
13 小时前
13 小时前
想象一下:你手里攥着9亿周活用户的产品,却有80%的人一年跟它互动不到1000次;你砸下数百亿训练出的模型,对手每隔几周就能拿出性能不相上下的替代品;你靠品牌攒下的名气,在巨头的基础设施和流量面前不堪一击。
这不是虚构的创业困境,而是顶级科技分析师Benedict Evans给OpenAI下的诊断书——它正握着科技史上最昂贵的「大宗商品」,却没有能守住市场的护城河。为什么曾经的AI领头羊会走到这一步?我们得先搞懂,什么是大模型的「大宗商品化」。
在工业时代,原油是典型的大宗商品:不管你从哪个油田开采,只要品质达标,就能用来炼汽油、造塑料——买家只看价格和供应量,不关心产地。现在的大模型,正沿着一模一样的轨迹演化。

Evans在分析中戳破了AI行业的「皇帝新衣」:没有任何证据表明,领先模型能阻止对手做出同样好的产品。Claude、Gemini、Llama轮流领跑,每隔几周就有新模型刷新性能纪录,所谓的「技术壁垒」不过是暂时的算力和数据领先。更关键的是,大模型没有网络效应——你用Windows是因为别人都用,你用谷歌是因为它的搜索结果会随用户点击优化,但大模型做不到:用户不会因为朋友用ChatGPT,就必须放弃Claude;企业也不会因为开发者给某个模型写了插件,就被绑定死。
OpenAI没有自己的芯片工厂,没有独占的基础设施,甚至连训练数据的来源都跟对手高度重叠。它唯一的优势,是用户先入为主的「心理份额」——就像1995年的网景浏览器,靠先发优势攒下了名气,却在微软把IE绑定进Windows后迅速溃败。当技术变成人人都能生产的标准化商品,名气撑不起护城河。

如果说「大宗商品化」是OpenAI的慢性病,那「财务重力」就是悬在头顶的达摩克利斯之剑。
Meta最新的财报数据像一声警钟:它今年的资本开支将占到总收入的50%以上——不是利润的50%,是每赚100块钱,就要拿50块钱去买芯片、建数据中心。OpenAI的日子更不好过:2025年亏损近80亿美元,2026年预计亏140亿,未来8到10年还要砸1.4万亿美元建基础设施。这些钱不是凭空来的,AI行业正陷入一场「左手倒右手」的循环游戏:英伟达把芯片卖给云服务商,云服务商把算力租给AI公司,而AI公司的融资又来自这些巨头。
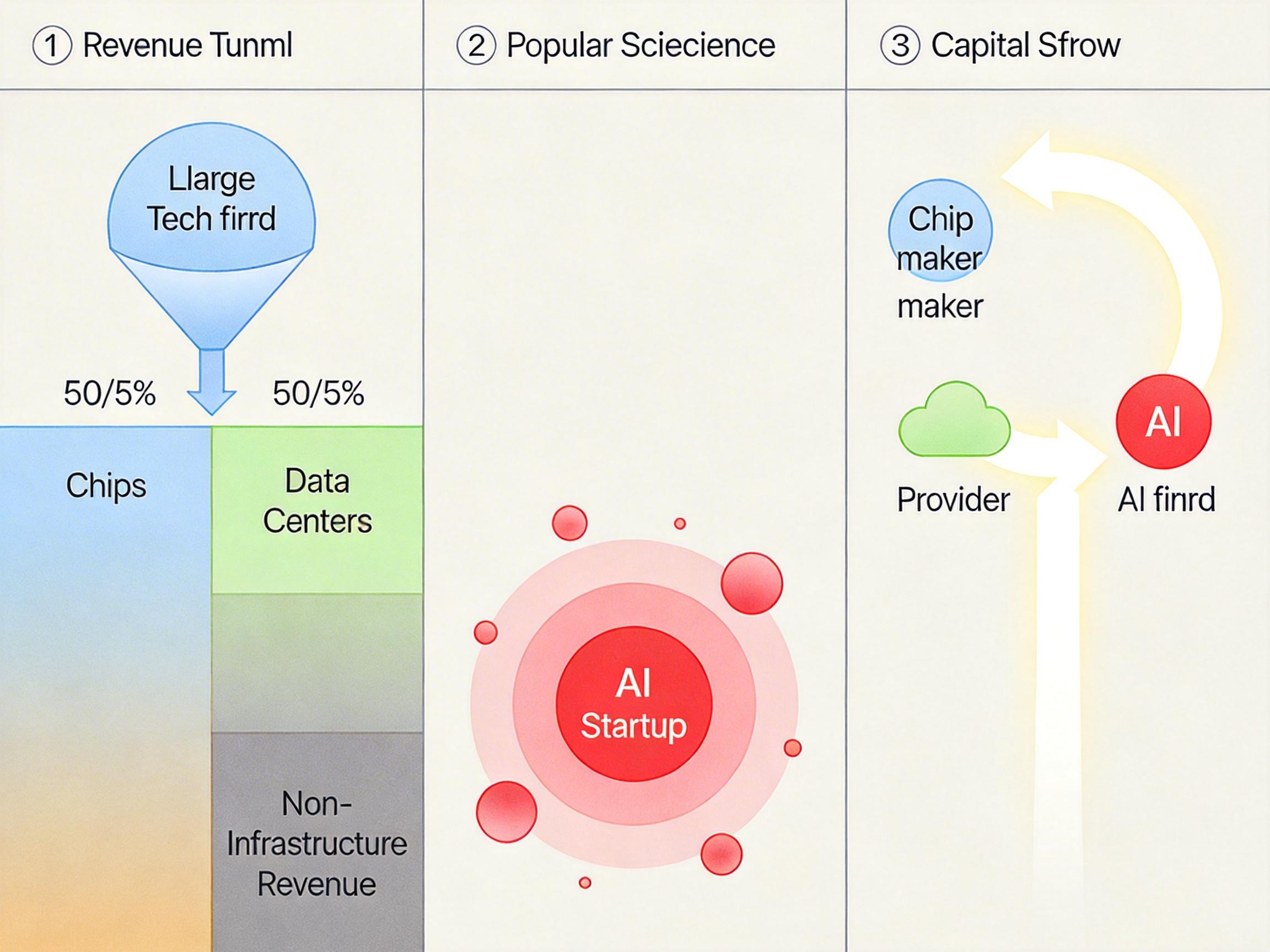
更致命的是用户的真实需求:ChatGPT有9亿周活,但80%的用户一年输入不到1000次指令,平均每天交互不足3次。对普通人来说,它只是偶尔用用的文案工具或搜索增强器,不是离不开的生产力中枢。这导致只有5%的用户愿意付费——靠这样的收入,连覆盖算力成本都难。
更值得关注的是,就算模型准确率从90%提升到95%,用户还是得人工检查结果。只要AI做不到「绝对正确」,就没法真正嵌入人类的工作流,也就赚不到能支撑烧钱模式的真金白银。
科技史上的垄断,从来都不是靠技术领先,而是靠生态锁定。Windows靠开发者生态,谷歌靠用户数据网络效应,Facebook靠社交关系链——但这些逻辑在大模型行业通通失效。
你没法靠「用户越多模型越好」建立壁垒,因为大模型的优化靠的是训练数据,不是实时的用户交互;你也没法靠「开发者绑定」锁定市场,因为大模型的接口都是标准化的,换个模型就像换个API地址。OpenAI试图用AI代理工具抢占用户桌面,却直接撞上了谷歌和苹果的生态墙——当AI想接管你的收件箱和文件,隐私、权限、系统控制权,每一样都比算法更难逾越。
现在的AI行业,正从「比谁的模型更聪明」转向「比谁能把模型用得更聪明」。真正的护城河不再是模型本身,而是对行业痛点的理解、对现有系统的集成能力,以及能让用户离不开的场景。比如在医疗领域,能读懂病历、对接医院系统的AI工具,比单纯的通用大模型值钱得多;在企业服务领域,能嵌入ERP、自动生成报表的AI,才是企业愿意付费的产品。
当我们谈论OpenAI的困境时,其实在谈论整个AI行业的转型阵痛。曾经被捧为「下一代操作系统」的大模型,正在褪去神秘光环,变成像云计算、数据库一样的基础设施。
「技术越普及,壁垒越在人心与场景」,这句话正在AI行业应验。未来的AI巨头,不会是那个训练出最大模型的公司,而是那个能把AI缝进用户日常工作、解决真实问题的公司。就像没人会为「电」本身付费,但会为用电的冰箱、空调、工厂买单——大模型的未来,从来都不在模型里。
点击催更,成为大圆镜下一个视频选题!