对抗知识焦虑,从看懂这条开始
App 下载
AI视觉反直觉突破:VIPA如何让图像自己说话?
目标物体识别|自然语言描述|指代图像分割|VIPA方法|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载目标物体识别|自然语言描述|指代图像分割|VIPA方法|多模态视觉|人工智能
“帮我拿一下桌上那个红色的、带条纹的马克杯。”
这句简单的指令,对人类而言轻而易举,但对人工智能(AI)来说,却是一个长期存在的难题,被称为“指代图像分割”(Referring Image Segmentation, RIS)。它要求AI在一张复杂的图片中,仅凭一句自然语言描述,就精确地“抠”出目标物体。多年来,AI科学家们一直在试图填补语言的抽象世界与视觉的具象世界之间的巨大鸿沟。
传统的解决方案思路直接而“强硬”:让强大的语言模型(如BERT或大语言模型)去深度“理解”这句话,然后将这份“理解”强行注入到视觉模型中,告诉它应该看哪里。这就像让一个只懂图像的工匠,去听一位语言大师的抽象指挥。指令再精妙,经过跨模态的“翻译”,总会产生信息损耗和误解,导致AI的注意力“跑偏”——要么漏掉目标的一部分,要么把无关的背景也圈了进来。
2026年2月,一篇由韩国西江大学、LG电子、三星电子及釜山大学联合发表的论文,为这个困境带来了一个石破天惊的解决方案。他们提出的VIPA(Visual Informative Part Attention)框架,彻底颠覆了“语言指导视觉”的传统范式。
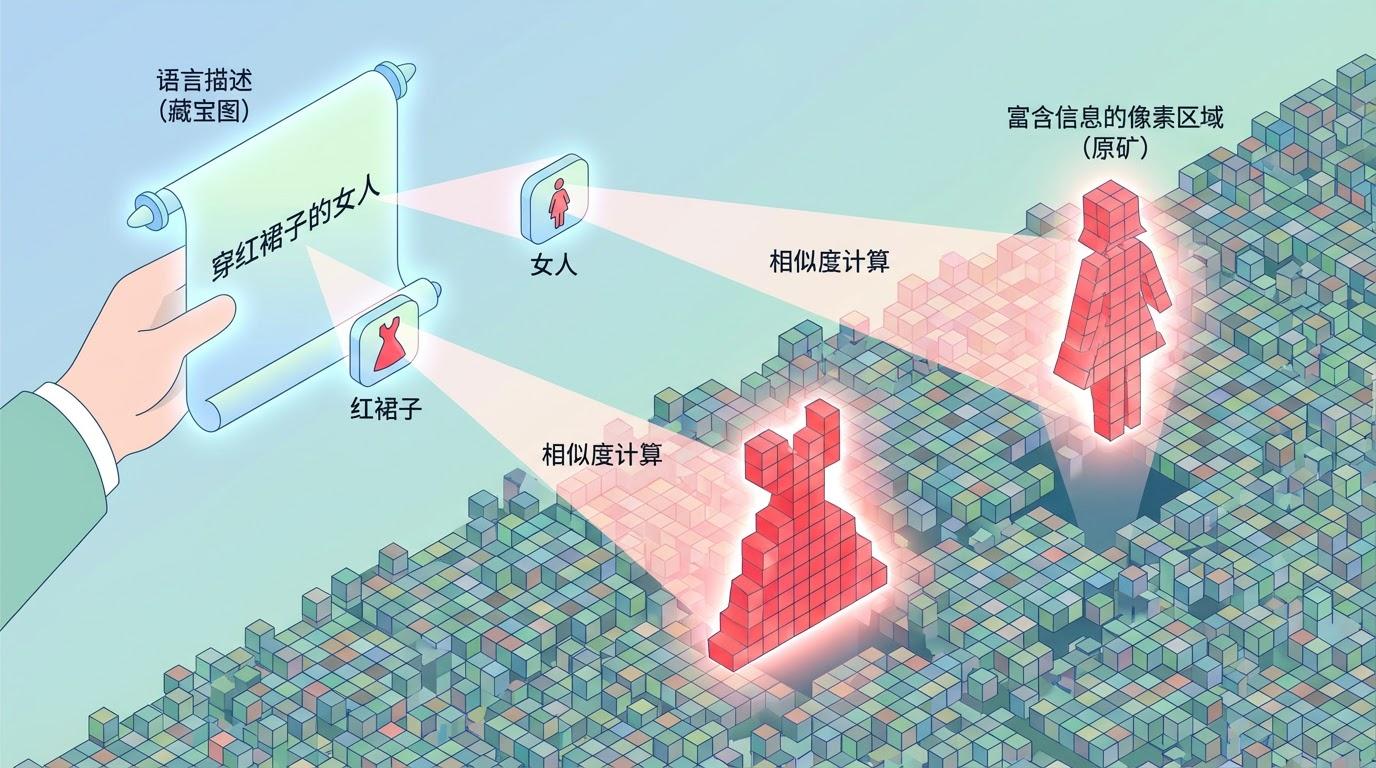
VIPA不再强迫视觉模型去“听懂”语言,而是反其道而行之,让图像根据语言线索,自己“说”出关键信息。它从图像中检索并提炼出与描述最相关的部分,形成一种纯粹的“视觉表达”(Visual Expression),并用这种同源的视觉信息来引导分割。这一“反直觉”的思路,不仅在多个权威数据集上全面超越了现有SOTA(最先进)模型,其计算效率更是达到了巨型语言模型方案的30倍,为高效、精准的多模态交互开创了新纪元。
VIPA的诞生,源于对模态鸿沟根源的深刻洞察。语言是线性的、抽象的,而视觉是空间的、具体的。当视觉模型(查询方)试图理解语言特征(引导方)时,本质上是在进行一场困难的“跨语种”交流。
VIPA的巧思在于,它让这场交流回归“母语”。其核心思想是:
打个比方,传统方法是给机器人一本文字说明书,让它按图索骥。而VIPA则是直接从现场(图像)找出几个和目标最像的样本(视觉表达),让机器人“照着样子找”。哪种方式更精准,不言而喻。
那么,这个神奇的“视觉表达”是如何被精准地“挖掘”和“提炼”出来的呢?VIPA设计了一个精巧的“视觉表达生成器”(VEG),分两步走:
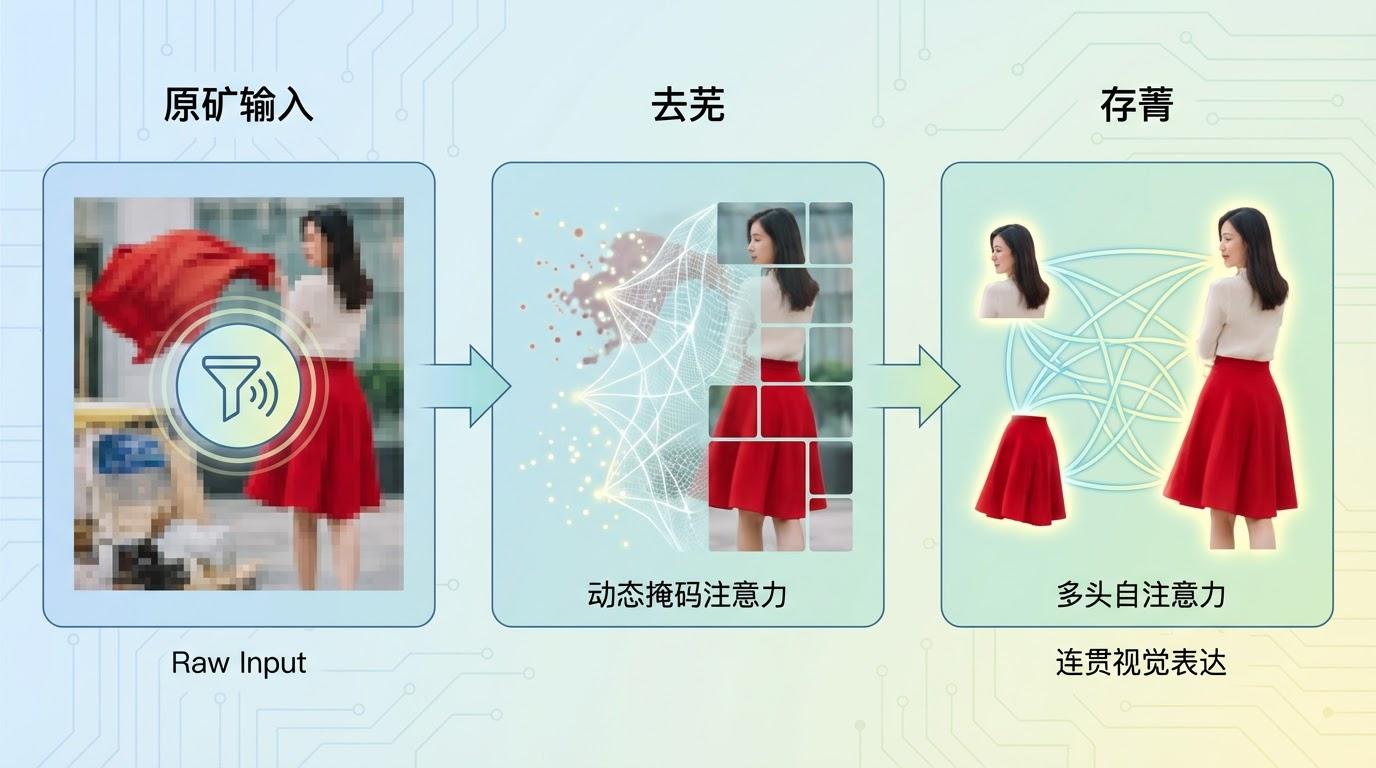
这个高质量的“视觉表达”随后被送入分割解码器,作为最可靠的“路标”,引导模型完成最终的精准分割。
理论上的优雅必须经受现实的检验。VIPA的实验结果堪称惊艳:
可视化对比更加直观。在处理“男人右手拿着的黄色东西”这类复杂指令时,强大的LLM模型可能会错误地分割左手的物体,而VIPA却能精准定位,其分割结果的完整性和准确性令人信服。
VIPA的价值远不止于提升一项任务的性能。它提出了一种全新的、可被广泛推广的多模态交互范式:
在需要跨模态对齐的任务中,当一个模态(如视觉)是主体时,它可以主动地从自身内部,根据另一模态(如语言)的线索,构建一个高质量的、同模态的“表达”来引导自己,而不是被动地接受异构信息的注入。
这一思想可以延伸至众多领域:
VIPA如同一把钥匙,打开了“以视觉信息引导视觉理解”这扇大门。它标志着AI正从依赖“翻译”的跨模态交互,迈向更接近生物直觉的、基于“母语”的同模态自引导。这不仅是技术的胜利,更是我们对机器认知理解的一次深刻跃迁,预示着一个更高效、更精准、更无缝的人机共存时代的到来。