对抗知识焦虑,从看懂这条开始
App 下载
给3D编辑装个定海神针,换视角再也不崩了
哈佛大学|浙江大学|三维场景编辑|3D高斯溅射|TRACE方法|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载哈佛大学|浙江大学|三维场景编辑|3D高斯溅射|TRACE方法|多模态视觉|人工智能
想象你花一下午在虚拟展厅里放了一尊雕塑——正面看比例完美,纹理细腻,转个身却发现它飘在半空中,再换个角度直接碎成了马赛克。这不是科幻片里的 glitch,而是当前3D场景编辑的真实困境:3D高斯溅射(3DGS)技术能快速渲染出逼真的三维场景,但编辑时要么只能改改颜色风格,要么改完结构就会在多视角下‘原形毕露’。浙江大学与哈佛大学的研究者联手,用一套叫TRACE的方法把这个难题给啃下来了——它让3D编辑终于能同时兼顾结构稳定和视觉自然,换多少个视角都稳如磐石。
你可以把传统3D编辑理解成‘在一张照片上P图,再把P好的效果糊到其他角度’——这种思路从根上就有问题。2D生成模型擅长画纹理、调风格,却没长‘3D空间感’,改出来的物体在单视角看没问题,换个角度就会漂移、错位,甚至直接崩塌。而那些能改结构的方法,又得靠人工一点点对齐坐标系,不仅麻烦,还容易出现边界割裂、物体穿模的尴尬。
比如给客厅加个沙发,传统方法可能在正面图里放得好好的,换到侧面看却发现沙发腿嵌进了地板里;想把老虎改成白虎,大多只能给皮毛换个颜色,连头部轮廓、尾巴形态这些结构细节都动不了。这些问题的核心,就是几何约束和生成模型各干各的,没形成真正的协同。
TRACE的解法很直接:把显式3D几何先验和视频扩散模型拧进同一条编辑流水线,让前者管‘定位准不准’,后者管‘好不好看’。它的三阶段流程像一套精密的协作工序:
第一阶段是多视角3D锚点合成。先从一个参考视角生成可靠的编辑结果,再把这个结果当‘空间锚点’,配合视觉语言模型给出的空间关系提示,一步步指导其他视角的生成。研究者还专门建了个MV-TRACE数据集,用IoU约束强化模型的空间定位能力,让它学会‘在3D空间里对齐’,而不是简单复制2D位置。
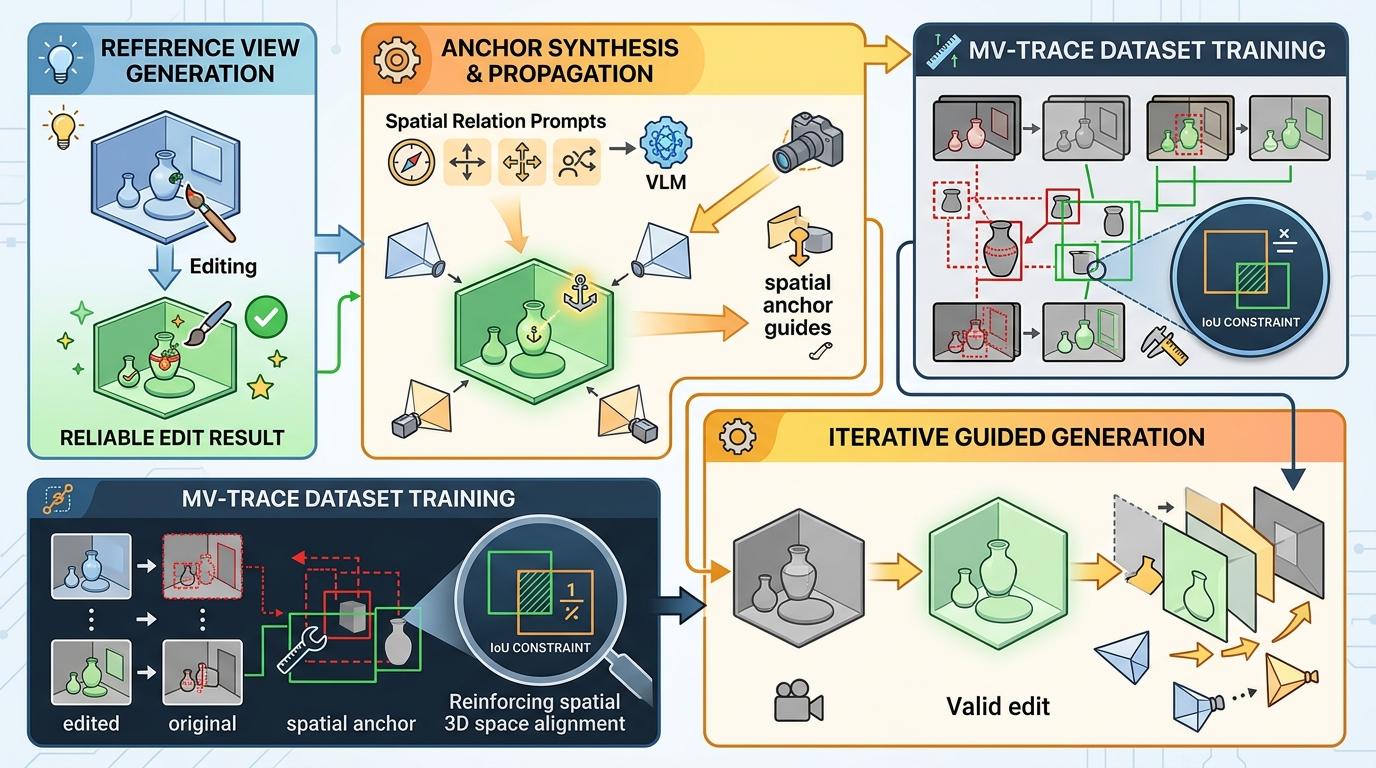
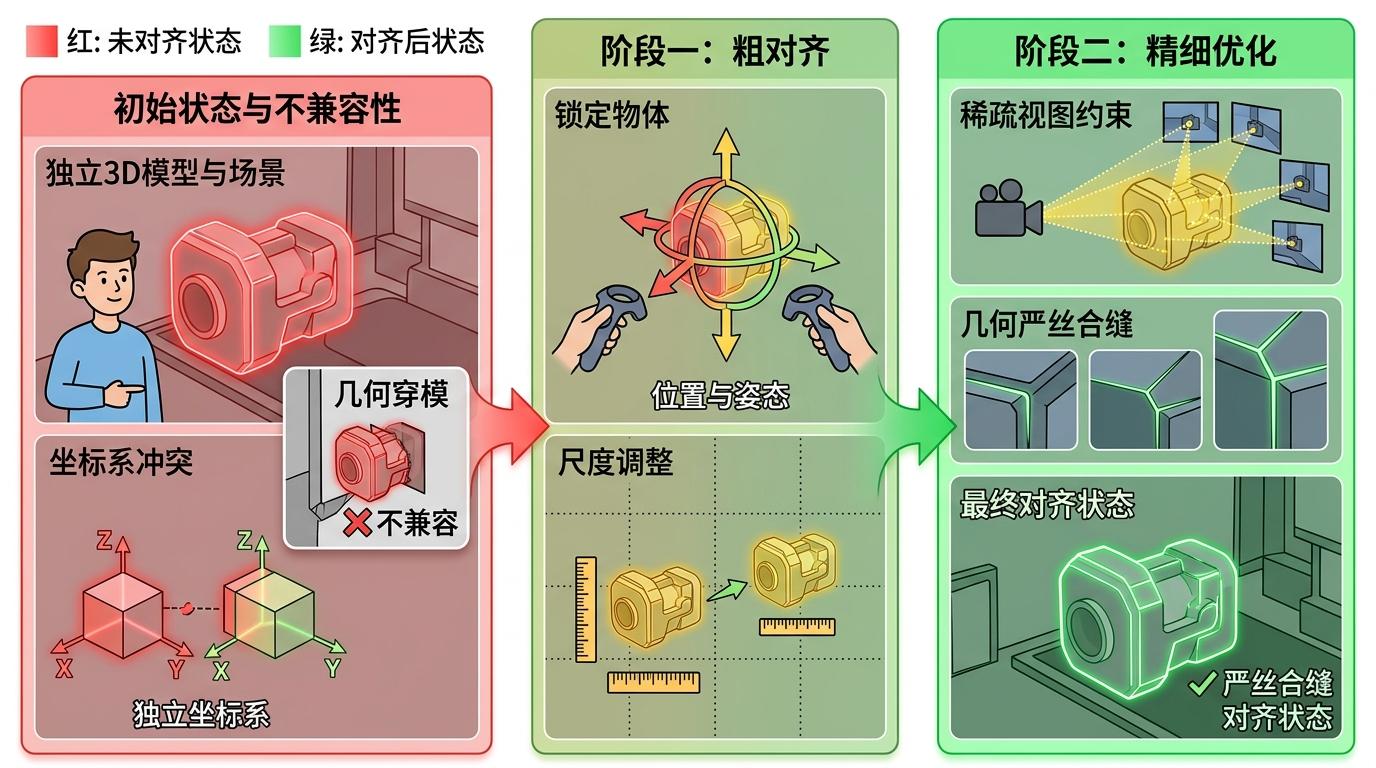
第二阶段是实打实的几何对齐。新插入的3D模型往往自带一套坐标系,直接放进去就像把美式插座插进中式插排——看着对上了,实际根本不兼容。TRACE用两阶段配准解决这个问题:先粗对齐锁定物体的位置、尺度和姿态,再用稀疏视图的几何约束做精细优化,让新物体和原场景严丝合缝,再也不会穿模或漂移。
第三阶段是上下文视频掩码重绘。它不只是改新物体本身,连阴影、反射、边界过渡这些细节一起交给视频扩散模型处理,相当于给新物体‘补全’了和环境的所有互动关系。配合自适应轨迹采样,编辑后的视频序列能完美回投到3DGS表示里,连续视角下也不会出现纹理闪烁、光照脱节的问题。
在8个场景、48个编辑案例的测试里,TRACE的优势不是单点领先,而是全方位的均衡提升。它的CLIP方向相似度达到0.1514,比次优方法高出近50%,意味着编辑内容和用户指令的语义对齐更准确;DINO多视角一致性指标达到0.9058,换视角时物体结构稳如泰山;美学评分也冲到了6.1035,视觉融合自然得不像是AI改出来的。
更难得的是,这些提升不是靠堆算力换的。TRACE编辑一个场景只需要约10分钟,和高效基线方法耗时相当,却比那些需要长时间迭代优化的方法快得多。消融实验也证明,三个模块缺一不可:多视角锚点解决了定位问题,两阶段配准保证了对齐精度,上下文重绘搞定了视觉融合——整套流水线的协同效应,才是它能突破瓶颈的关键。
TRACE的价值,不止是解决了3D编辑的老毛病,更重要的是它指明了一个方向:未来的3D内容创作,不会是纯几何方法的天下,也不会是生成模型的独角戏,而是显式约束与生成能力的深度协同。就像盖房子,几何先验是钢筋骨架,保证房子不会塌;生成模型是装修软装,让房子住着舒服、看着好看。
几何定骨架,生成填血肉,这才是3D编辑的未来。 当我们终于能在三维空间里‘所想即所得’,不管是虚拟展厅的设计、游戏场景的搭建,还是数字孪生城市的运维,都将迎来更高效、更自由的创作方式。