对抗知识焦虑,从看懂这条开始
App 下载
把B站收藏夹变成可对话的私人智库
关键帧提取|自动语音识别|结构化知识库|检索增强生成技术|B站收藏夹|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载关键帧提取|自动语音识别|结构化知识库|检索增强生成技术|B站收藏夹|多模态视觉|人工智能
打开你的B站收藏夹,里面大概率躺着几十个时长超半小时的知识视频——你曾怀着“有空就学”的决心点击收藏,后来它们的播放量就永远停在了0。直到现在,你终于不用对着灰色的播放键叹气:一个基于检索增强生成技术的工具,能把这些“吃灰”视频转成可随时对话的知识库。你不用再拖拽进度条找某个知识点,直接打字提问,它会精准给出答案,还附上对应的视频来源。
这背后的核心逻辑,是把多模态的视频内容“翻译”成AI能读懂的结构化知识。视频会先被拆成15秒左右的片段,通过降采样把每秒60帧压缩到4帧,再用结构相似度指标筛选出信息量最大的关键帧;音频则通过自动语音识别转成带时间戳的文本,和关键帧的视觉描述按时间轴对齐,融合成统一的文本块。这些文本块会被转换成语义向量,存入向量数据库,就像给每段知识都贴了精准的“语义标签”。
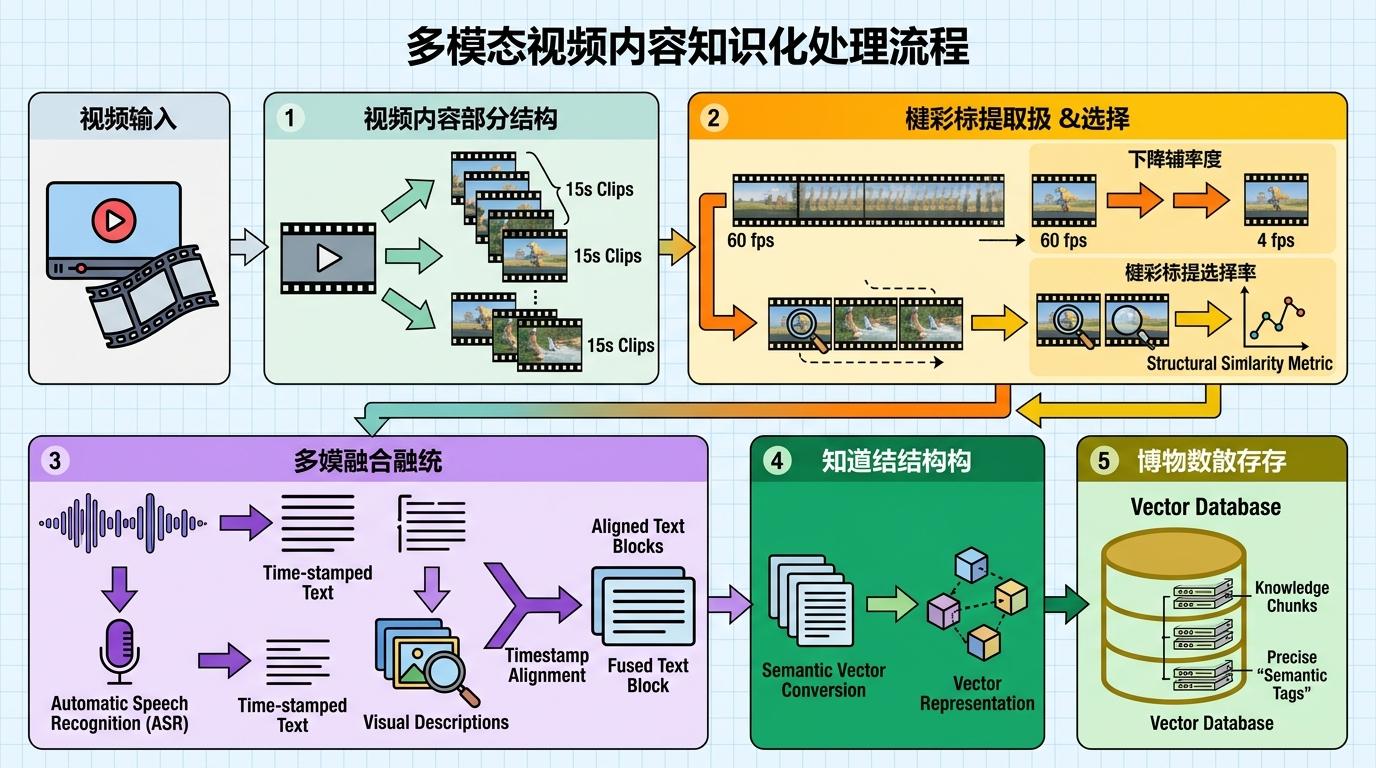
当你提问时,系统会先把问题转换成相同维度的向量,在数据库里快速定位语义最匹配的文本块——这就是检索增强生成技术的“检索”环节。随后,大语言模型会基于这些检索到的真实内容生成回答,而不是像普通AI那样依赖训练时的模糊记忆。这就从根源上减少了“幻觉”:如果数据库里没有相关内容,它会直接告诉你“不知道”,而不是编造答案。
当然,这项技术目前还有待完善。比如它对视频的类型有要求,更适合知识讲解、教程这类有明确信息点的内容,面对无字幕的纪录片或充满隐喻的艺术视频,关键帧的文本描述可能会丢失大量细节。另外,处理长视频的时间成本依然不低,一个两小时的讲座,从转写、融合到生成向量,可能需要十几分钟。
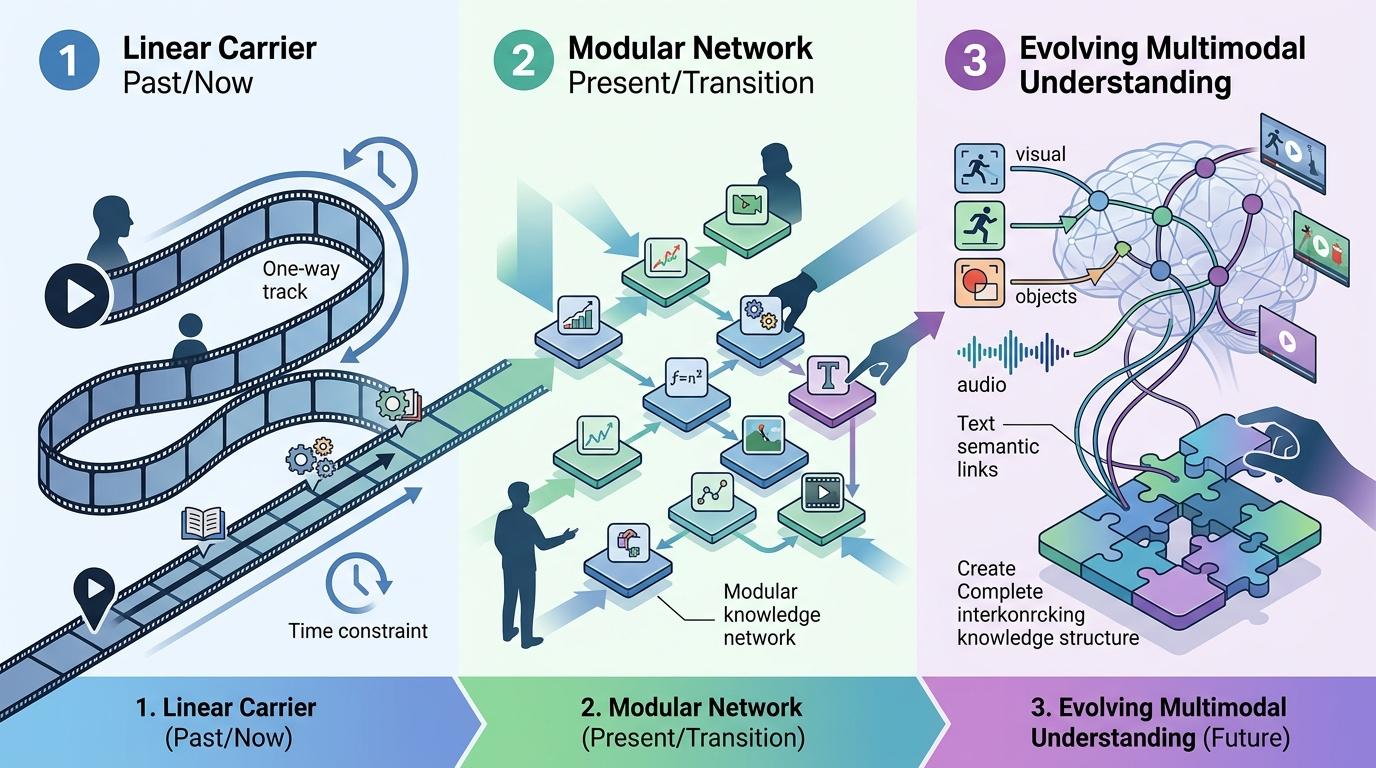
但不可否认的是,它正在重构我们和视频知识的关系。过去,视频是一种“线性”的知识载体——你必须从头到尾看,才能找到需要的信息;现在,它变成了“模块化”的知识网络,你可以直接提取任意节点的内容。未来,随着多模态模型的进化,它或许还能理解视频里的动作逻辑、画面细节,甚至能把不同视频里的相关知识点串联起来,帮你梳理出完整的知识体系。
那些你曾以为永远不会点开的收藏,终于有机会变成真正属于你的知识资产。毕竟,收藏的意义从来不是占有,而是让知识真正为你所用。