对抗知识焦虑,从看懂这条开始
App 下载
能读懂梗的AI,补全了多模态最后一块拼图
情绪识别|视觉语境|语义理解|表情包识别|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载情绪识别|视觉语境|语义理解|表情包识别|多模态视觉|人工智能
当你把一张猫脸皱成包子的表情包丢给AI,它不仅能说出“这只猫满脸不情愿”,还能懂你转发这张图的笑点——这不是科幻片里的场景,是国内团队刚灰度测试的识图能力。此前它的视觉能力还停留在识别文字阶段,如今终于能像人一样,把画面元素、文化语境和情绪揉在一起读进脑子里。
多模态AI的核心,是打破单一数据模态的墙。过去的视觉模型像只会认字的小学生,能把图片上的文字扒下来,却看不懂文字背后的画面;语言模型像看不见的博学家,能聊透历史哲学,却对一张截图束手无策。而这次的突破,相当于给博学家安上了一双能理解世界的眼睛——它能把二维图像转化为结构化的语义信息,再喂给原本就擅长推理的语言模型,实现“看见”与“理解”的无缝对接。
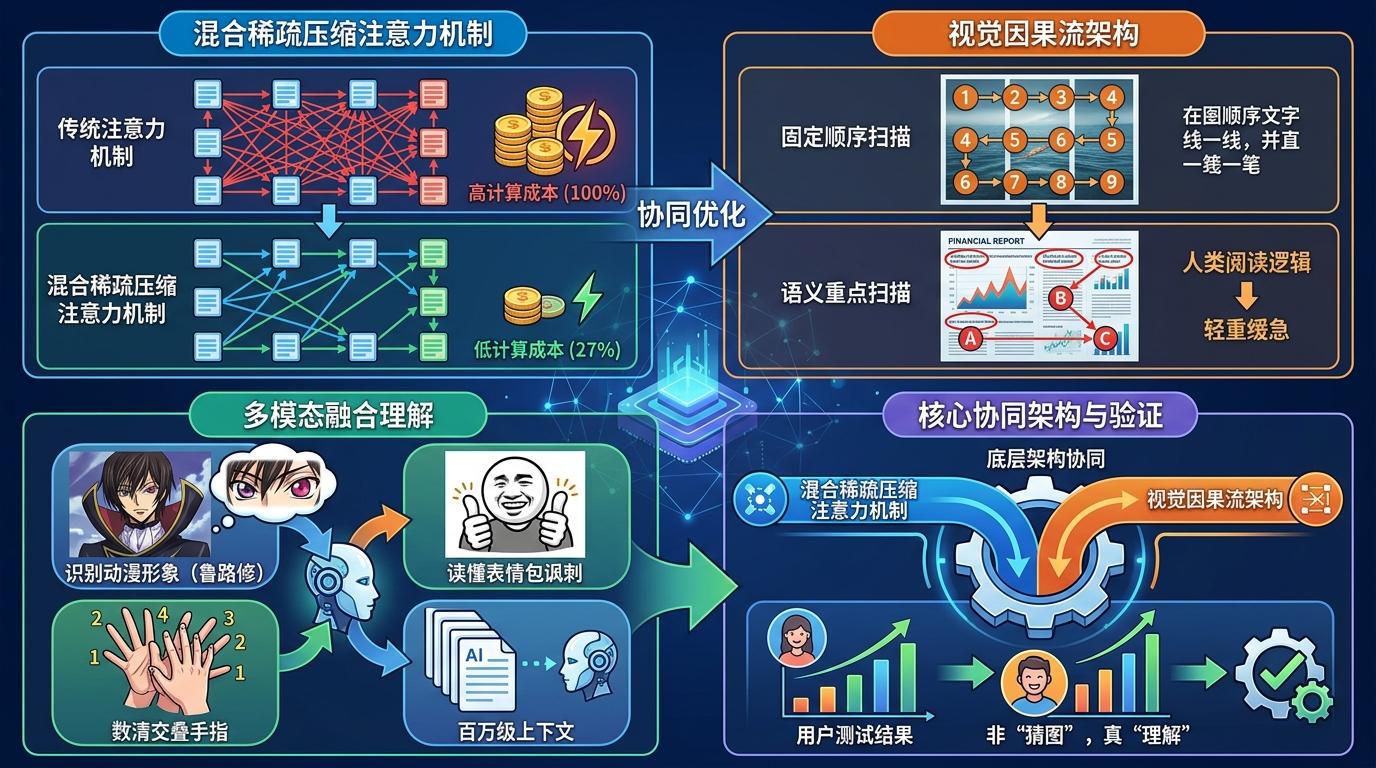
这种融合不是简单的拼接,而是底层架构的协同。团队采用的混合稀疏压缩注意力机制,让模型在处理百万级上下文时,计算成本仅为上一代的27%;视觉因果流架构则模拟人类的阅读逻辑,不再按固定顺序扫描图像,而是跟着语义重点走——比如看一份财报,它会先抓标题和数据,再扫附注,像人一样有轻重缓急。从用户测试的结果看,它能认出鲁路修的动漫形象,能读懂特朗普表情包的讽刺,甚至能数清图片里交叠的手指,这些都证明它不是在“猜图”,是真的在“理解”。
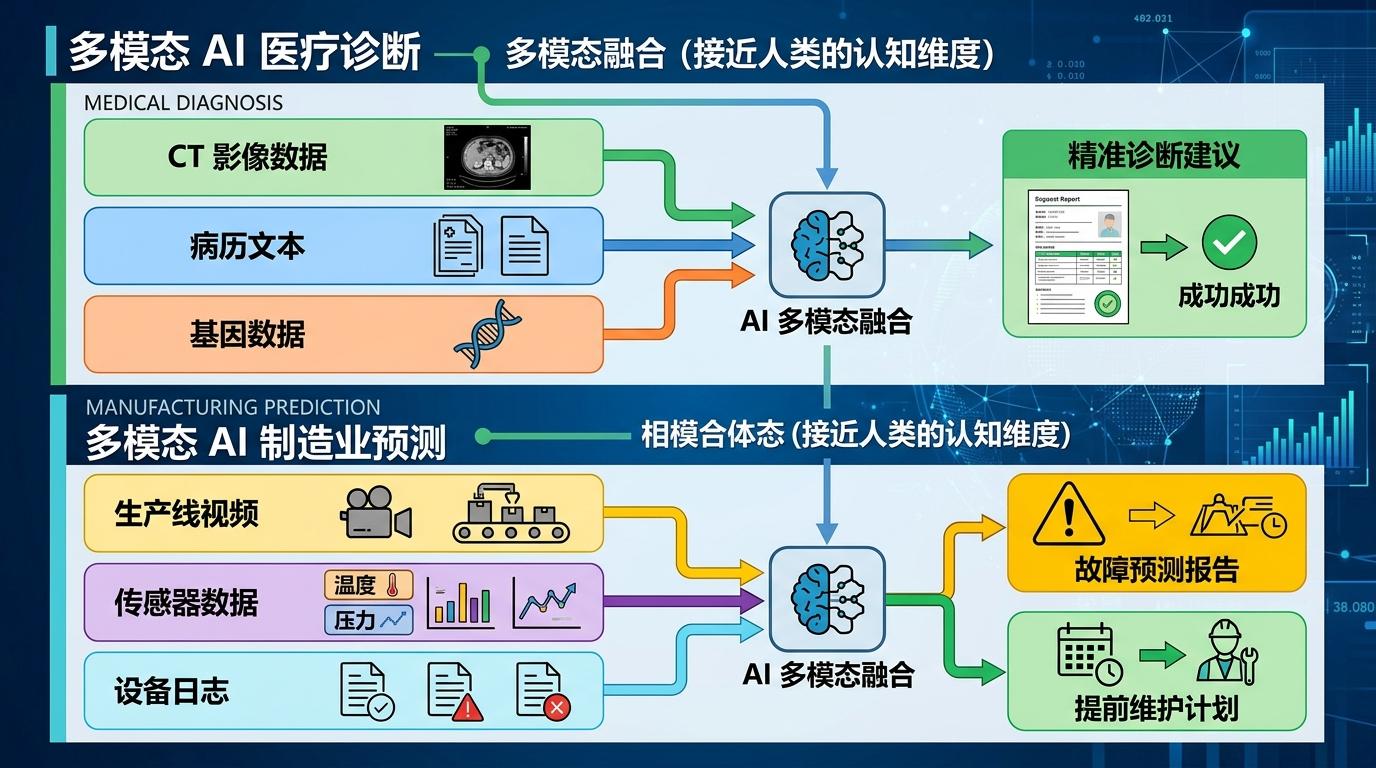
但它的天花板,远不止读懂表情包。在医疗领域,多模态AI能把CT影像、病历文本和基因数据捏合在一起,给出比单一模态更精准的诊断建议;在制造业,它能同时分析生产线的视频画面、传感器数据和设备日志,提前预判故障。这些场景里,单一模态的信息永远是片面的,只有多模态融合,才能让机器获得接近人类的认知维度。
当然,挑战也像影子一样跟着。面对低清模糊的图片、故意设计的视错觉,它的推理准确率会明显下降——就像人在光线昏暗时也会看错东西。更难的是文化语境的边界:一个只在某小众圈子流行的梗,它可能就摸不着头脑。而从技术落地到产业应用,还要跨过算力成本、数据隐私的坎——处理一张高清图片的计算量,抵得上处理几千个文字token,这对中小企业来说仍是不小的负担。
让机器“看懂”世界,从来不是为了让它变成另一个人,而是让它成为人类的延伸。当AI能接住你丢过去的表情包、读懂你截的复杂报表,它就不再是一个冰冷的工具,而是能和你用“日常语言”对话的伙伴。这不是终点,只是AI真正走进现实世界的开始。