
20 小时前
20 小时前
当你在看篮球赛直播时,镜头扫过拥挤的替补席,屏幕上的AI却把刚起身的12号认成了下场休息的7号;当监控镜头捕捉深夜街头的人群,突然被遮挡的路人在画面里“凭空消失”又“莫名出现”——这些让AI犯糊涂的场景,正是单目视频3D人体重建的现实困境。
直到2026年CVPR会议上,北京理工大学联合团队带来的RAM方法,把这些“断片”的动作轨迹重新接成了流畅的长线。它能在人群拥挤、频繁遮挡的真实场景里,死死盯住每个人的动作不跑偏,甚至在完全看不到人的时候,还能顺着动作趋势“猜”出接下来的姿态。为什么它能做到这些?答案藏在一套被重新设计的“时间逻辑”里。
过去的AI处理视频,就像拿着相机逐帧抓拍:每看完一张照片,就把之前的内容忘得差不多,只靠当下的画面判断“这是谁、在做什么”。这种“见眼下菜碟”的逻辑,遇上遮挡、快速运动就彻底失灵——当一个人被别人挡住半秒,AI再见到他时,可能已经认不出来了。
RAM的思路彻底变了:它给AI装了一本“动作日记”。
你可以把SegFollow模块想象成AI的“身份小本本”,里面记着每个人的运动惯性——就像你知道朋友走路习惯晃左肩,哪怕他戴了口罩,你也能从背影认出他。这个模块用卡尔曼滤波算法算出每个人的运动轨迹,把“下一秒大概会出现在哪”的惯性信息,和衣服、发型这些外观特征结合起来判断身份。就算有人被完全挡住2秒,AI也能凭着之前记的运动轨迹,等他再出现时立刻对上号。在PoseTrack21数据集的测试里,RAM的ID切换次数比传统方法少了近70%,相当于把认错人的概率降到了原来的三分之一。
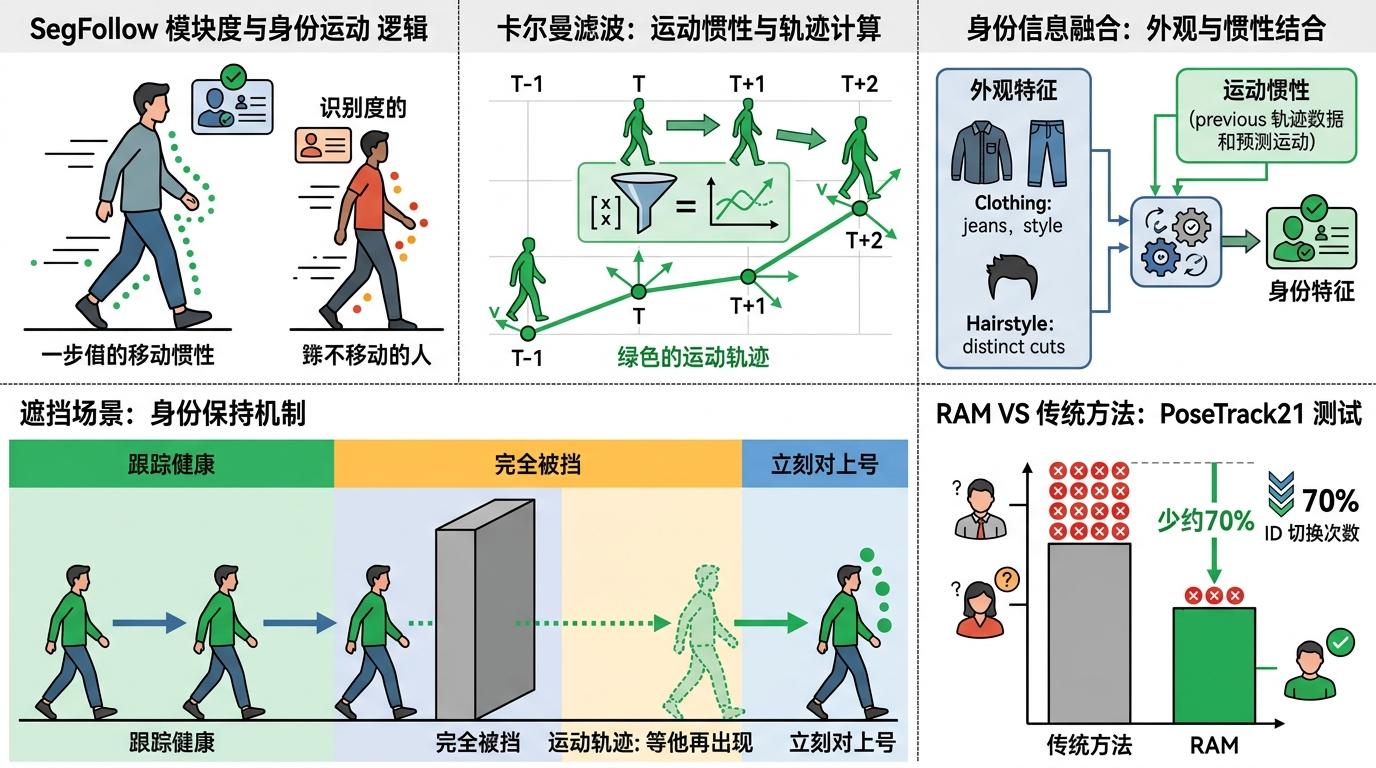
解决了“认人”的问题,接下来是“记动作”。当视频里的人被挡住半个身体,传统AI只能凭着露出来的半条胳膊瞎猜姿态,结果经常生成“胳膊长在肚子上”的怪异动作。RAM的T-HMR模块,就像给AI配了一套“动作拼图”:它会从之前几秒的视频里,把这个人完整的动作片段存成“记忆碎片”,当当前帧的信息残缺时,就用这些碎片拼出完整的姿态。
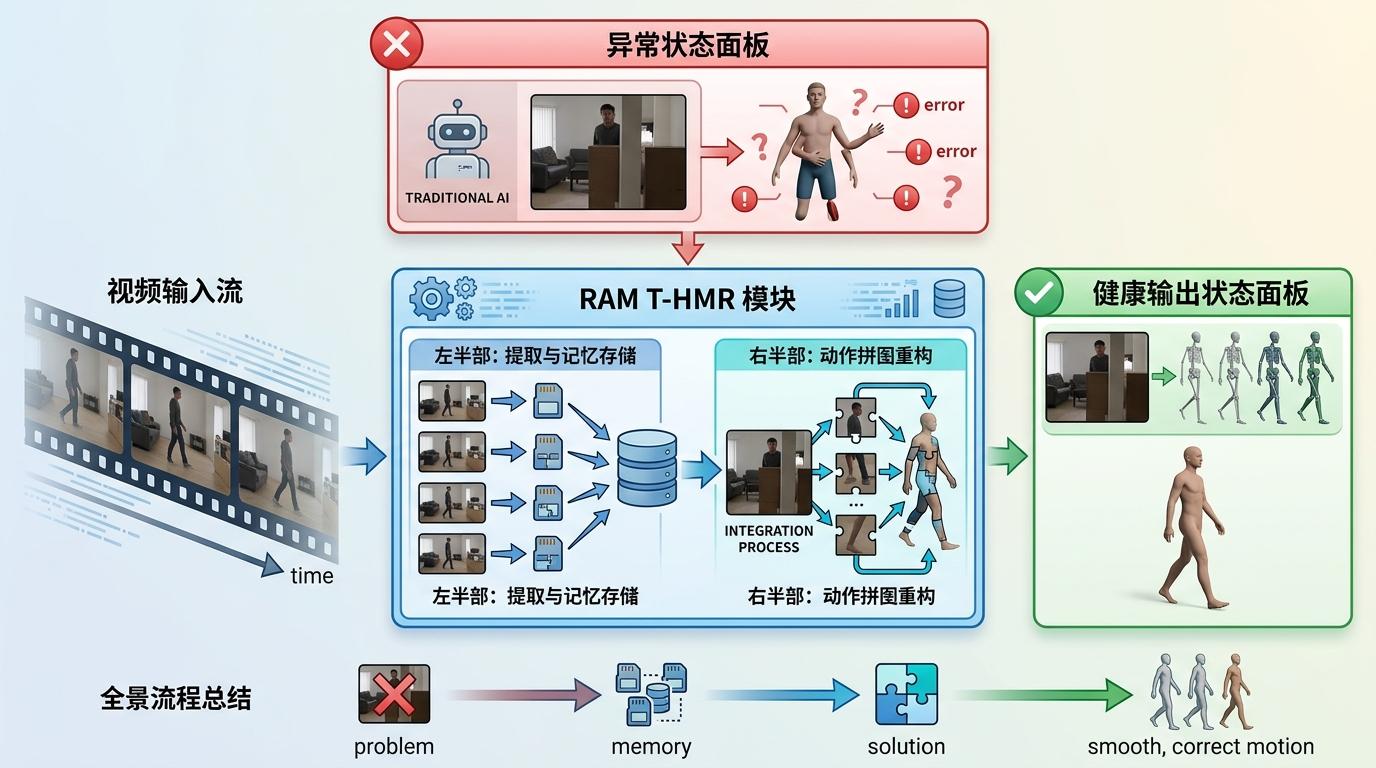
具体来说,这个模块会在相邻的几十帧里筛选最有用的动作特征,再用Transformer结构把这些跨时间的特征揉在一起。你可以把这个过程理解成:当你只看到朋友举着半只手,你会凭着之前见过他挥手的样子,自动补全他“正在挥手”的完整动作。这种基于时序上下文的建模,让RAM在当前帧信息有噪声时,也能生成平滑一致的3D人体结构。在3DPW数据集的测试中,它的三维重建误差比传统方法降低了18%。
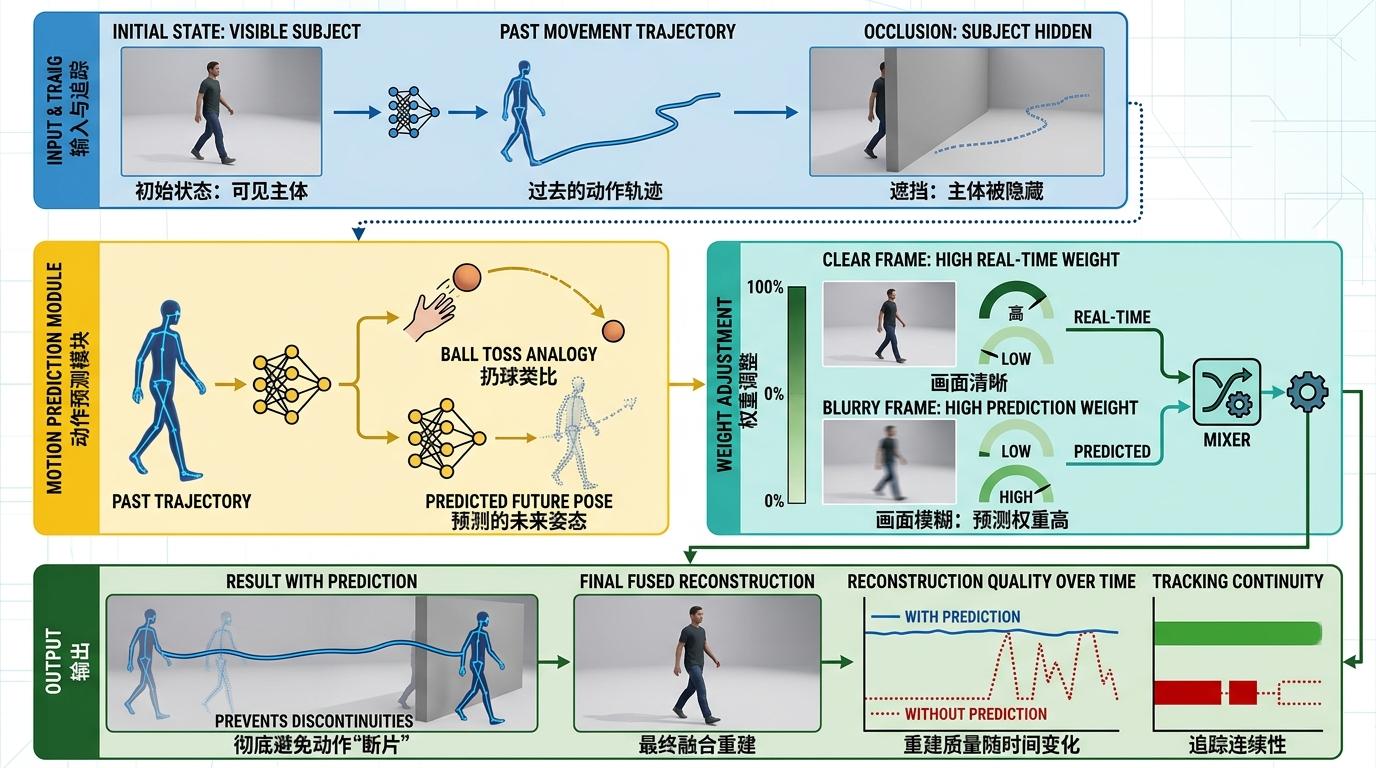
更绝的是动作预测模块——如果一个人被完全挡住,AI会凭着之前记的动作轨迹,预测他接下来的姿态,就像你看别人扔球,能凭着手臂的动作猜出球会飞向哪。最后再由融合模块根据当前画面的清晰度,自动调整“实时重建”和“预测姿态”的权重:画面清楚就信实时结果,画面模糊就多参考预测,彻底避免了动作“断片”。
更值得注意的是RAM的零样本能力——它不需要针对特定数据集额外训练,就能在陌生场景里表现出色。这就像一个学生,不用刷遍所有模拟题,只靠掌握的基础知识,就能在各种考试里拿高分。
在篮球比赛的真实视频测试中,RAM在完全没见过这类场景的情况下,把三维动作重建的准确率提升了近80%。这背后的关键,就是它不依赖特定场景的“刷题经验”,而是靠对人体运动规律的通用理解。传统方法就像死记硬背的学生,换个题型就懵;RAM则是真正理解了“人体动作怎么动才合理”,不管是篮球场还是菜市场,都能快速适应。
当然,RAM也有局限:它目前还很难处理超过5秒的完全遮挡,也没法精准捕捉人和物体的交互动作——比如手里拿的杯子怎么随着手的动作转动。但这些问题,也正是它下一步要攻克的方向。
当我们谈论AI理解世界,往往聚焦于它能“看清楚”什么,却忽略了“看连贯”的重要性。RAM的意义,不止是让视频里的人体动作不再“断片”,更是让AI第一次真正学会了“用动态的眼光看世界”——不再是孤立的瞬间,而是连续的故事。
从逐帧抓拍的“快照式认知”,到连续记忆的“日记式理解”,RAM迈出的这一步,正让AI离真正看懂人类的生活场景越来越近。毕竟,我们的世界从来不是一张张静止的照片,而是一段连续流动的时光。
真正的理解,从来都不是瞬间的捕捉,而是连续的记忆。
点击充电,成为大圆镜下一个视频选题!