对抗知识焦虑,从看懂这条开始
App 下载
AI Agent普及破局:端云协同+记忆工程
多设备协作|隐私风险|Token成本|记忆工程|端云协同|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载多设备协作|隐私风险|Token成本|记忆工程|端云协同|AI智能体|人工智能
你有没有过这种经历:用AI智能体写方案,刚输入一句问候,后台就悄悄跑掉了几万Token,账单上多出一笔不明不白的开销;或者聊到一半的工作,换个设备就得从头说起,智能体像完全忘了之前的对话。2026年的AI智能体,就像一台性能强劲但油耗惊人的跑车——能跑高速,却没人敢天天开。困在Token成本、隐私风险和记忆短板里的AI智能体,真的只能是少数企业的奢侈品吗?答案藏在两种看似迥异的技术路线里。
你可以把端云协同理解成一个分工明确的办公室:端侧设备是守在你身边的秘书,负责处理日常琐事、保管敏感资料,不用动不动就麻烦总部;云端则是总部的专家团队,专门解决复杂难题、共享通用知识。这种“物理分级”的核心,是把任务按隐私和复杂度拆分:完全没敏感信息的公共任务直接扔给云端;涉及部分隐私的,先由端侧脱敏再上传;高度敏感的核心数据,就留在本地处理。
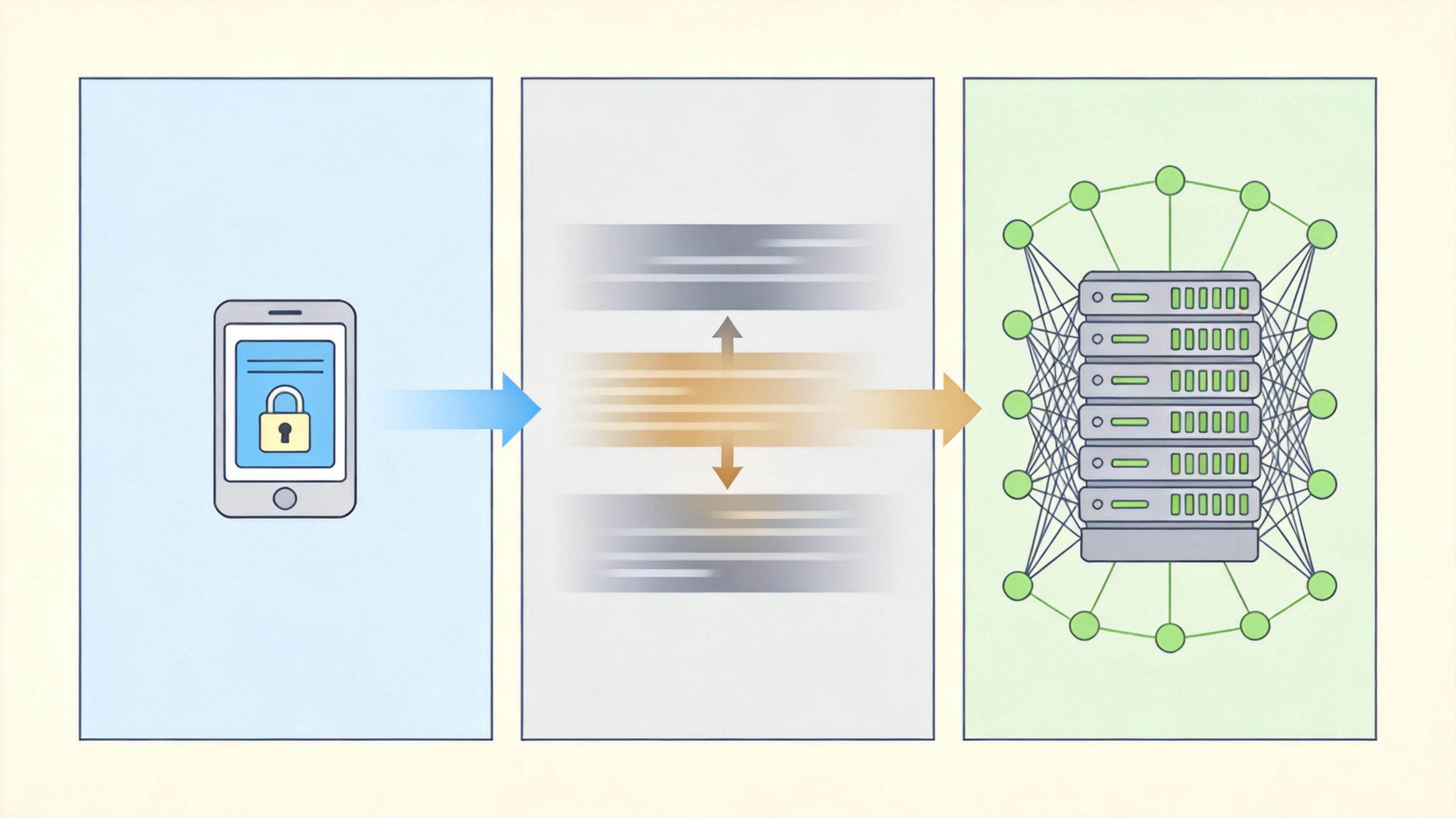
比如在内容创作场景,过去用纯云端智能体完成一篇小红书文案要花10美元,用端云协同架构后,端侧先完成素材整理和隐私过滤,只把核心需求传给云端,成本直接降到2美元。更关键的是,端侧硬件是一次性投入的固定资产,用得越久边际成本越低——就像买辆车,虽然初期花钱,但开得多了,平均到每公里的成本比打车划算得多。
如果说端云协同解决了“在哪算”的问题,记忆工程就是解决“怎么记”的问题。现在的AI智能体大多是“金鱼记忆”——要么把所有对话一股脑塞进上下文,导致Token爆炸;要么转头就忘,每次对话都要重新输入背景信息。记忆工程的思路,是给AI搭一套分层的记忆系统:
第一层是明文记忆,就像你随手记的便签,写起来快但找起来费劲儿;第二层是参数化记忆,相当于把常用知识刻进骨子里,用的时候不用翻笔记;第三层是激活记忆,就像大脑里的临时缓存,专门处理当下正在做的事。
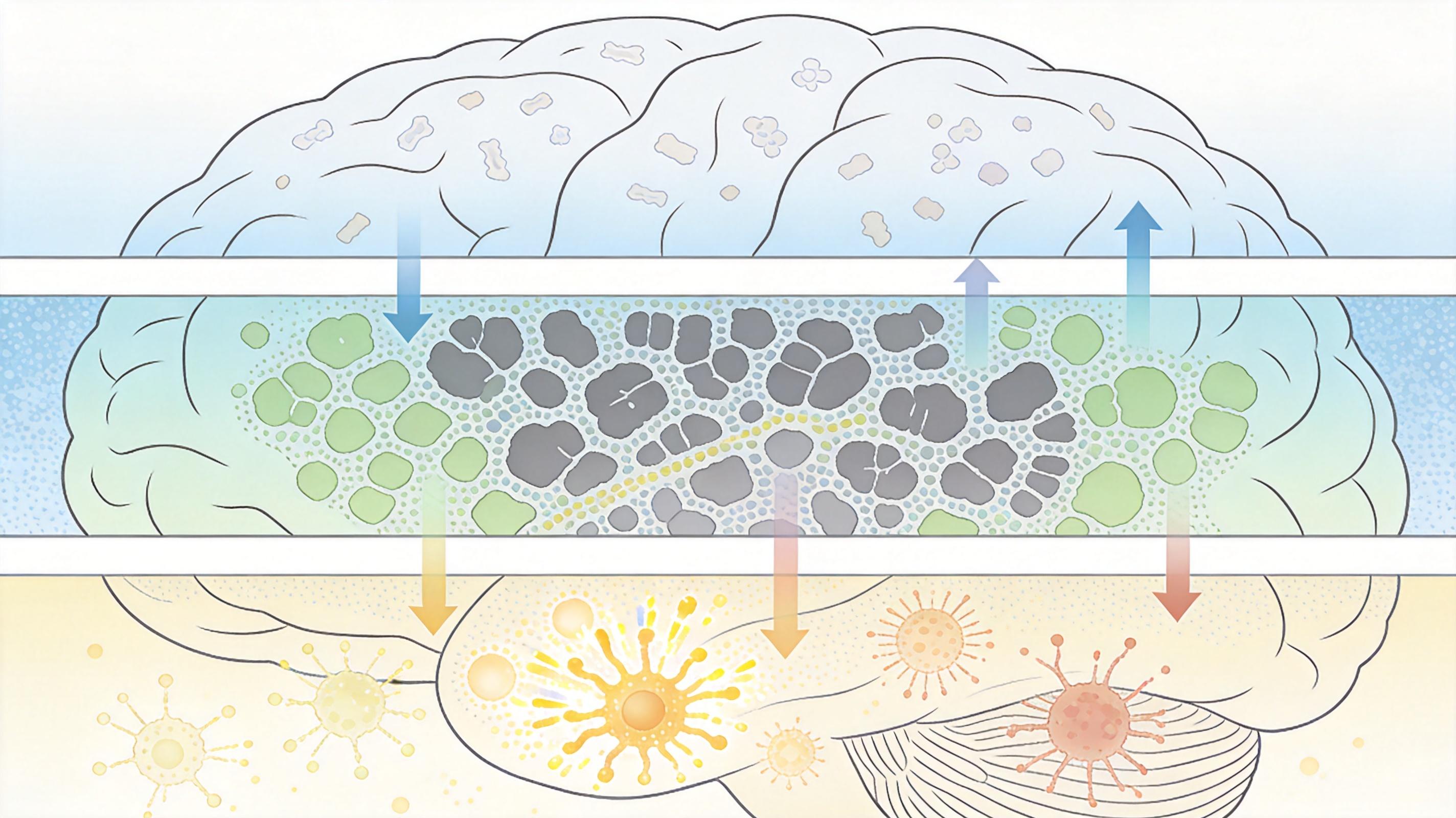
更聪明的是“Agentic抽取”机制:当你说“老地方见”,AI不会只把这句话存起来,而是会自动补全“老地方是XX咖啡馆”,把模糊的信息变成完整的记忆片段。这样下次调用时,不用再加载几万字的对话历史,只需要6K的精准片段就能搞定,Token成本直接砍去近40%。
端云协同和记忆工程不是非此即彼的选择,而是互补的组合拳。端云协同从物理层面切断无效Token的浪费,记忆工程则在逻辑层面提升记忆的使用效率。比如在跨设备协作时,端侧负责保存你的个性化记忆,云端负责同步不同设备的任务状态,你在手机上没写完的方案,到电脑上能直接接着做,不用重新交代背景。
当然,这两条路线都还有待完善:端云协同需要解决不同设备的算力适配问题,记忆工程则要平衡记忆的准确性和存储成本。但至少现在,我们已经找到了打破“安全、成本、智能不可能三角”的钥匙——不是靠更大的模型,而是靠更聪明的架构和更高效的记忆管理。
当我们不再盯着模型参数的大小,而是开始关注算力的效率和记忆的质量时,AI智能体才真正从实验室的奢侈品,变成了能走进千家万户的基础设施。就像电力普及不是因为发电机更大,而是因为电网更智能、输电更高效。
未来的AI智能体,会像你的私人助理一样懂你、靠谱,还不会乱花钱。而这一切的起点,正是端云协同和记忆工程带来的这场“效率革命”。算力有价,记忆无价,让AI用得巧,比用得大更重要。