对抗知识焦虑,从看懂这条开始
App 下载
AI能画迷宫解皇后,却还不会像人一样规划
北京通用人工智能研究院|上海交大|图像编辑模型|视觉规划|迷宫解题|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载北京通用人工智能研究院|上海交大|图像编辑模型|视觉规划|迷宫解题|多模态视觉|人工智能
当你盯着一张3×3的迷宫图,不用开口,脑子里瞬间就能勾画出从起点到终点的路径——这是人类与生俱来的视觉规划本能。但对现在的AI来说,哪怕是最顶尖的图像编辑模型,在没经过专门训练的情况下,解迷宫的通过率最高也只有5.4%,还常常犯“穿墙”“漏画路径”的低级错误。上海交大和北京通用人工智能研究院的一项新研究,把AI的这种“视觉短板”摆到了台面上:他们让AI直接在图像上完成规划任务,不用转成文本,不用分步推理,结果发现,AI确实能“画”出答案,但离真正的“规划”还差着好几段认知距离。
过去,AI解迷宫、摆皇后这类问题,得先把图像转成文本描述,再让大语言模型推理,相当于“用嘴思考”。这次研究团队反其道而行之,提出了“编辑即推理(EAR)”的思路:直接让图像编辑模型把迷宫原图,一步改成走完的路径图;把空棋盘,一步改成符合规则的皇后布局。
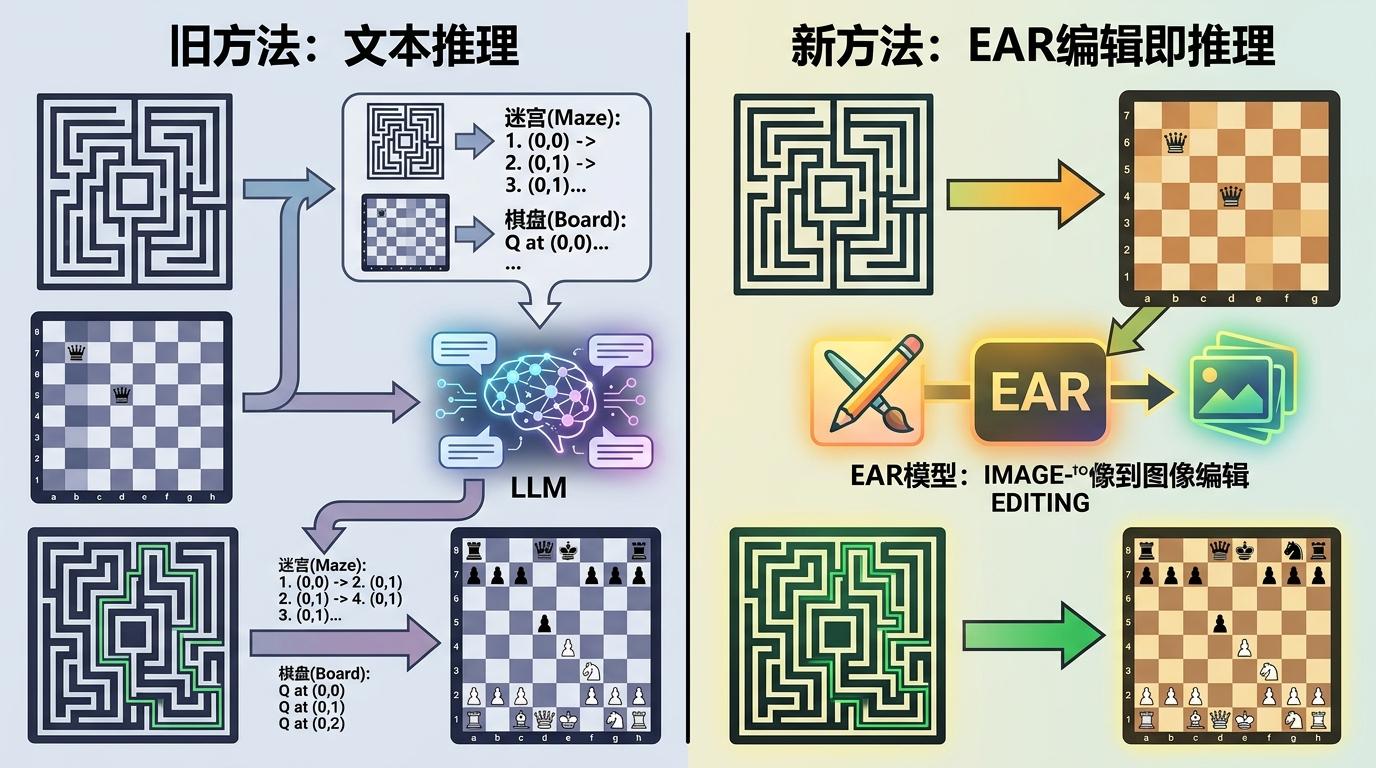
为了公平测试,他们搭建了AMAZE基准——2800个不同大小、不同几何形状的迷宫,350个不同规模的皇后问题,用“覆盖度”“违规率”“通过率”等硬指标打分。结果让人大跌眼镜:零样本状态下,哪怕是闭源的顶尖模型,迷宫任务的最高通过率也只有5.4%,皇后任务更是大多接近0。有的模型会直接“穿墙”,把迷宫边界当摆设;有的模型画了半截路径就停手,根本到不了终点。
但当研究人员用最简单的3×3迷宫和4×4棋盘对模型做微调后,变化出现了:以扩散式模型Bagel为例,迷宫任务的通过率从0涨到了11.54%,皇后任务也达到了14.57%,比自回归模型的提升幅度高出一大截。
为什么扩散式模型比自回归模型更擅长视觉规划?这得从它们的生成逻辑说起。
你可以把扩散模型想象成“从模糊到清晰画画”:它先在满是噪声的图里,慢慢勾勒出全局的大致结构——比如迷宫里一条模糊的路径,棋盘上几个大概的落子点,然后再一步步去掉噪声,把细节补全,同时修正错误的分支。这个“先搭骨架,再填细节”的过程,刚好契合人类视觉规划的思路,天生擅长维护全局的空间一致性。
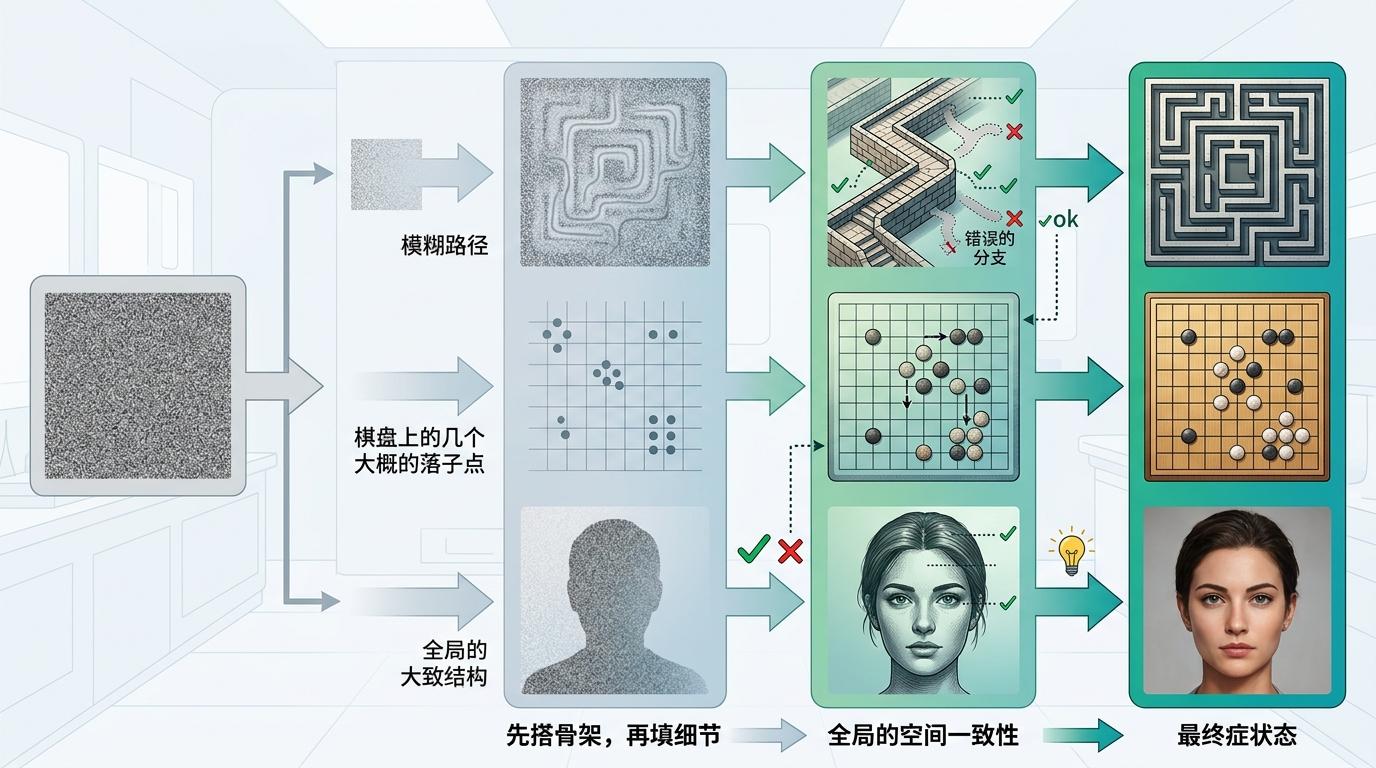
而自回归模型是“一笔一笔描”,像写字一样从左到右、从上到下生成像素,很容易陷入局部细节,忽略整体布局。比如画迷宫时,它可能画着画着就忘了起点在哪,最后画出的路径根本不连通。
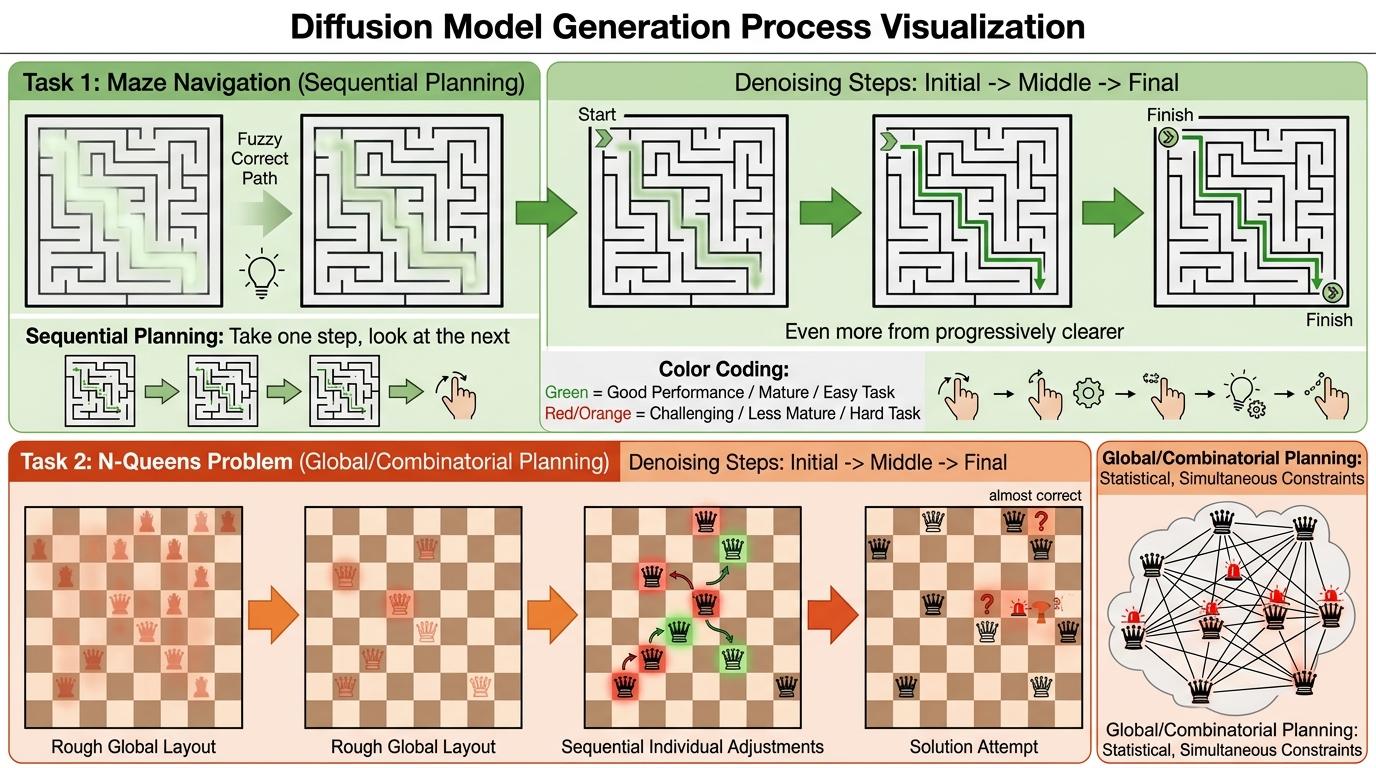
研究人员还可视化了扩散模型的生成过程:在迷宫任务里,正确路径早在去噪的前几步就以模糊形态出现,随着步骤推进逐渐清晰;皇后任务里,模型会先画一个粗糙的全局布局,再逐个调整落子位置。这种差异也对应了任务的本质:迷宫是“走一步看一步”的顺序规划,皇后是“全局统筹”的组合规划,而扩散模型在后者上的表现,明显还不够成熟。
为了看清AI和人类的差距,研究团队让微调后的Bagel和不同年龄段的人类做了对比。规则很公平:人类不能擦改,要像AI一样一次画完答案。
结果很有意思:在迷宫任务上,AI的表现和12岁孩子差不多;但在皇后任务上,它只相当于6岁孩子的水平。更关键的是,人类的成功率会随着思考时间变长显著提升,而AI就算给更多时间,提升也微乎其微——它不会像人类一样“边想边改”,只是在固定的能力边界里重复尝试。
AI的失败案例也很集中:要么是违反规则,比如迷宫穿墙、皇后同列;要么是只完成一半,比如画了半截迷宫路径,或者只放对了几个皇后。这说明AI还没学会“全局协调”,它能处理局部的视觉逻辑,但一旦涉及跨区域的约束,就容易顾此失彼。
这项研究最有价值的地方,不是证明了AI能解迷宫,而是把“视觉规划”从多模态理解里单独拎了出来——原来AI能“看懂”图像,和能“在图像里思考”,完全是两回事。
现在的AI,就像一个只会照着画的学生,能临摹出正确答案,但未必理解答案背后的逻辑。它能学会走见过的迷宫,却未必能应对没见过的新布局;能摆好固定规模的皇后,却未必能理解“全局不冲突”的核心约束。
**视觉规划的本质,是在空间里做决策。**人类靠直觉就能完成的事,AI还要走很长的路——这条路不是靠更大的模型、更多的数据就能走完的,而是要让AI真正学会“用眼睛思考”。