对抗知识焦虑,从看懂这条开始
App 下载
AI一轮造出百倍活性蛋白,打破进化千年僵局
CRISPR工具|酶活性提升|蛋白质定向进化|Patrick D. Hsu团队|MULTI-evolve平台|分子细胞生物学|AIGC|生命科学|人工智能
对抗知识焦虑,从看懂这条开始
App 下载CRISPR工具|酶活性提升|蛋白质定向进化|Patrick D. Hsu团队|MULTI-evolve平台|分子细胞生物学|AIGC|生命科学|人工智能
想象一下:用了上千年的酶,有人只花一轮设计,就让它的活性翻了256倍;用来编辑RNA的CRISPR工具,被直接推高10倍效率;甚至治疗抗体能同时把产量提6倍、亲和力拉3倍。这不是科幻实验室的幻想——2026年2月,加州大学伯克利分校的Patrick D. Hsu团队在《Science》发表的MULTI-evolve平台,把蛋白质定向进化从“愚公移山”变成了“精准爆破”。但问题是,人类困在蛋白质的“星海”里几十年,这个AI平台到底是怎么撕开缺口的?
你可以把一个中等大小的蛋白质想象成一串几百个字符的密码,每个位置有20种可能的“字母”(氨基酸)。这串密码的组合数是20的几百次方——比整个宇宙的原子总数还多。这就是蛋白质工程的“组合爆炸”困境:传统定向进化靠随机突变加筛选,像在星海撒网,捞上几个有用的突变都要花几个月,更别说把多个有益突变精准组合。

后来的机器学习方法试图拓宽搜索范围,但要么得喂给模型几万条实验数据,要么设计出的多突变体根本合成不出来——就像算出了完美的建筑图纸,却找不到能搭出它的材料。Patrick D. Hsu团队的工程师们盯着这个僵局,突然想通了一件事:与其在星海里瞎找,不如先找对“导航图”,再造能直接抵达目的地的“飞船”。
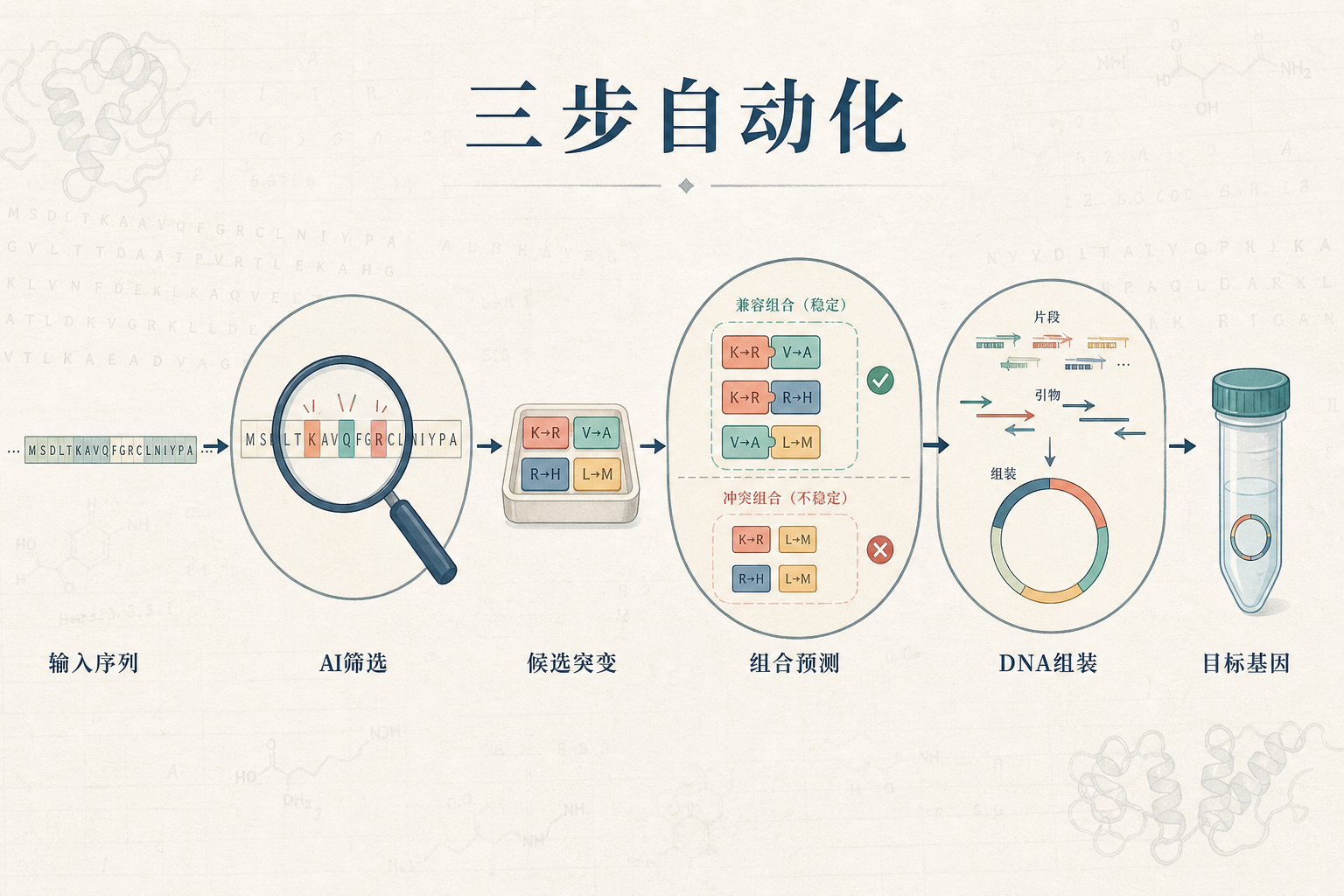
MULTI-evolve的核心,是把三个关键环节拧成了闭环:
首先是AI“导航”——用蛋白质语言模型筛选单点突变。你可以把这个模型理解成读了上亿本“蛋白质词典”的学霸,它能像懂中文语法一样,看懂氨基酸序列里的“搭配逻辑”:哪些位置换个氨基酸能提升活性,哪些位置动了就会彻底打乱结构。它不用靠海量实验数据喂,光靠学习自然蛋白的进化规律,就能精准挑出最有潜力的突变位点,把筛选空间从“星海”压缩到了“城市地图”。
然后是破解“协同密码”。蛋白质里的突变不是简单的1+1=2:有的突变单独用没用,和另一个突变组合起来就能让活性翻十倍;有的单独用很好,放一起反而会互相抵消。团队专门训练了一个神经网络,像分析朋友间的相处模式一样,预测突变之间的协同效应——哪些组合是“最佳拍档”,哪些是“冤家对头”,都能算得明明白白。
最后是“引擎”——MULTI-assembly合成技术。过去要合成含9个突变的基因,成功率可能不到10%,成本高得吓人。这个技术通过优化引物设计和拼接条件,把成功率拉到了40%-70%,几天就能造出目标基因,相当于给设计好的“超级蛋白质”配齐了能落地的身体。
更关键的是,这三个环节是全自动衔接的:AI筛选突变,预测组合,然后直接输出合成方案,不用人在中间反复调整。就像你在导航里输入目的地,它直接给你开去,不用你自己找路、修车。
当然,这个平台也不是完美的魔法。有其他实验室指出,它目前能精准捕捉的主要是3到4阶的突变协同,更高阶的复杂互作还难以预测;而且它的泛化能力还得靠更多不同类型的蛋白质数据来打磨——就像导航在大城市好用,到了偏远山区可能还会迷路。
但不可否认的是,MULTI-evolve把蛋白质工程的逻辑彻底换了:过去是“试错-筛选-再试错”,现在是“预测-设计-验证”。在APEX酶的测试里,它设计的7突变体,活性比野生型高了256倍——这要是用传统方法,可能要迭代十几轮,花上一两年。在抗CD122抗体的优化中,它同时实现了产量和亲和力的双提升,这在过去是要在两个目标里做取舍的难题。
最有意思的是,这个平台的代码和部分模型权重是公开的。这意味着不是只有顶尖实验室才能用它,普通的蛋白质工程师也能拿着这个工具,去优化自己需要的酶、抗体或者蛋白材料。
当我们谈论蛋白质工程的突破时,本质上是在谈论人类终于能从“模仿自然进化”,转向“指挥进化”。MULTI-evolve不是造出了什么超级蛋白质,而是给了人类一把能精准拨动蛋白质序列的“扳手”——不用再等自然花几百万年试错,我们能按自己的需求,快速造出想要的蛋白质。
未来的某一天,我们可能会用AI设计的酶把塑料分解成原料,用定制的抗体精准杀死癌细胞,甚至用全新的蛋白质搭建出自然界没有的材料。而这一切的起点,就是那个打破“组合爆炸”僵局的AI平台——它让我们知道,在蛋白质的星海里,人类终于不用再漂流,而是能扬帆远航。
用AI指挥进化,让蛋白质为人类所用