对抗知识焦虑,从看懂这条开始
App 下载
AI不再单打独斗,组队交付完整项目
自动化项目交付|复古游戏编辑器|AI协作模式|Anthropic实验室|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动化项目交付|复古游戏编辑器|AI协作模式|Anthropic实验室|AI智能体|人工智能
一句话需求、6小时、200美元,没有产品经理、程序员和设计师,甚至人类没补过一行代码——一套能直接运行的复古游戏编辑器就这么做出来了。这不是科幻电影里的场景,是Anthropic实验室里真实发生的实验。过去我们总说AI编程像个灵光一闪但不靠谱的实习生,这次它却像个纪律严明的团队,从拆需求、写代码到测试返工,把任务从头到尾落地。为什么这次AI能摆脱「开头猛、中间乱、结尾垮」的老毛病?答案藏在一种全新的协作模式里。
你可以把单智能体AI想象成一个拿着超大笔记本的实习生——一开始记得快写得快,但任务一拉长,笔记本上的内容越堆越多,前面的需求要点被后面的代码片段盖住,逻辑主线慢慢被淹没,最后写出来的东西彻底跑偏。这就是AI界的「上下文腐烂」:当任务超过一定长度,模型的注意力会被冗余信息分散,把关键需求忘得一干二净。
Anthropic做过一个残酷的对照实验:单智能体模式下,AI用20分钟、9美元就做出了一个「像模像样」的游戏编辑器界面,但一上手就露馅——交互没打通,核心玩法直接失灵。而多智能体版本花了6小时、200美元,却交出了一个真能跑的成品。
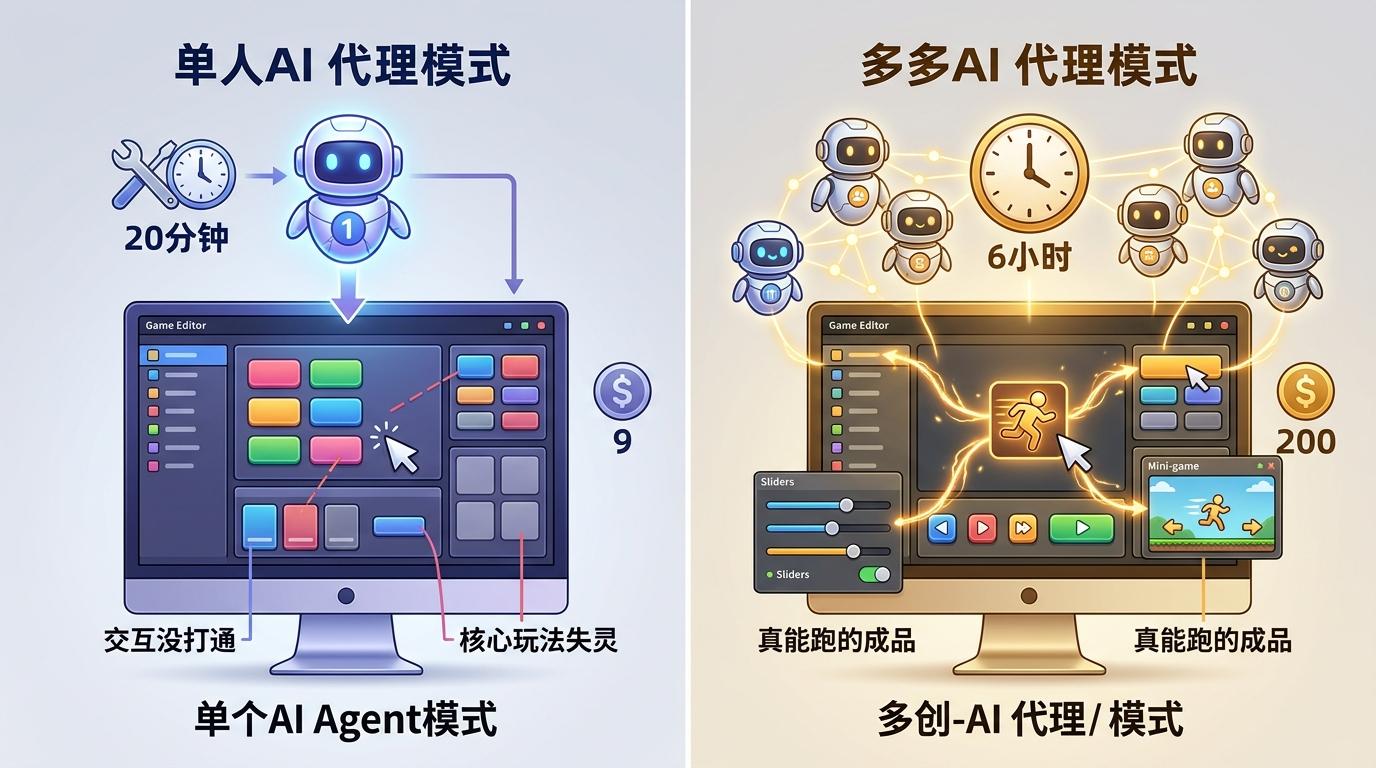
区别就在于,多智能体系统把一个AI拆成了三个角色:Planner(规划者)负责把模糊需求拆成16个功能、10个冲刺的详细规格书;Generator(生成者)负责写代码搭框架;Evaluator(评估者)专门挑错,从功能逻辑到设计质量,甚至把「原创性」的权重拉高,逼着系统跳出「安全答案」。
多智能体协作不是简单把几个AI凑在一起,而是模仿人类团队的协作逻辑,搭建了一套能自我迭代的闭环网络。
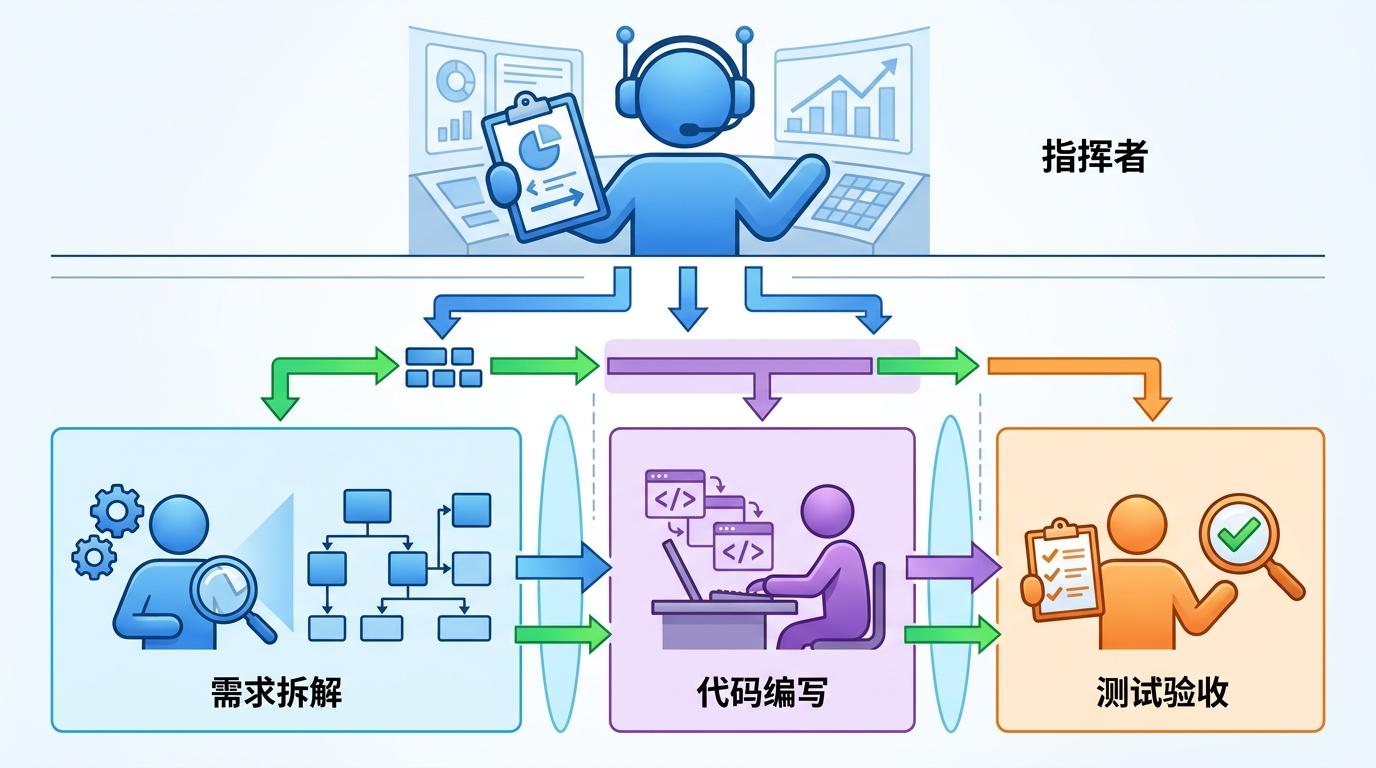
首先是「指挥官-执行者」的架构:Lead Agent(指挥者)像个项目经理,负责制定整体计划,把大任务拆成一个个子任务,再分配给不同的Subagent(执行者)。每个Subagent只专注自己的细分领域,比如有的专门处理需求拆解,有的专攻代码编写,有的负责测试验收。这样一来,每个智能体的上下文窗口只装自己的任务,不会被无关信息干扰,从根源上避免了「上下文腐烂」。
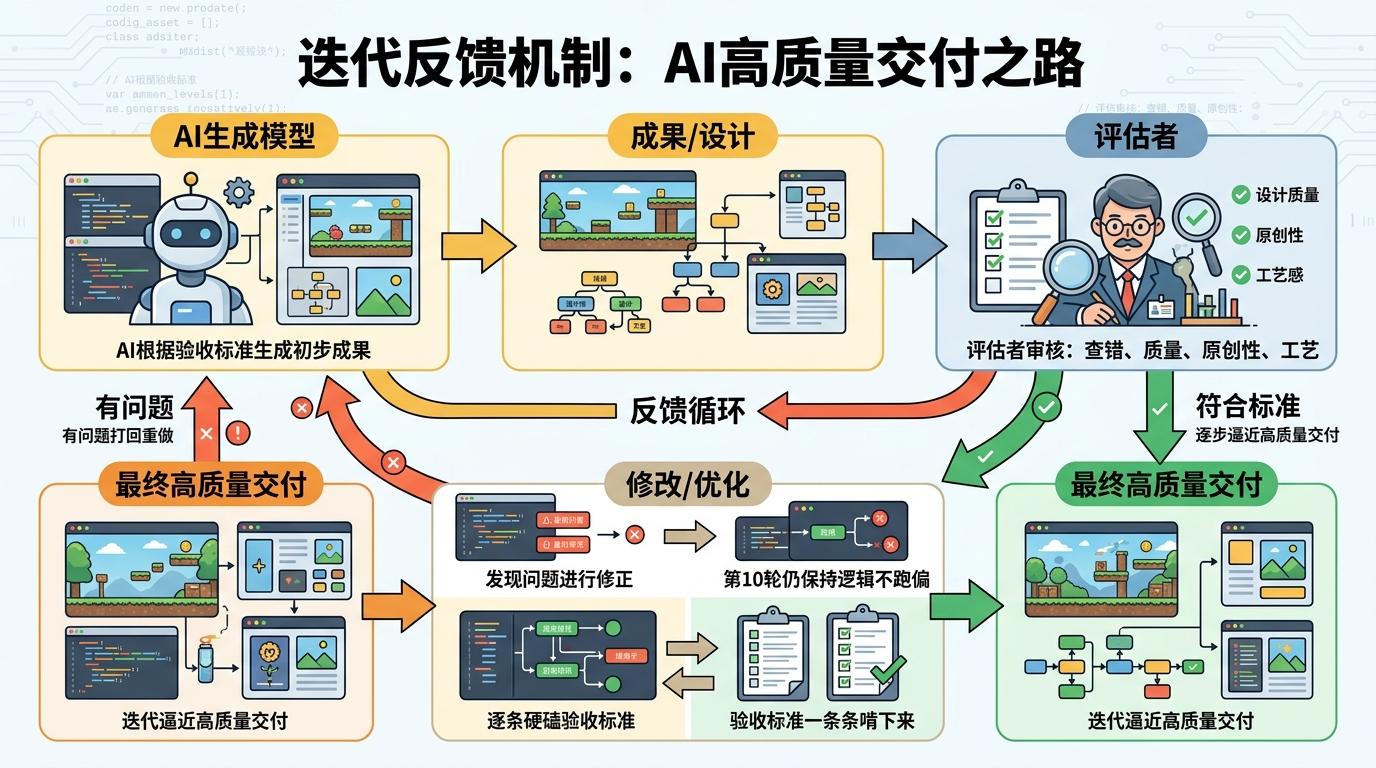
更关键的是「迭代反馈机制」。Evaluator(评估者)不只是查bug,还要盯着设计质量、原创性和工艺感,一旦发现问题就打回去重做。在复古游戏编辑器的实验里,AI硬生生把27条验收标准一条一条啃了下来,甚至在第10轮修改里还能保持逻辑不跑偏。这种「生成-评估-修改」的闭环,像人类团队里的「评审-返工」流程,逼着AI不断逼近高质量交付。
为了让协作更顺畅,开发者还做了很多细节优化:给每个智能体明确的任务边界和输出格式,用外部记忆保存长期计划防止信息丢失,甚至让智能体自己测试工具、优化提示词,减少重复错误。这些细节加起来,让AI团队的协作效率比单智能体提升了30%以上。
多智能体系统的崛起,正在悄悄改变人机协作的规则。过去我们比拼的是「谁更会用AI生成代码」,现在却变成了「谁更会给AI挑错」——你的评价能力,直接决定了AI最终能交出什么样的成果。
Anthropic的实验里,Evaluator(评估者)不仅查功能bug,还特意拉高了「原创性」和「设计质量」的权重,结果AI交出的游戏编辑器不是千篇一律的模板,而是有复古质感、能真正用起来的产品。这说明AI的创造力不是凭空来的,而是被高标准逼出来的。
但这也带来了新的挑战:AI生成的代码里,超过40%存在安全漏洞,比如输入验证缺失、硬编码密钥等问题。人类审查者很容易被AI的「流畅输出」误导,变成「橡皮图章」式的批准。所以未来的开发者,不能只会写代码,还要学会做AI的「评审专家」——既能看懂AI的逻辑,又能精准指出问题,甚至能设计出一套让AI自我迭代的规则。
更现实的问题是成本:多智能体系统消耗的token是单智能体的15倍左右,像复古游戏编辑器这样的项目要花200美元。这意味着它暂时只适合高价值、复杂的长程任务,比如企业级软件、复杂研究报告,而不是简单的代码片段生成。
当AI从「单打独斗」变成「组队协作」,它已经不只是一个代码生成工具,而是开始逼近完整的项目交付能力。这背后的本质,不是AI变聪明了,而是我们学会了用人类的协作逻辑,把AI的能力组织起来。
未来,真正稀缺的不再是写代码的能力,而是能提出好需求、能给AI做评审、能设计协作规则的人。就像Anthropic实验证明的那样:AI能交付的上限,取决于人类能设定的标准。
我们正站在一个新的转折点上——AI不再是人类的「助手」,而是变成了「团队成员」。如何和这个新成员好好合作,才是接下来最值得思考的问题。