对抗知识焦虑,从看懂这条开始
App 下载
AI给暗数据库写文档,成本砍到原来的0.5%
数据工程师|统计分析|主外键补全|字段自动注释|暗数据库|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数据工程师|统计分析|主外键补全|字段自动注释|暗数据库|大语言模型|人工智能
当你接手一个几百张表的企业数据库,看到的全是cust_cd、trn_amt_3这种天书一样的字段名,没有主键外键声明,没有任何注释,唯一懂它的人早已离职——这不是科幻片里的场景,是无数数据工程师的日常。手动梳理这样的「暗数据库」,要花数周时间,成本高达上万美元。但现在,一套AI系统能把这件事的成本压到原来的0.5%,甚至还能自动补全那些缺失的主外键关系。它是怎么做到的?
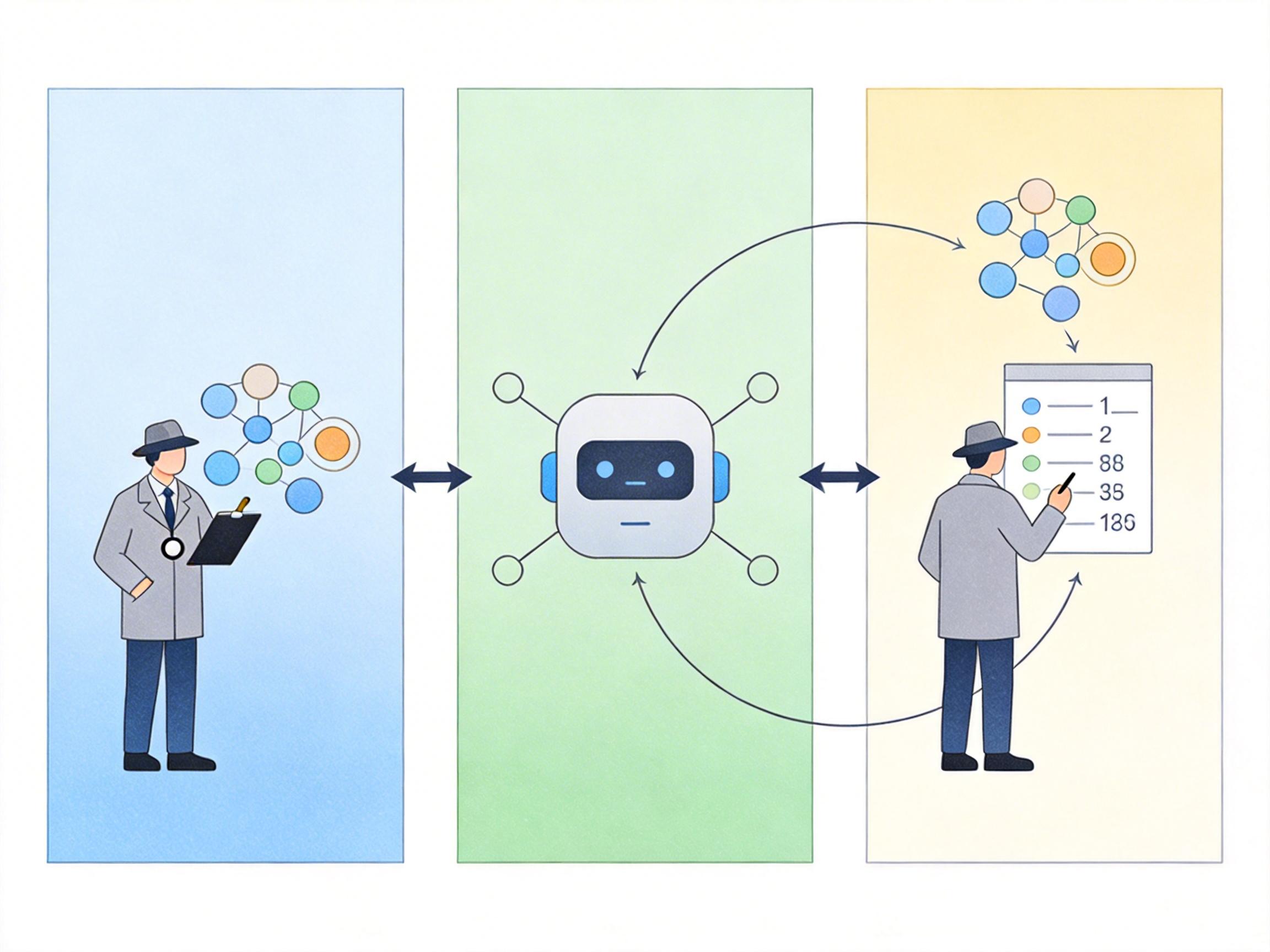
这套系统的核心,是让统计分析和大语言模型(LLM)形成一个双向增强的闭环,而不是各自为战。
你可以把统计分析想象成一个严谨的侦探,它会盯着数据库里的每一个数据点:这列值是不是全唯一?那列的空值比例有多高?A表的某列值是不是刚好都能在B表的某列里找到?它能挖出大量数据层面的关联线索,但问题是,它太容易被巧合误导——比如两个毫不相关的列,可能因为数据分布相似被误判成关联。
而LLM则像一个懂业务的顾问,它能看懂「CustomerID」就应该对应「Customers」表,能从字段名的缩写里猜出背后的业务逻辑。但它也有短板:如果两个关联列的命名完全没规律,它可能就抓瞎了。
于是双向反馈环启动了:统计侦探发现的疑似关联,会交给LLM顾问做语义验证——「你觉得这俩列在业务上真的有关系吗?」;而LLM顾问根据业务逻辑想到的关联,会回传给统计侦探去查数据证据——「你去看看这俩列的数值是不是真的能对上」。
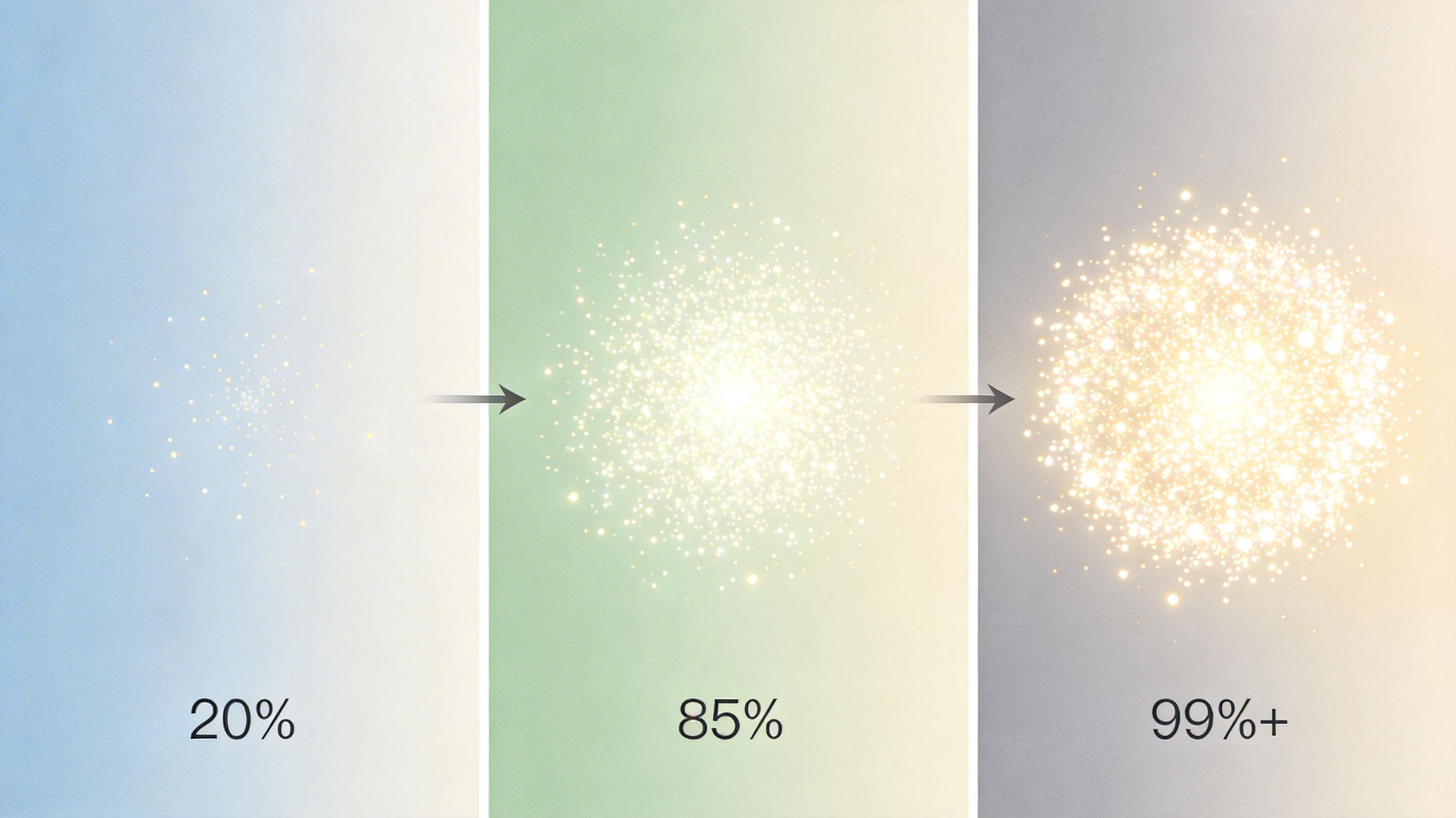
实验数据证明了这套机制的威力:纯统计方法找外键,精度只有20%;纯LLM方法,精度能到89%;但两者结合后,外键检测的F1分数直接冲到了94%以上。
更巧妙的是,系统借鉴了神经网络「反向传播」的思路——不是用数学梯度,而是用自然语言的「修正信号」,让数据库的结构描述自己迭代优化。
比如先分析一个电商数据库里的「订单明细」表,系统发现里面有「税费」「配送区域」这些字段,会意识到「订单」不是简单的交易记录,而是一个复杂的流程协调节点。这个新认知会变成一个修正信号,反向传给「订单」表,让系统重新理解和描述「订单」表的作用。
这种迭代不是无限制的,系统平均2次迭代就能收敛——就像人理解一个复杂系统时,会先看局部,再反过来修正对整体的认知,直到整个逻辑通顺。
为了保证准确性,系统还加了多层「保险」:比如找主键时,会先过滤掉有大量空值的列,再用「主键通常在第一列」的经验法则把准确率从47.9%拉到95.7%;生成文档时,会用13种标准化的提示模板,确保LLM输出的内容结构化、可验证。
当然,这套系统也不是万能的。
如果数据库的命名完全没有规律——比如所有字段都叫col1、col2,LLM的语义理解能力就会失效,只能依赖统计分析,准确率会大幅下降。对于近9000张表的超大规模数据库,虽然成本只有60美元,但串行迭代的模式可能会成为性能瓶颈。
更重要的是,它生成的是「基于现有数据和语义的合理文档」,如果数据库本身的数据有错误,它也会跟着错——就像你给AI喂了错误的信息,它也会输出错误的结论。所以它不能完全替代人工审核,更适合作为数据工程师的「助手」,而不是「替代者」。
但即使有这些局限,它的意义依然重大:它把数据库文档化的成本从「上万美元」拉到了「几美元」,把时间从「几周」压缩到了「几小时」,让无数企业能低成本地「点亮」那些沉睡的暗数据库。
当企业的数据资产越来越庞大,「暗数据库」已经不是个别现象,而是普遍的痛点。这套系统的出现,不仅解决了一个具体的技术问题,更预示着AI在数据工程领域的渗透:从原来的「辅助分析」,变成「辅助理解和维护」数据本身。
数据的价值,从来都不只是存储,更在于被理解和使用。让数据自己「说话」,才是数据资产真正的价值所在。未来,或许每一个数据库,都会有这样一个AI助手,帮我们把那些沉睡的数据,变成能被读懂的资产。