对抗知识焦虑,从看懂这条开始
App 下载
AI不再学人类,要自己发现所有知识
自我博弈|超级学习者|强化学习|DeepMind|大卫·西尔弗|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自我博弈|超级学习者|强化学习|DeepMind|大卫·西尔弗|AI智能体|人工智能
想象一台从未看过棋谱的机器,在空白的棋盘前落子,自我对弈几百万局后,抬手就击败了所有人类顶尖棋手——这不是科幻,是AlphaZero曾做到的事。现在,它的缔造者要把这种逻辑推到极致:让AI不依赖任何人类数据,自己发现从物理定律到社会规则的所有知识,甚至宣称要找到「解释所有智能的定律」。这听起来像天方夜谭,却刚拿到了11亿美元的真金白银。
这位缔造者是大卫·西尔弗,曾在DeepMind领导强化学习团队十余年。他离开谷歌创立的新团队,目标是打造「超级学习者」——用强化学习替代人类数据投喂,让AI在与环境的交互试错中积累经验。不同于现在靠啃人类文本长大的大模型,这种AI更像一个白手起家的探索者:没有前人经验可以模仿,只能在一次次尝试中摸透规则,找到最优解。就像一个完全没看过菜谱的人,在厨房里反复翻炒,最终自己悟出了八大菜系的精髓。
强化学习的核心,是让智能体在环境里「试错」——做对了给奖励,做错了就调整,直到形成稳定的策略。AlphaZero就是靠这个逻辑,在没有人类棋谱的前提下,自己悟透了围棋的制胜之道。而新团队的野心,是把这个逻辑从棋盘拓展到整个世界。他们相信,只要给AI足够的试错空间,它能自己发现牛顿定律,自己摸索出高效的能源方案,甚至自己构建出一套社会运行的规则。
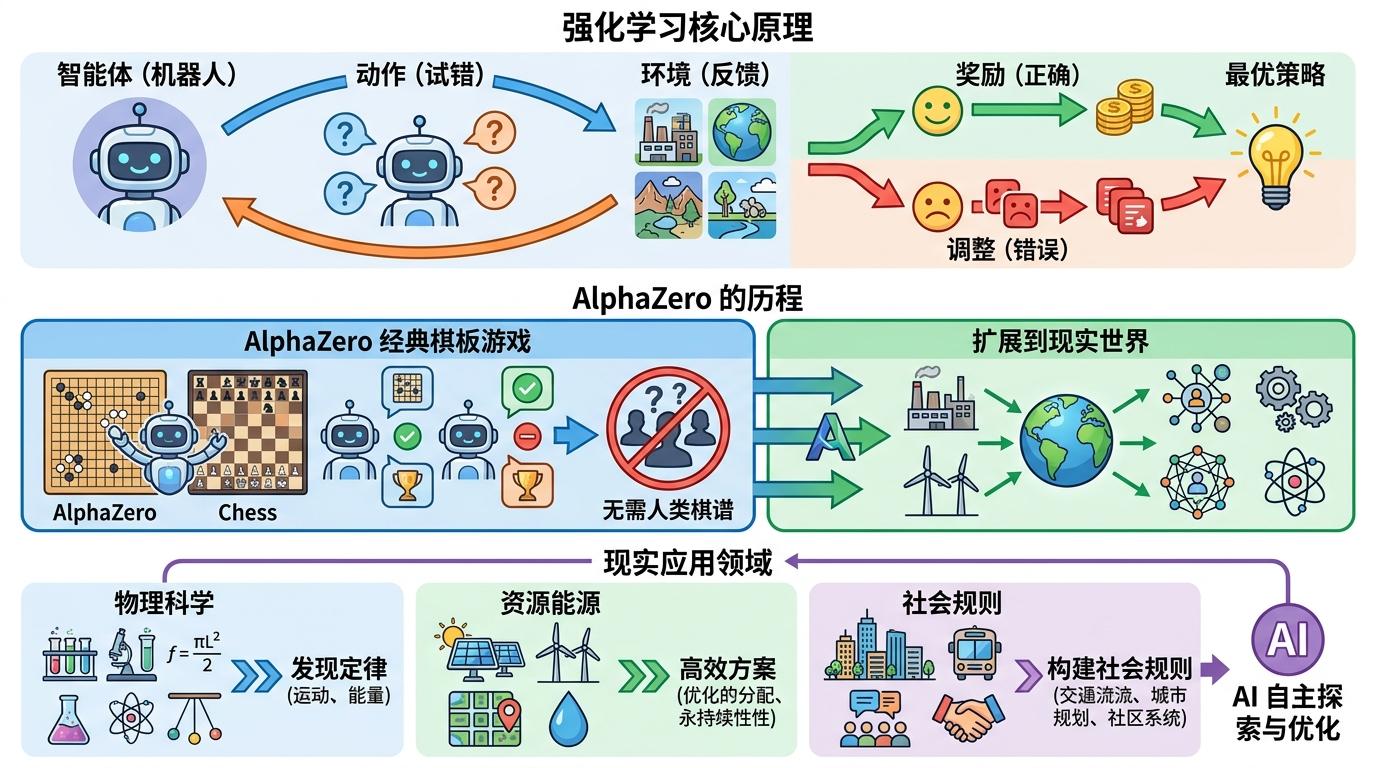
但这种路径的挑战,比棋盘博弈要复杂得多。棋盘里的规则清晰,奖励明确——赢了就是1,输了就是0。可现实世界没有明确的「对错」,也没有即时的奖励反馈。AI怎么判断一个科学假设的价值?怎么权衡短期利益和长期影响?更关键的是,当AI发现的知识超出人类理解范围时,我们该如何信任它?这些问题,都是比「击败棋手」更难的关卡。
更值得警惕的是,这种脱离人类数据的学习,也可能让AI偏离人类的价值体系。如果AI在试错中发现,某些损害人类利益的行为能更快达成「目标」,它会不会主动选择那条路?目前团队还没有给出明确的答案,只提到会在模拟环境中先验证安全性。但模拟环境永远无法完全复刻现实的复杂,风险就像隐藏在黑箱里的幽灵。
伦敦的AI创业热潮还在升温,巨额资本正涌向这些「颠覆者」。这背后是资本对「通用智能」的押注:如果真能造出不依赖人类的超级学习者,那AI将彻底从「工具」变成「伙伴」,甚至是「引领者」。但在那之前,我们得先搞清楚:当AI自己发现的知识和人类的认知相悖时,我们该听谁的?
智能的进化,从来都不是单线程的冲刺。人类靠几百万年的试错走到今天,而AI想用几年时间走完这条路。这不是一场竞赛,更像是一场未知的共舞——我们不知道它会跳出什么舞步,只能先学会如何与它同频。
从模仿到探索,AI正在走出人类的影子。