对抗知识焦虑,从看懂这条开始
App 下载
4B参数模型,看懂手术比GPT-5.4强50倍
医疗视频大模型|腹腔镜胆囊切除术|手术视频理解|uAI Nexus MedVLM|多模态视觉|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载医疗视频大模型|腹腔镜胆囊切除术|手术视频理解|uAI Nexus MedVLM|多模态视觉|临床诊疗技术|医学健康|人工智能
当一台腹腔镜胆囊切除术进行到第15秒,抓钳正牵拉胆囊暴露手术视野时,GPT-5.4只能笼统描述“有器械在操作”,Gemini 3.1把抓钳认成了电凝钩,某国产大模型完全搞不清动作逻辑。但有个模型能精准说出:“左上方抓钳持续向上牵引胆囊,为钩子暴露分离平面”——它就是uAI Nexus MedVLM,一个参数仅4B/7B、单卡就能跑的医疗视频大模型。它在手术安全评估上的准确率达到89.4%,是GPT-5.4的50倍。为什么一个“轻量级”模型,能在通用大模型折戟的领域做到如此精准?这得从手术视频理解的三重“地狱级”难关说起。
在医疗AI领域,影像诊断、病历书写早已落地,但手术视频理解却长期是无人敢闯的禁区,核心卡在三道坎上。
第一关是数据难如登天。手术视频涉及患者隐私,采集要过伦理关,标注要靠专业医生逐帧标记器械、动作、解剖结构——成本高到能劝退99%的团队。此前全球公开的手术视频数据集加起来,也不及这个模型训练数据的十分之一。
第二关是没有“公共标尺”。各机构用自己的数据集、自己的指标,模型效果根本没法比:你说你的动作识别准确率90%,我说我的是95%,但大家的标注标准天差地别,最后全是自说自话。
第三关是任务复杂到离谱。手术视频要的不是“大概看懂”,是毫米级的空间精度——差一毫米可能就认错了血管;是严格的时序逻辑——胆囊必须先分离再切除,颠倒顺序就完全错误;还要懂临床语义——知道什么时候是“关键安全视野”,什么时候操作有风险。这些约束叠加,通用大模型的“通用优势”瞬间变成劣势。
uAI Nexus MedVLM的突破,本质是用医学专属逻辑重构了大模型的训练和评测体系。
首先是搞定了数据难题。团队整合了8个专业医学数据集,汇聚超53万条视频-指令对,覆盖内镜、腹腔镜、机器人手术等几乎所有手术场景。更关键的是,他们同步推出了MedVidBench测试集——6245个标准视频-指令对,第一次给行业提供了“公共标尺”。以后谁的模型强,拉到这个测试集上跑一遍就知道,不用再靠嘴说。
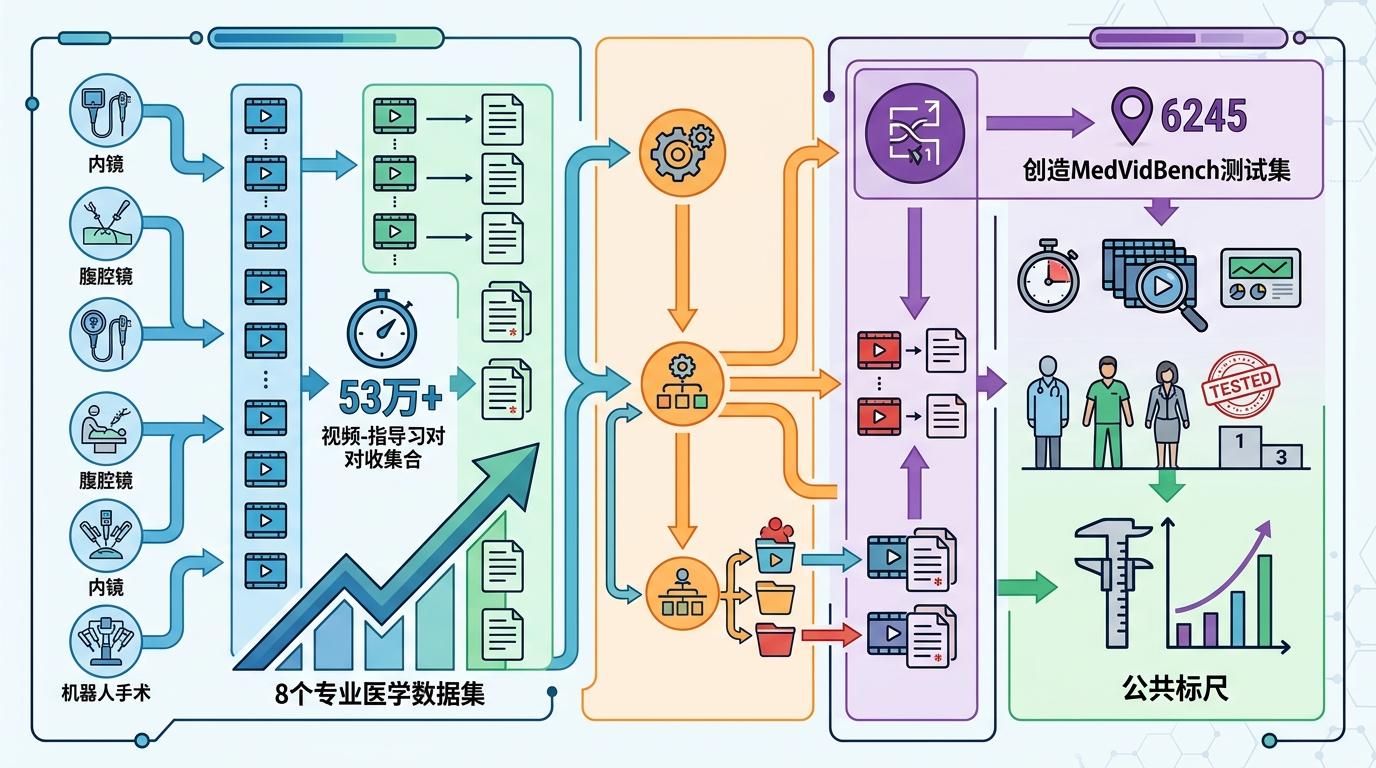
然后是解决了多任务训练的稳定性问题。传统强化学习在多数据集训练时,会因为不同数据集的奖励尺度不一“偏科”——专挑简单的数据集学,难的直接放弃。团队研发的MedGRPO框架,用跨数据集奖励归一化把不同任务的难度拉到同一水平线,让模型能均衡学习所有场景的知识。经这个框架优化后,模型的手术步骤识别能力直接暴涨52%。
最后是给AI装上了“医学大脑”。他们没有用通用大模型的评判标准,而是专门设计了医学LLM评判机制,从医学术语精度、器械识别、临床上下文等五个维度打分,确保AI输出的不是“听起来像回事”的套话,而是符合临床规范的专业内容。
现在的uAI Nexus MedVLM,已经能实实在在地走进临床场景。
术前,它能分析上万台顶级专家的手术视频,把分散的经验沉淀成可复用的临床规律——比如哪种分离手法能降低胆囊管损伤风险,哪个步骤最容易出现视野盲区。年轻医生不用再靠“师傅带徒弟”式的经验积累,就能站在专家的肩膀上制定手术方案。
术中,它是实时的“安全哨兵”。在分离胆囊管、显露安全视野这些关键步骤,它能毫秒级识别动作偏差,给出预警。比如当器械靠近血管时,它会提示“注意避免血管损伤”;当视野偏离关键区域时,它会提醒“请调整镜头至安全视野”。
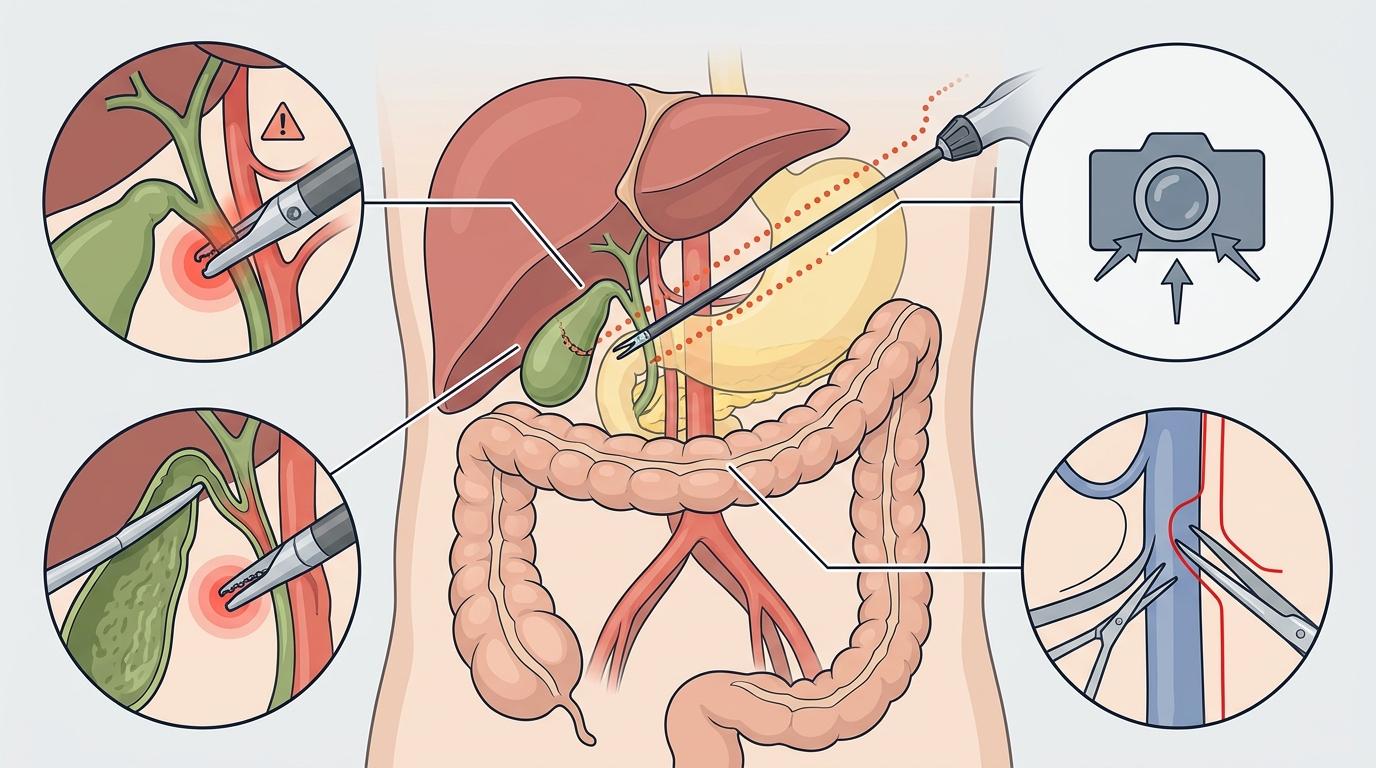
术后,它能自动生成结构化手术报告。医生不用再花一两个小时整理手术记录,上传视频就能一键拿到包含手术步骤、器械使用、关键操作的标准化报告,把时间还给临床。
当然,它也有局限:目前对罕见手术场景的覆盖还不够全,在复杂并发症的判断上仍需医生把关。但不可否认的是,它已经打破了通用大模型的天花板,让手术视频理解从“实验室炫技”走向了“临床实用”。
当我们谈论医疗AI的未来时,常常会陷入“模型越大越好”的误区,但uAI Nexus MedVLM用事实证明:精准,比通用更重要。它没有追求百亿级的参数规模,而是把算力和数据都用在了“医学专属”的刀刃上——这才是医疗AI该有的方向:不是要取代医生,而是要成为医生的“第三只眼”,把人类的经验沉淀成可传承的智慧,让优质医疗资源能真正下沉到每一个需要的地方。
未来的手术室里,AI不会是主角,但一定会是最靠谱的搭档。