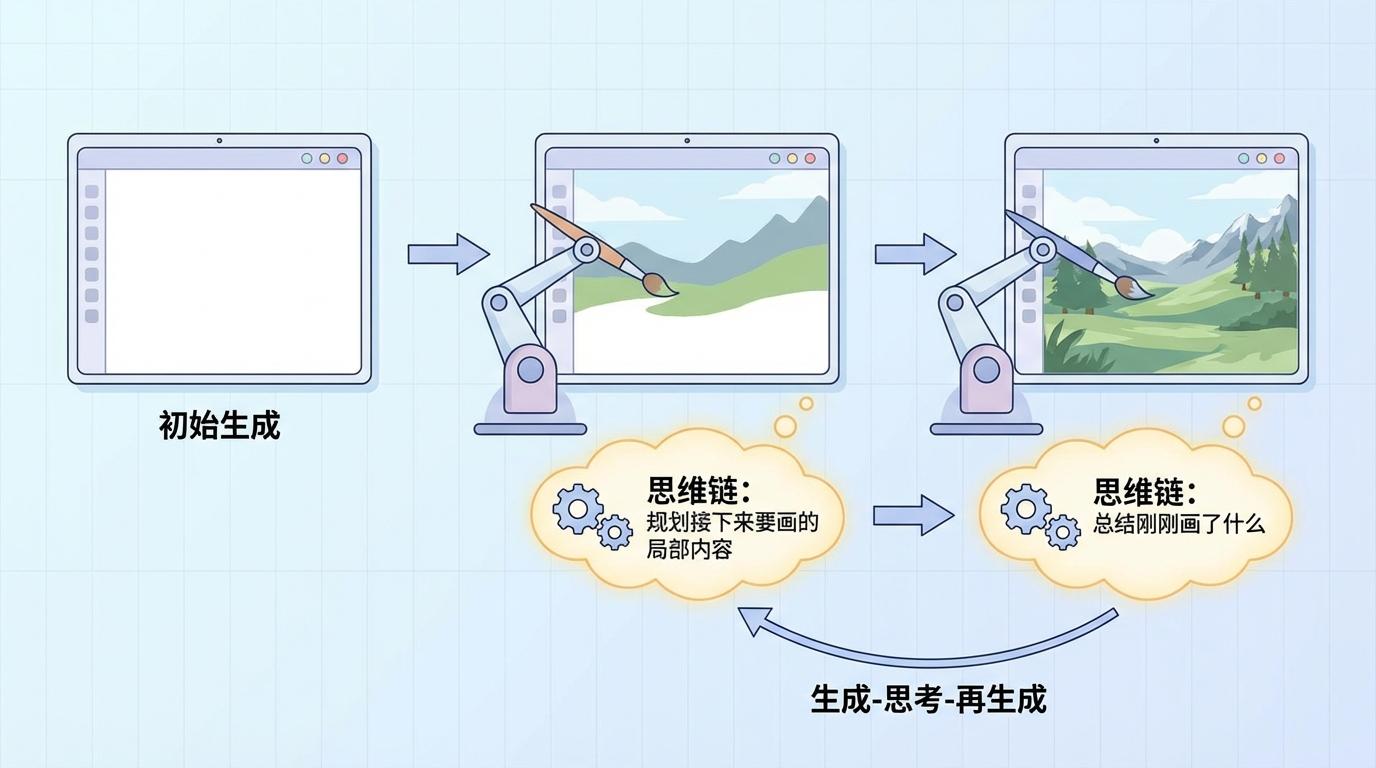
在TwiG出现之前,AI视觉生成主要有两条技术路线,但都治标不治本:
“谋定而后动” (Think-before-Generation):这种方法要求AI在生成图像前,先规划好详细的布局草图或计划。但这就像给画家一份精确到每一笔的指令集,一旦开始就无法更改,极度缺乏灵活性,无法应对复杂或动态的创作需求。
“亡羊补牢” (Think-after-Generation):即先生成一张完整的图片,然后通过多轮对话让AI进行修改。这种方式虽然能修正错误,但计算开销巨大,用户等待时间漫长,效率极低。
TwiG的出现,则标志着第三条道路的开启。它不再将思考与生成割裂,而是将二者深度交织,让AI拥有了在创作中动态调整和自我修正的能力,这无疑是向真正智能创作迈出的关键一步。
TwiG框架的精髓在于其对思考过程的精妙设计,主要分为三个维度:
何时思考 (When to Think):模型会根据用户指令,智能地规划出几个“思考节点”。研究发现,将生成过程分为三个阶段——上部背景、主体内容、下部背景——效果最佳,这恰好符合人类视觉感知的自然结构。
思考什么 (What to Say):在每个思考节点,模型会生成一段简短的文本“思维链”。这不仅是对已完成部分的回顾,更是对下一局部区域的微型“路书”,例如:“现在我要在画面的中央绘制一只金色的猫,它正坐在红色的垫子上。”这种细粒度的引导远比单一的提示词精准。
如何修正 (How to Refine):最关键的一步。在画完一个局部后,模型会立即进行“自我批判”。如果发现颜色不对或位置有误,它会触发局部“重画”机制,只修正有问题的区域,而无需推倒重来。这大大提升了效率和可控性。
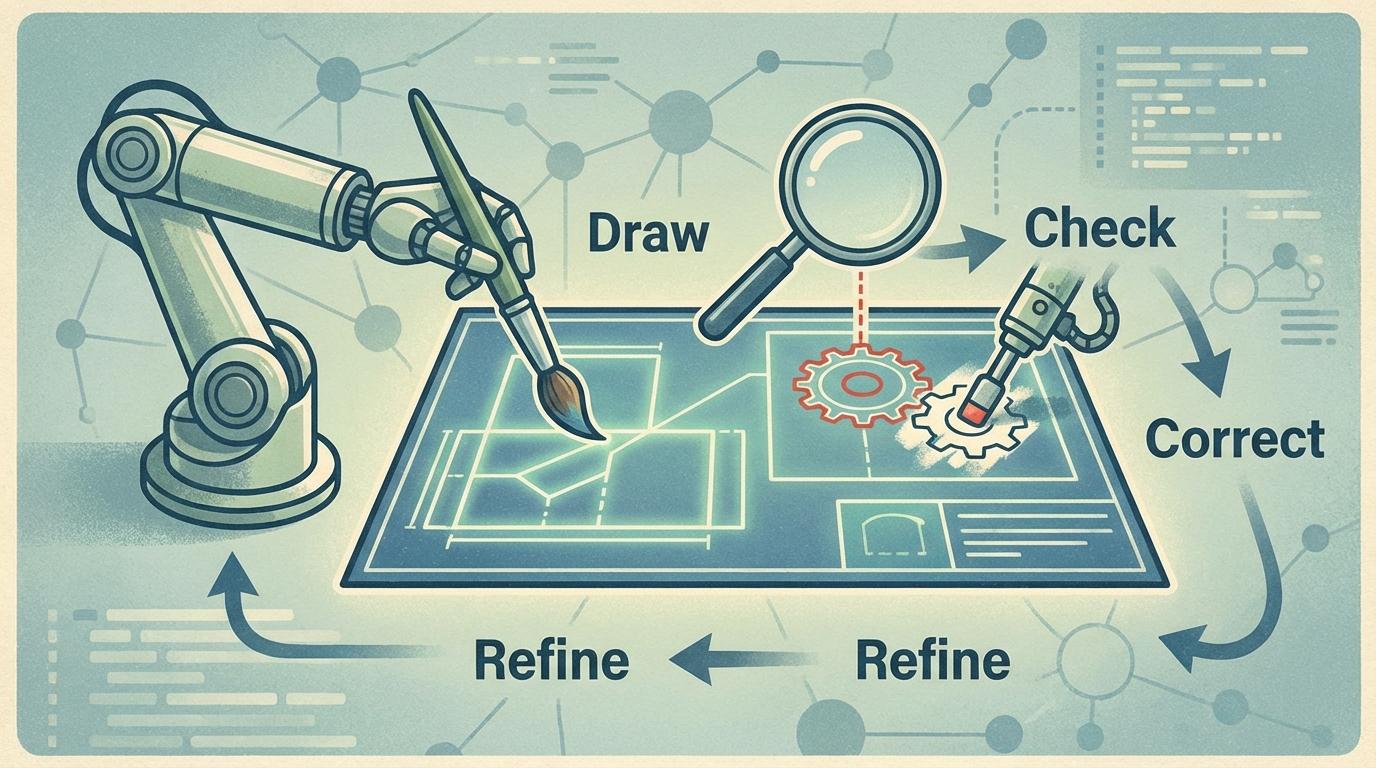
为了验证这一范式,研究团队通过零样本学习(Zero-Shot)、监督微调(SFT)乃至强化学习(RL)层层递进。结果惊人,尤其是在引入了针对TwiG优化的GRPO强化学习策略后,模型不仅学会了如何画得更好,更学会了如何更好地思考,在处理复杂空间关系和属性绑定等任务上,表现甚至超越了Emu3、FLUX.1等顶尖模型。
TwiG的提出,其意义远不止于技术优化,它更是一场观念上的革命。它试图用一束“逻辑之光”照亮视觉生成模型这个不透明的“黑盒”。
通过引入人类可读的文本推理过程,我们首次得以窥见AI“创作”时的内心活动。这使得整个生成过程变得透明、可控且富有逻辑性。研究团队的结论直指要害:
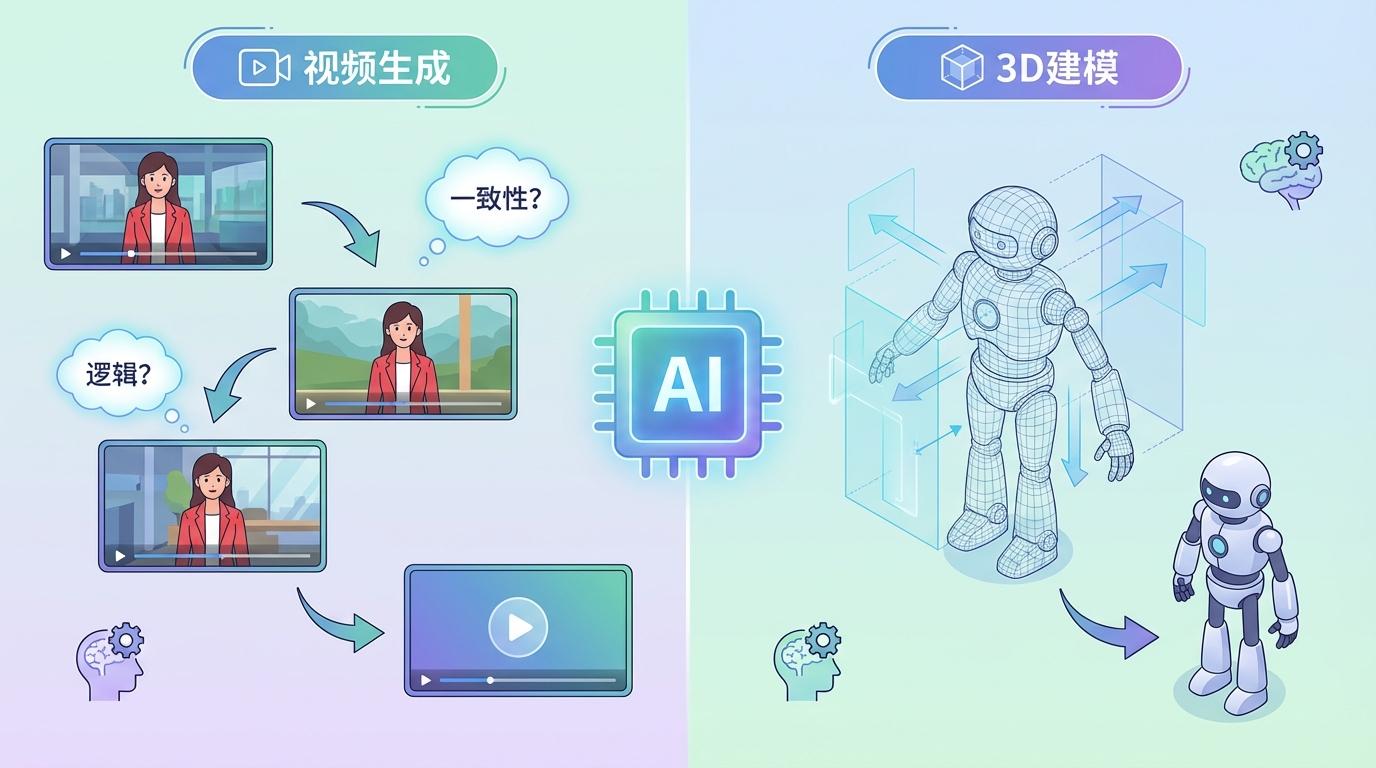
尽管目前的实验主要基于自回归模型,但TwiG框架的设计具有普适性,同样兼容扩散模型。这意味着,这种“边生成边思考”的范式未来可以被广泛应用。
想象一下,在视频生成领域,AI可以一边生成画面,一边思考“这个角色的衣服在上一帧是什么颜色?”“下一个镜头应该如何衔接才符合逻辑?”,从而解决长期困扰AI视频的角色一致性和情节连贯性问题。在3D建模中,AI可以在构建模型的过程中,实时推理各部件的空间关系,确保结构的合理性。
当然,TwiG仍有待完善之处,例如如何让模型自适应地决定思考的频率,以及如何降低强化学习高昂的训练成本。但它无疑为我们指明了一个通往真正通用视觉智能的方向:一个不再仅仅是模仿,而是能够理解、推理并创造的未来。