对抗知识焦虑,从看懂这条开始
App 下载
给AI装上火眼金睛,老视频终于能精准修复了
家庭录像|视频修复|字节跳动|北大|VQ-Jarvis|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载家庭录像|视频修复|字节跳动|北大|VQ-Jarvis|AI产业应用|人工智能
你手机里存的十年前的家庭录像,是不是暗得像蒙了层灰,满屏噪点还带着雨雾模糊?监控里拍到的关键画面,是不是总卡在“差一点看清”的边缘?过去AI修复这些视频,要么像只会一套拳法的老师傅,遇上混合退化直接失灵;要么像乱撞的无头苍蝇,把所有修复工具挨个试一遍,耗时又耗力。直到2026年3月,北大和字节跳动的团队拿出了VQ-Jarvis——这个能“看懂”视频毛病、还会“抄作业”的修复智能体,把复杂视频修复的效率和效果拉到了新高度。它到底是怎么做到的?
要让AI精准修复,首先得让它能“看”懂——到底哪部分是噪点,哪部分是雨雾,修复后的画面到底有没有变好。但过去的通用AI模型,在判断“A和B哪个修复得更好”时,准确率不到60%,跟瞎猜差不多。
VQ-Jarvis团队的解决办法是:专门建了个“视频修复题库”。这就是业界首个大规模视频配对增强数据集VSR-Compare,包含2万组视频对比对,覆盖了低光、雨雾、模糊等7种常见退化,还收录了11种主流修复工具的处理结果。为了给这些视频打“谁更好”的标签,他们先让GPT-4o、Gemini等多模态大模型当“初评委”,投票筛选出意见一致的样本,再请人类专家抽检把关,最后训练出了专属的“裁判模型”——它和人类判断的一致率高达93%,比通用大模型的78%精准太多。
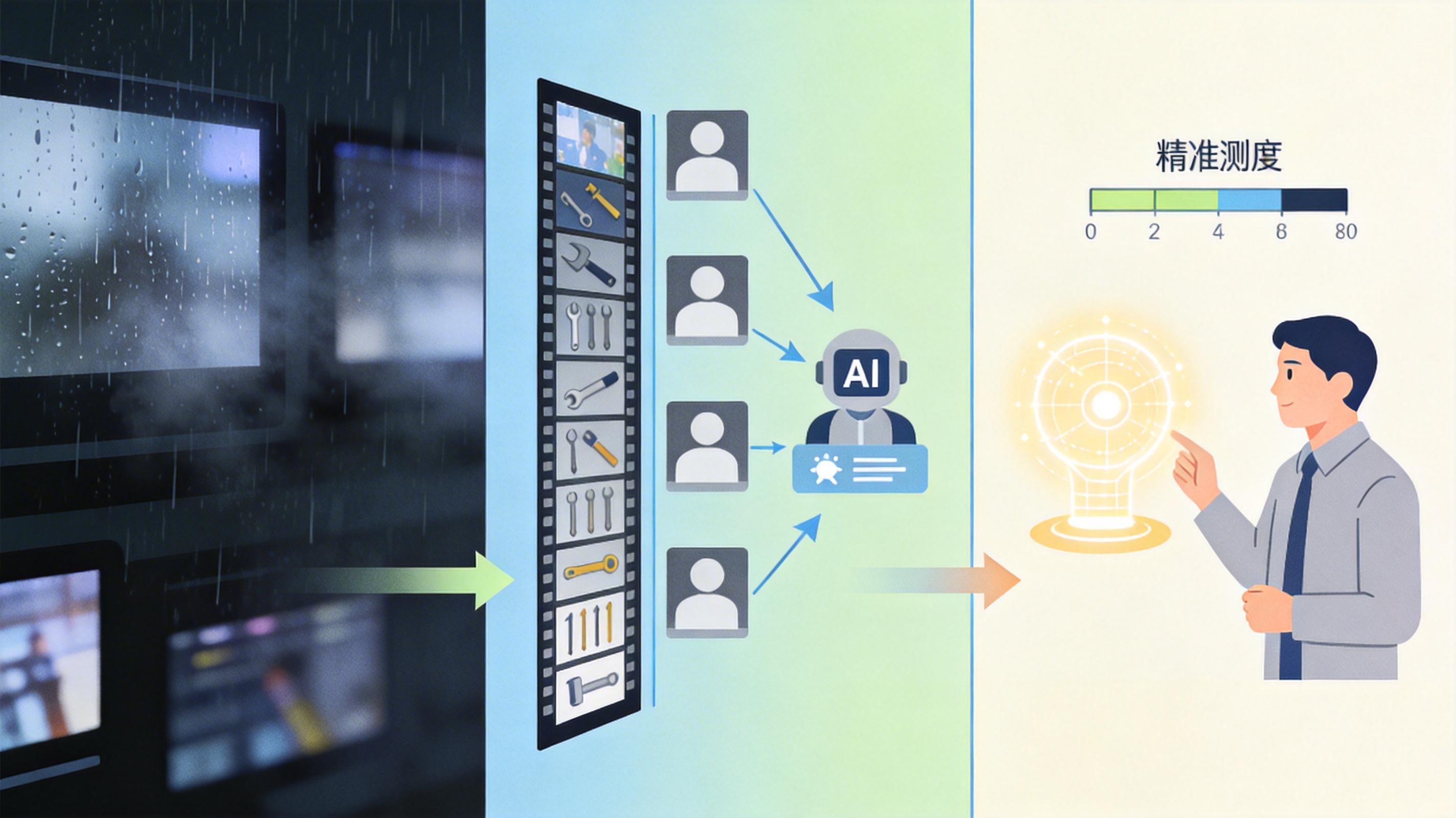
你可以把这个过程想象成:给AI请了个专业教练,用2万道针对性考题反复训练,终于把它从“分不清好坏的门外汉”练成了“一眼看透细节的修复专家”。
光有眼力还不够,AI得学会“高效干活”。过去修复复杂视频,AI往往要把所有修复工具的组合都试一遍,像穷举法解数学题,耗时极长。VQ-Jarvis则用上了“分层调度”的聪明办法:
如果视频只是轻度退化——比如有点模糊但光线还行,它就启动“抄作业”模式:从提前建好的“修复案例库”里,找出和当前视频退化情况最相似的案例,直接照搬现成的最优修复路径。这里的关键是,它比的不是视频内容像不像,而是“退化特征”像不像——比如都是“低光+轻微噪点”,不管是拍风景还是拍人脸,都能精准匹配。
要是遇上“低光+雨雾+模糊+低分辨率”这种地狱级难题,它就切换到“一步步解题”模式:先处理低光,再去雨雾,每一步都调用所有相关修复工具,让“裁判模型”选出当前最优结果,再用这个结果进行下一步修复。虽然比“抄作业”慢,但比穷举法效率高得多,还能保证修复质量。

这种模式像极了我们考试:简单题直接套模板,难题就拆解成小题一步步做,既不浪费时间,也不会在难题上卡壳。
当然,VQ-Jarvis也不是完美的。它的“逐步贪心搜索”模式,本质上是每一步选当前最好的选项,可能会陷入“局部最优”——比如某一步选了一个让当前画面看起来更好的工具,但却影响了后续修复的空间,最终错过全局最优的修复路径。
另外,它的计算成本依然不低,要同时运行感知模型、裁判模型和多个修复工具,目前还很难在移动端实时运行。更关键的是,它的核心数据集VSR-Compare还没有开源,其他研究者要复现这个成果,得自己花巨大成本去构建类似的数据集,这也给技术的普及设了一道门槛。
但不可否认的是,它给视频修复领域指了一条新路子:与其死磕一个全能修复模型,不如让AI学会“感知-判断-决策”的完整逻辑,把专用数据和高效策略结合起来。
当我们还在把AI当成“高级滤镜”时,VQ-Jarvis已经把AI变成了“会思考的修复师”。它不再是一个只会执行固定指令的工具,而是能根据具体问题灵活调整策略的智能体。
更值得关注的是,这种“检索增强+分层调度”的思路,不止能用于视频修复——从老照片修复到医学影像分析,任何需要“精准感知+高效决策”的视觉任务,都可能从中找到新解法。毕竟,AI的真正潜力,从来都不是模仿人类的技能,而是学会像人类一样思考:先看清问题,再选对方法,最后高效解决。
让AI先“看懂”,再“会做”,才是智能的开始。